- nebula 版本:1.1.0
- 部署方式(分布式 / 单机 / Docker / DBaaS):分布式
- importer 版本:1.0.0
- 硬件信息
- 磁盘(SSD / HDD):HDD,8T
- CPU、内存信息:156G 24核 Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz
- 出问题的 使用csv importer 会出现部分数据导入失败的情况
- 问题的具体描述
部署情况
三台 graphd, metad, storaged
一台 graphd, storaged
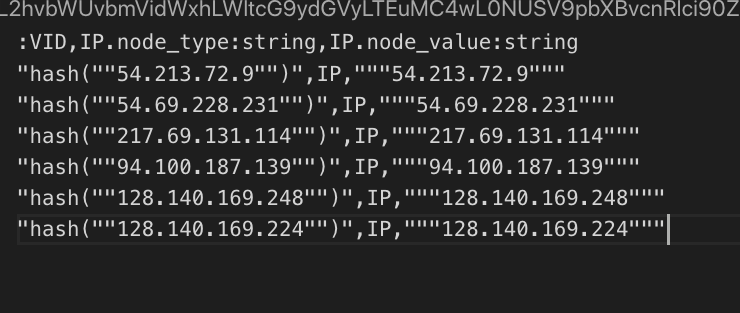
数据样例
使用了csv头导入
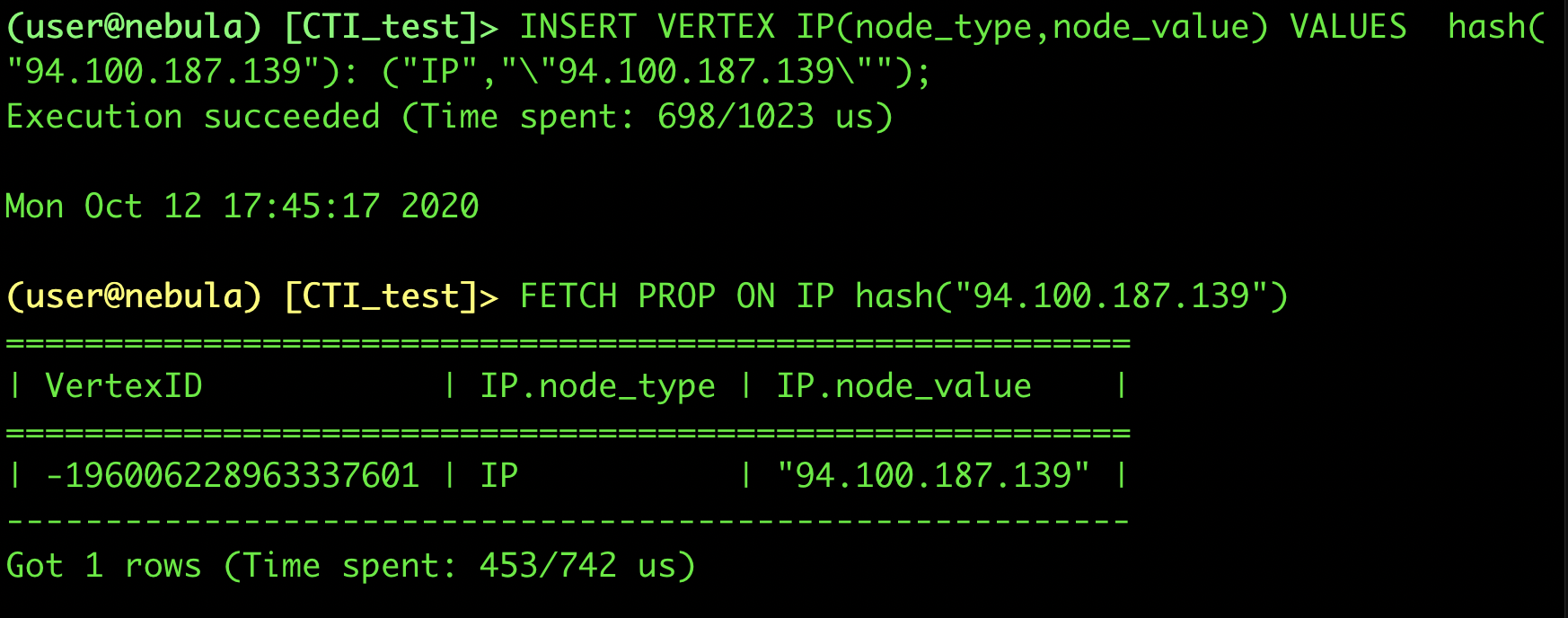
导入报错样例:
报错的语句直接在shell里运行
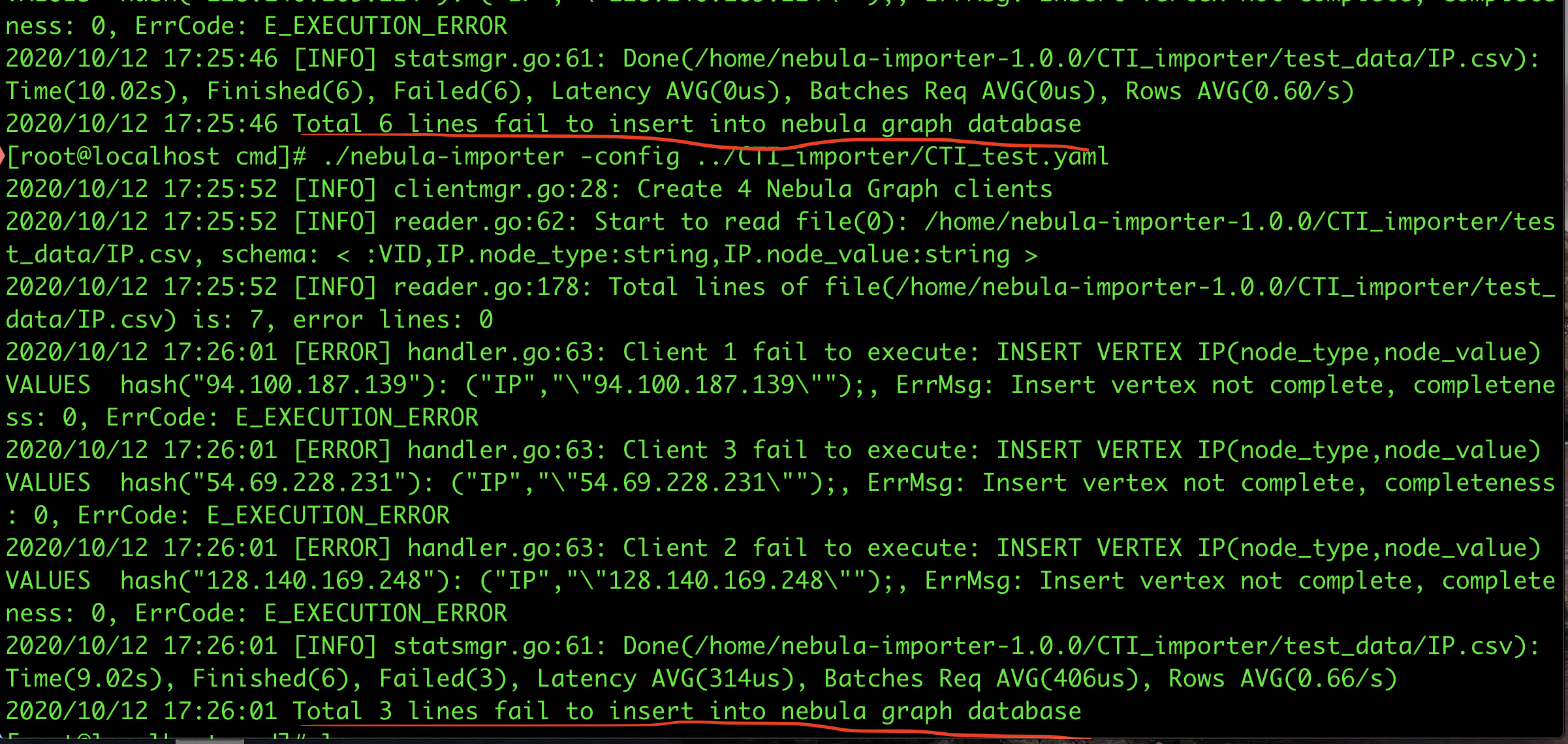
连续两次导入,配置文件和数据均相同,导入失败的记录条数不一样(一次全部失败,一次部分失败)
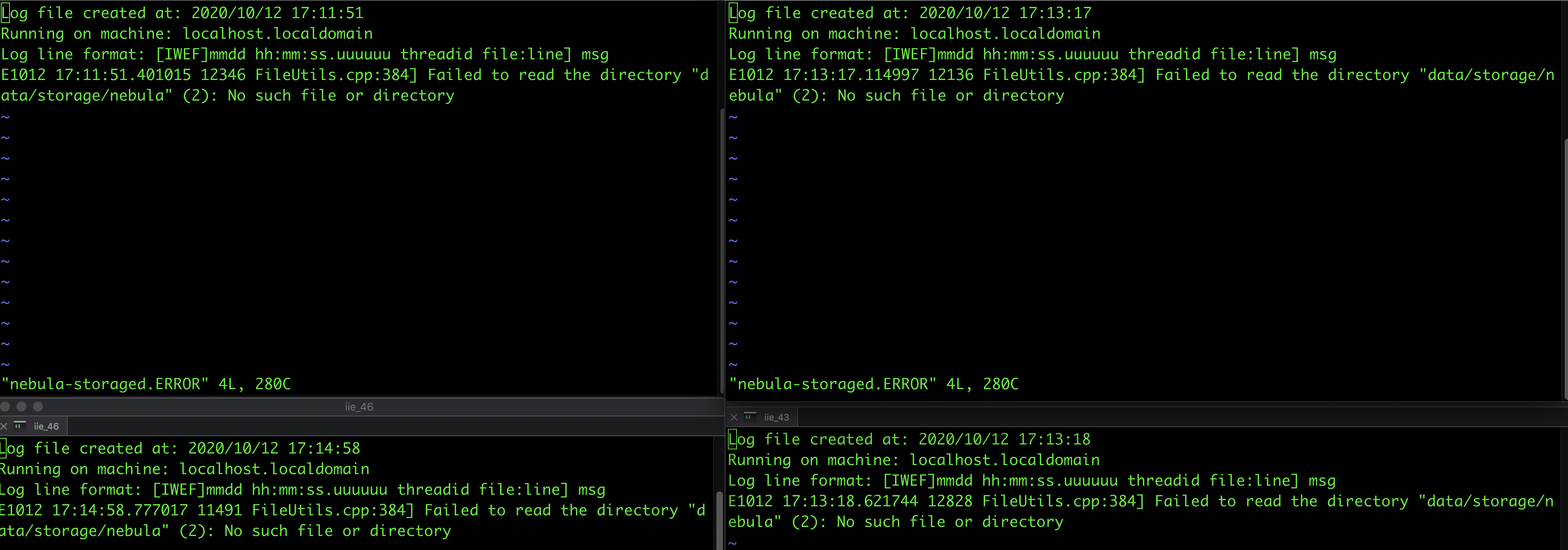
其中一个结点在启动storaged时会出现 metad 报错,不知道是否影响导入,删除cluster.id还是存在
都是/data/storage/nebula找不到,启动storaged进程的时候就会有,但是这个路径会自动创建对吧。不会影响我后续导入吧?毕竟命令行导入完全没问题
只有命令失败的报错,没有其他报错
E1012 18:31:06.962479 13793 ExecutionPlan.cpp:80] Execute failed: Insert vertex not complete, completeness: 0
我刚刚把另一个不包含meta的结点去掉了,产生了新的报错
在nebula-storaged.FATAL和nebula-metad.FATAL 都是下面这个
是多副本space么,如果是可能是leader信息的问题,再试一次就好了
之前说的不包含的meta的节点是四台机器中,三台是三个进程都全的,一台只有storage和graph。之前我配置的时候没注意只需要3个meta的限制,四台机器都开了meta进程。开始以为是这个问题,所以就索性去掉第四台机器,但实际还是不行。
utime的报错不知道和昨天时间服务器的错误有没有关系,我这里直接把集群重置了。但今天在单机测试的时候,停止服务会报这样的错误。日志文件都是响应端口无法通联,测试机器防火墙已经关闭
*** Aborted at 1602555599 (unix time) try “date -d @1602555599” if you are using GNU date ***
PC: @ 0x7f9dd9a4385d __GI_nanosleep
*** SIGTERM (@0x328d) received by PID 12723 (TID 0x7f9dda89b9c0) from PID 12941; stack trace: ***
@ 0x1cada21 (unknown)
@ 0x7f9dd9d5b62f (unknown)
@ 0x7f9dd9a4385d __GI_nanosleep
@ 0x7f9dd9a436f3 __sleep
@ 0xf912c8 initKV()
@ 0xf673a1 main
@ 0x7f9dd99a0554 __libc_start_main
饶了一大圈……问题终于找到了……
还是importer配置的问题
由于我是HDD和千兆网络,我按照
https://docs.nebula-graph.com.cn/manual-CN/3.build-develop-and-administration/3.configurations/0.system-requirement/
下的配置,在importer的yaml中选取了
batch size 50
concurrency 10
channelBufferSize 500
这样的参数,但是会出现本帖最开始无法插入的错误。
改成
batch size 2
concurrency: 2
channelBufferSize: 1
可以顺利跑完导入
经过多次参数调整,确定为
batch size 50
concurrency: 5
channelBufferSize: 1
是在官方推荐参数下的不出现导入错误的最优配置
concurrency,channelBufferSize 这两个只要增加1就会出现导入错误
2 个赞
min.wu
13
HDD下能有啥性能就完全不知道了,也没调优过。
不过你可以试着按手册改一下所有的参数,也许可以把压力并发调高。