导读 本文将分享多任务和多场景算法在推荐系统中的应用。主要从这4个方面来展开:
本次分享主要包括四部分内容:
1.多任务、多场景的背景和挑战
2.算法分类及应用分析
3.多场景、多任务领域的相关新工作
4.Q&A
分享嘉宾|王奕超 华为 高级工程师
编辑整理|段上雄
内容校对|李瑶
出品社区|DataFun
01 多任务、多场景的背景和挑战
首先来介绍一下华为多任务推荐的场景。
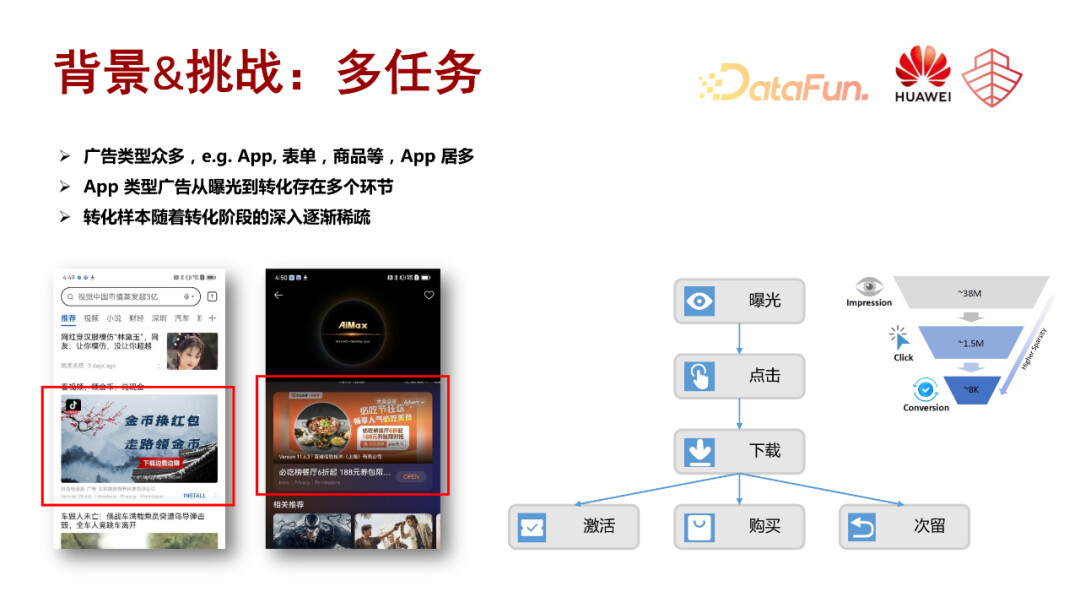
华为广告分布在不同的媒体上,比如左图展示的是浏览器信息流中的一个原声广告,右侧是华为视频页下方的一个广告卡片。这些广告分为不同的类型,比如 APP 类型、表单类型或者商品类型,其中 APP 类型是我们主要的一个广告类型。一个 APP 广告出现在用户的视野里,如果被用户注意到了,可能触发一个用户的点击进入详情页,如果用户看到了详情页信息之后,还进一步产生兴趣的话,就可能会产生进一步的下载行为,用户下载 APP 之后,用户可能会把这个 APP 放着不用了,也可能会产生进一步的转化行为,比如激活、应用内付费购买、次留等。
广告主会根据自己的一些运营指标,为某一次点击或者某一种转化的类型进行付费,因此我们会针对转化链路中的多个环节进行用户行为的预估,比如点击率、下载等转化率。显而易见,用户的转化行为会随着这条链路的逐渐深入而逐渐变得更加稀疏,越来越深层次的转化目标,其转化稀疏性问题就会越来越来越严重,训练起来的困难程度也会越来越高。
因此我们通过多任务联合建模的方式来缓解样本的稀疏性问题,同时也希望不同任务之间可以彼此协同提升。

华为广告投放的媒体类型众多,大致可以分为两类:
-
自有媒体:华为视频、华为浏览器、华为音乐、华为阅读等;
-
三方媒体,新浪、网易和 UC 浏览器等。
以华为自有媒体为例,华为广告可以投放在媒体内部的不同位置,以不同的形式展示,比如应用图标、开屏页等。当用户在不同媒体上的不同位置进行浏览的时候,会产生不同类型的行为,比如点击广告,而用户点击广告时所处的场景不同,产生点击的行为的背景也不一样,也就是说在不同的场景下我们可以提取用户不同的偏好行为。因此我们通过多场景联合建模的方案,来更加全面地构建用户的偏好特征。另外,多场景联合建模通常也可以带来另外两点好处:1)减少维护场景模型的数量;2)缓解冷启动场景的稀疏性问题。
02 算法分类及介绍
1. 多任务和多场景的对比
首先建模空间主要可以分为两部分,分别是目标空间和样本空间。多任务的目标空间是不同的,比如有点击率、激活率等,但是样本都是来自于同一个空间,比如相同的样本和特征空间。而多场景往往是相反的,其训练数据来自于不同的场景,样本空间也往往是不同的,会有着不同的数据分布和特征集合,但预测任务又都是同类型的,比如点击率。当然最近也有一些多场景和多任务联合优化的场景和算法,这里就不具体展开了。
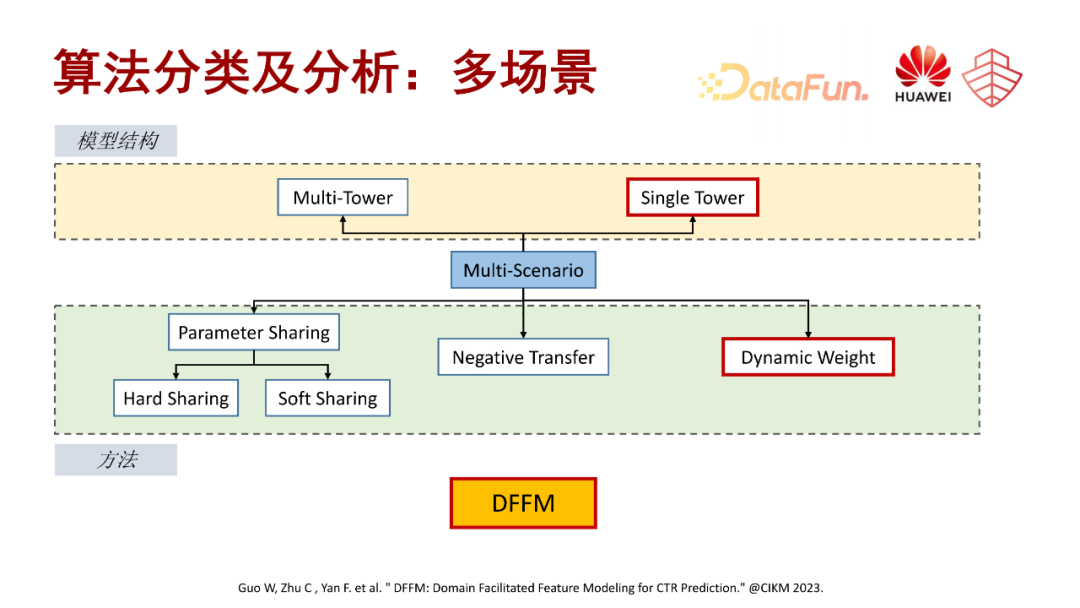
2. 算法分类
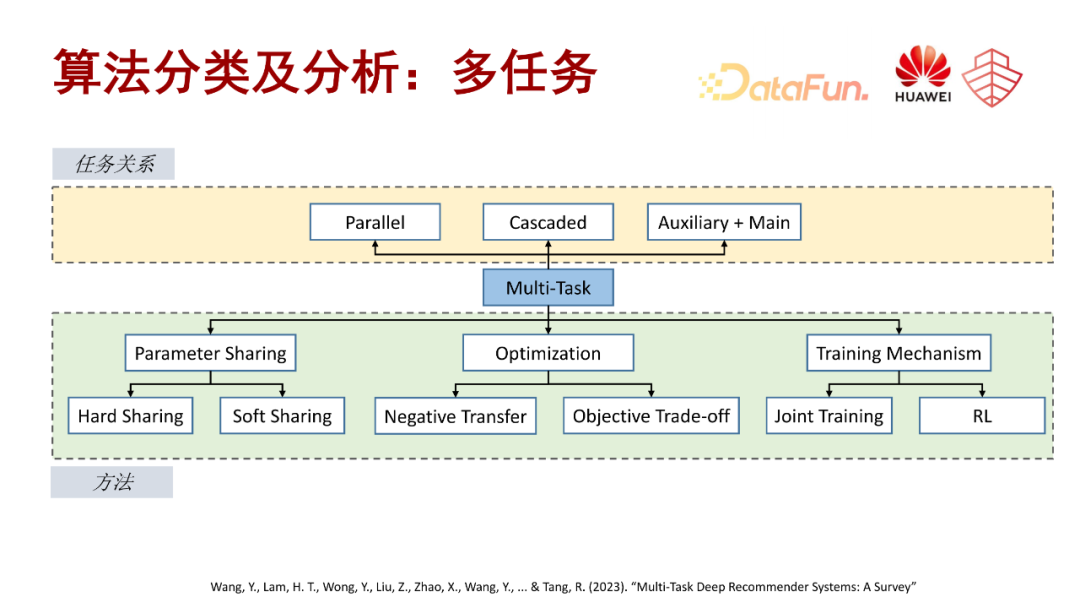
目前多任务推荐算法相关的工作,主要可以从两个维度进行划分:1)任务关系的维度;2)方法的维度。
任务关系维度主要分为三种,一种是平行式,也就是多个任务之间没有比较明确的依赖关系,比如点击、收藏、分享、喜欢等,这种多见于内容分发的信息流推荐场景。第二种是级联式,多任务的转化处于同一链路中,彼此之间存在着一定的依赖关系,这种多见于广告推荐场景。第三中是主任务加辅助任务的联合优化,主要是寻找一些辅助任务来优化主任务的最终效果。
从方法维度也主要分为三类。第一类是参数共享,包括 hard sharing 和 soft sharing,比如 MOE 结构。第二类是任务的优化,主要针对负向迁移以及多目标的权衡,再进一步又可分为任务或者梯度的主导问题,以及负向关系的处理问题。第三类是建模的训练机制,比如传统的联合建模的方式,就是多种任务一起直接联合优化。另外一种是基于强化学习的训练机制。下面这篇文章就是我们多任务推荐系统的 survey,里面会系统地介绍一些相关的工作,感兴趣的同学可以关注一下。

接下来我们对多场景相关的算法也做了一些不同维度的划分,主要是从两个维度,第一个是模型结构的维度,第二个是方法的维度。
从模型结构的维度分为两种,分别是多塔和单塔的结构。多塔就是为每一个场景会构建一个预测网络,一般这种是用在场景数量比较明确而且数量不是很多的情况下。另外一种是单塔,也就是所有场景的预测网络是共享的,多数是在场景数量不够明确,或者数量比较多的场景。在方法维度其实和多任务比较类似。第一个还是参数共享的方式,包括一些硬共享和软共享。第二个就是场景联合建模时负向信息迁移的一些处理。第三个是获取和调节场景特性信息的一些动态权重网络。我们也有一个联合建模的论文,介绍了多场景相关的一些工作,也包含了一些多行为多模态,还有大语言模型做推荐的一些联合建模的相关工作的介绍,感兴趣的同学也可以关注一下。
3. 算法介绍
接下来介绍华为广告场景落地的一些多任务和多场景的推荐算法。
( 1 )多任务算法: TAML
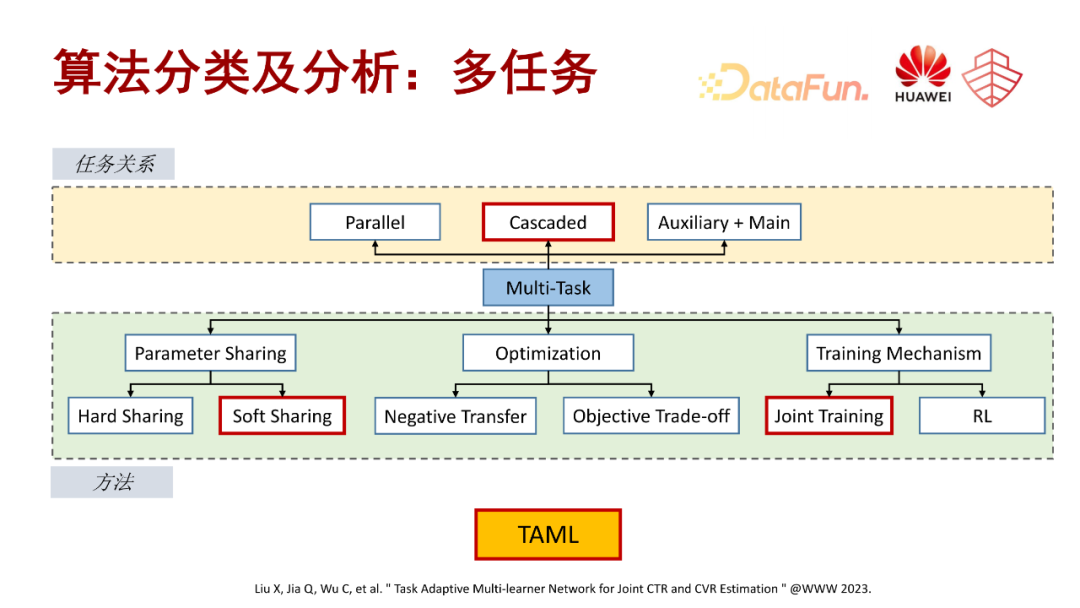
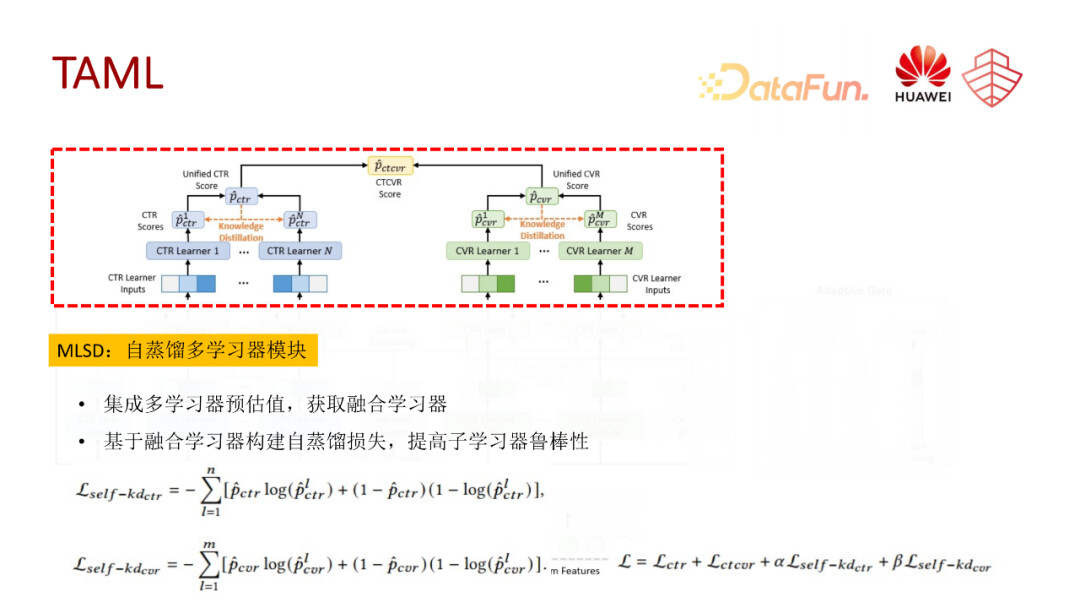
第一篇是我们发表在 www2023 的一篇工作(TAML),这个工作主要是覆盖分类中的级联任务,还有联合训练以及一些训练机制。
TAML 主要针对的挑战有两点,一点是转化样本稀疏,如果只是通过简单的任务级的专家网络融合,是无法提供足够信息的,而且这些信息会存在一些偏差。另外一点是模型预估的鲁棒性问题,我们表征以后的分类网络存在训练不够充分的问题,就会导致最终训练的预测结果不够鲁棒。

针对以上两个问题,TAML 的框架主要包括两个模块,一个是多层级任务自适应表征提取模块,主要是通过多层级的专家网络提取多粒度的多任务知识表征;第二个模块是蒸馏多学习器模块,主要是通过构建多学习器,并通过蒸馏实现多学习器之间的知识共享,提高预估网络的稳定性。

接下来对这两个模块分别做一些简单的介绍。
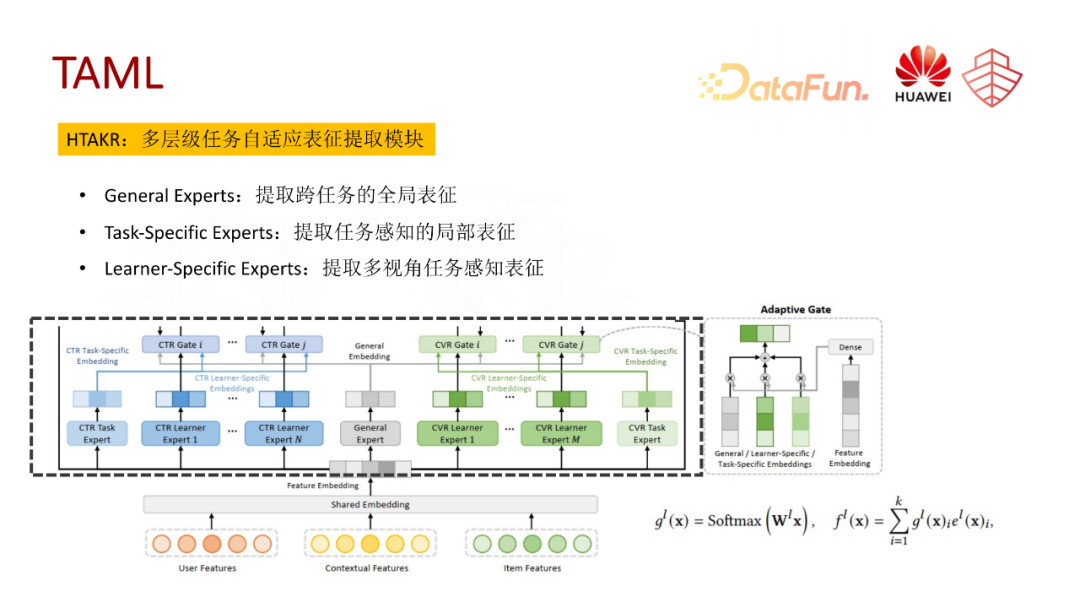
第一个模块,多层级任务自适应表征提取模块,主要是用于底层表征的抽取。通过三种多级专家网络来构建,一种是共享的多专家网络,另一种是任务级别的特有专家网络,还有学习器级别的专家网络。这里的学习器是为了缓解任务的稀疏性问题,并提高任务表征的稳定性,为每个任务又单独构建了多个学习器,就可以从多个视角提取任务表征。最终三个表征会通过一个门控网络进行融合,输出最终的表征。
第二个是 MLSD 学习器模块,主要用于预估网络的优化,多个学习器可以从不同的视角学习同一个任务不同的信息,最终我们会用不同的学习器的均值作为融合学习器的知识输出。在此基础之上,我们会构建一个正则化的损失,约束每个学习器和融合学习器之间的距离,从而实现不同学习器之间的信息共享,也以此来提高预估网络的鲁棒性。
我们这个工作分别在公开数据集和华为的私有数据上做了一些验证,相比 SOTA 都取得了比较显著的效果增益。另外,从下图中左下角的图可以看到不同层级的专家网络对最终表征的贡献度**,**在不同任务以及不同的学习器中,三种专家网络所提取出来的信息的重要性是有所不同的。比如,对于 CVR 任务,它学出来的学习器级别的参数网络的权重会更重一些。
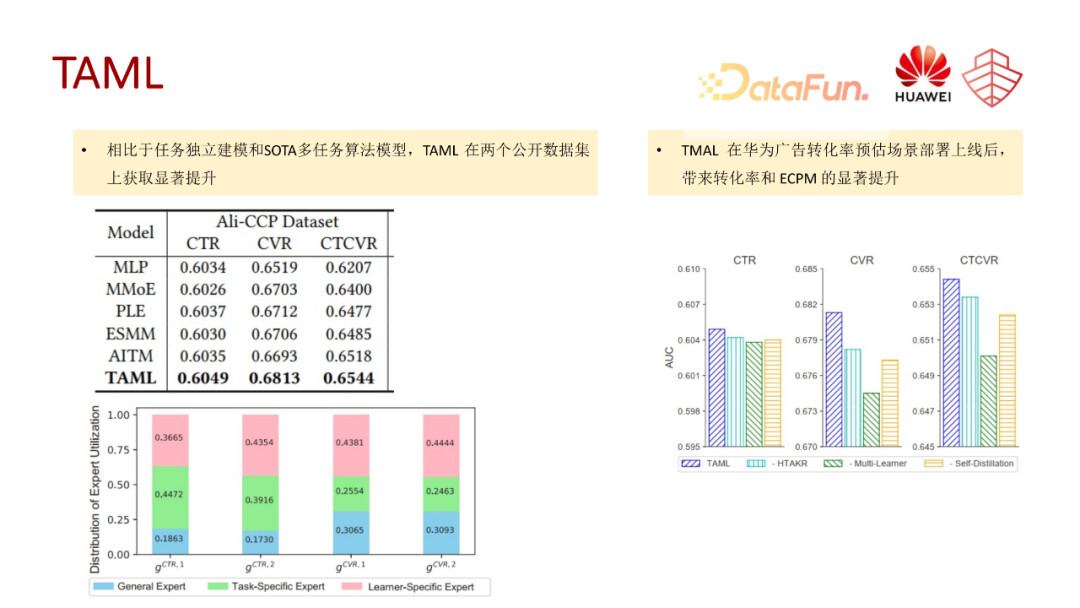
由于在离线的效果上比较好,所以我们在华为广告场景上进行了一个线上的AB实验。我们用基于点击后的数据构建了两个任务,一个是下载率,另一个就是激活率。可以看到在 CVR 和 eCPM 场景上,都取得了比较明显的线上收益。因为这是一个转化率的场景,所以我们更关注的是转化率的效果以及最终广告的收入效果。
( 2 )多场景算法: CausalInt
第二个工作是我们发表在 KDD2022 的一个工作(CausalInt),这个工作主要覆盖分类中多塔分类器以及软共享,还有包含了一些负向信息迁移的梳理,以及动态权重网络的场景自适应参数的调节。

这里我们借助了因果图来对多场景建模的问题进行了分析。首先我们从用户的视角对多场景推荐进行一个描述。在图(a)中,xn 是用户在场景 n 下的一个行为,yn 是用户在场景 n 下的一个操作,比如点击。x表示与场景无关的一些用户偏好,用户在场景n下产生的操作 yn 其实是受到用户在该场景下的一些行为,以及用户本身的一些偏好所共同作用的结果。

我们再从建模的视角来对多场景的建模过程进行一个描述,可以看出在场景数据混合在一起进行建模的时候,不同变量的关系就会变得更加复杂。
X1 表示的是与场景无关的用户表征,但是它受到了场景感知表征 Dn 和用户在场景 n 下的表征的一些影响,表示的是模型对于用户在场景下点击行为的预估,但是它受到了其他场景感知信息的影响,还有其他场景的比如用户行为的影响,在预估的时候存在一些偏差,并且无法取得比较好的推荐效果。也就是在建模的过程中,我们没有考虑到一些偏差信息以及有效的信息迁移。
为了实现建模过程的视图更和用户视图的因果图更加匹配,也就是解决建模中的偏差问题,我们提取出了多场景联合建模时的三个关键挑战。第一个挑战是如何有效的提取场景之间的共性。第二个挑战是如何保留产品中的一些特定信息,同时消除其他场景引入的一些负向信息,主要是处理如何有效提取 x n,第三个挑战就是如何探索并迁移场景感知的一些信息。
为了解决这些挑战,我们借助因果干预的策略。对这里的 Dn 对 Xn,还有 Xn 对 Yn 实施干预。在我们真实的商业推荐系统中,其实我们很难从数据的角度或者实验的角度来采取真实的干预策略,因此我们这里是考虑使用学习的方式来对这种干预进行一个模拟,切断容易产生混淆的因果路径。

我们提出了三个模块。第一个模块是共性提取模块,也就是红色部分。第二个模块是中间的负向影响去除模块,就是灰色的部分。第三个是场景信息的迁移模块,就是黄色的这一部分。接下来对这三部分内容分别做一个具体的介绍。
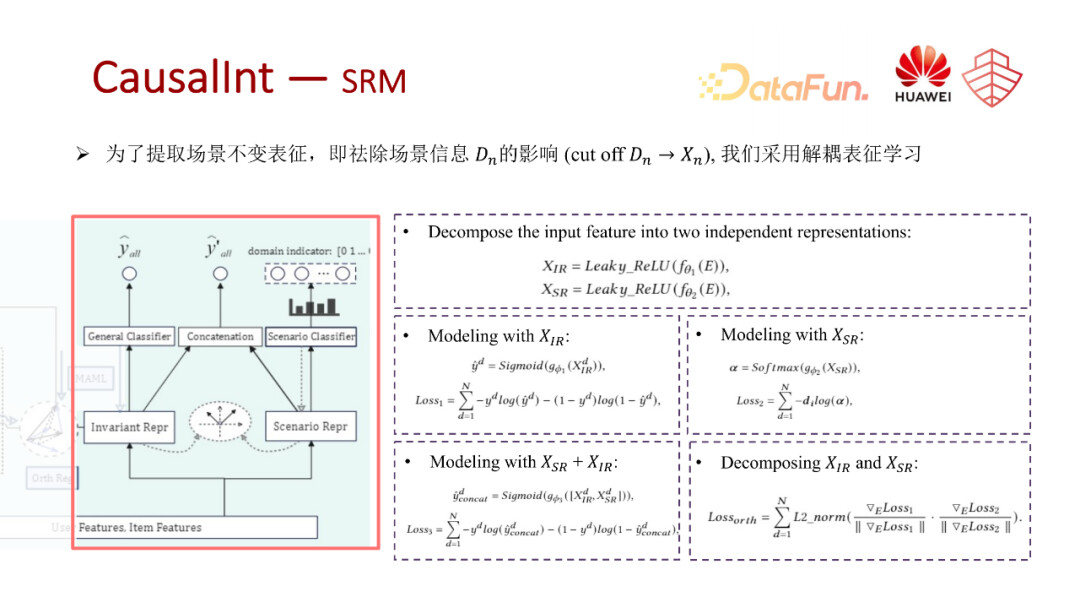
首先是共性提取模块。我们主要是通过结构表征的方式来把场景感知场景敏感的一些信息分离至独立的分支网络里,然后通过构建4个不同的任务来提取场景特有表征或者场景不变表征。这4个任务中的第一个是最左边的 general classifier,它主要是基于提取的场景无关的表征,剔除与场景敏感的一些信息后,所对应的一个统一分类器,也就是所有场景共享的一个 ctr 预估任务。第二个就是把场景敏感信息分离出来之后,用场景的敏感信息的表征去构建一个场景的判别器,也就是判别样本是来自于哪个场景。第三个任务就是将场景表征和场景感知表征联合在一起,再去构建一个ctr预估的 general classifier。最终为了有效地提取这两个表征,并且让这两个表征做到尽量的正交,这里会有真正一个正则化的约束。通过这4种方式,进行无偏表征的提取,作为后续建模的基础。
第二个模块是负向影响去除模块。可以进一步划分为两部分,第一部分是场景特有的一些表征以及场景共有的一些表征之间的梯度冲突问题。比如场景的特有的分类器和回传的梯度,还有共有的分类器回传梯度,对于共享表征的一些冲突问题。
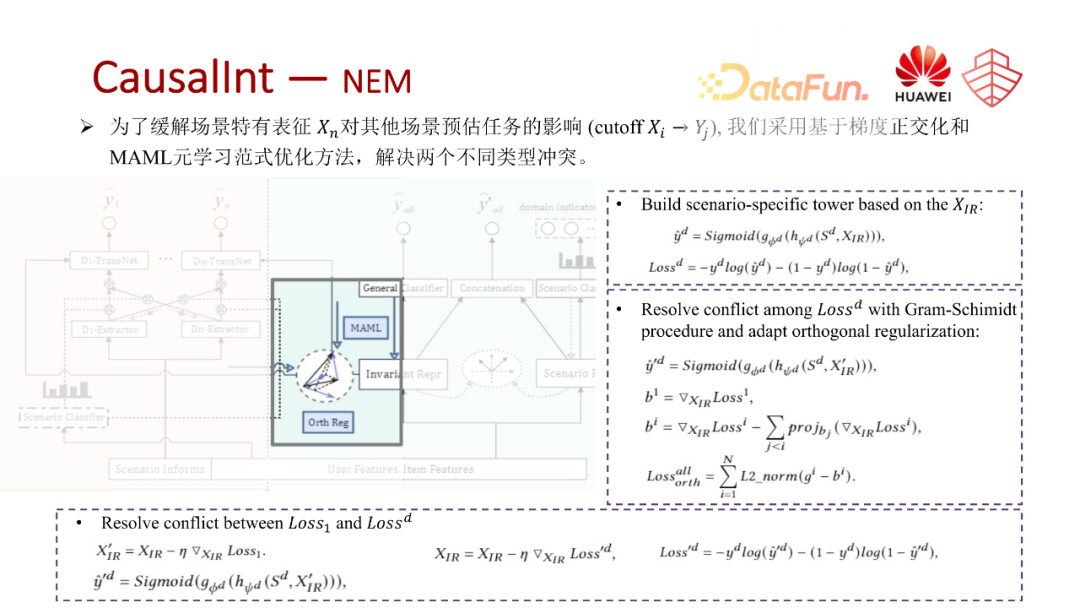
第二个冲突就是不同的场景自有的一些分类器所回传的梯度对于共有表征的一些影响。我们针对这两个不同的冲突使用了两种不同的策略。针对于第一种冲突,我们使用了 meta-learning 的 MAML 训练方式来解决场景特性表征和共性表征之间的冲突问题。针对第二种冲突,自有的共享表征之间的梯度冲突问题是采用一个施密特正交化的过程,然后实现一个梯度的正交基,来约束他们之间的一个梯度方向,从而解决这个维度的梯度冲突问题。
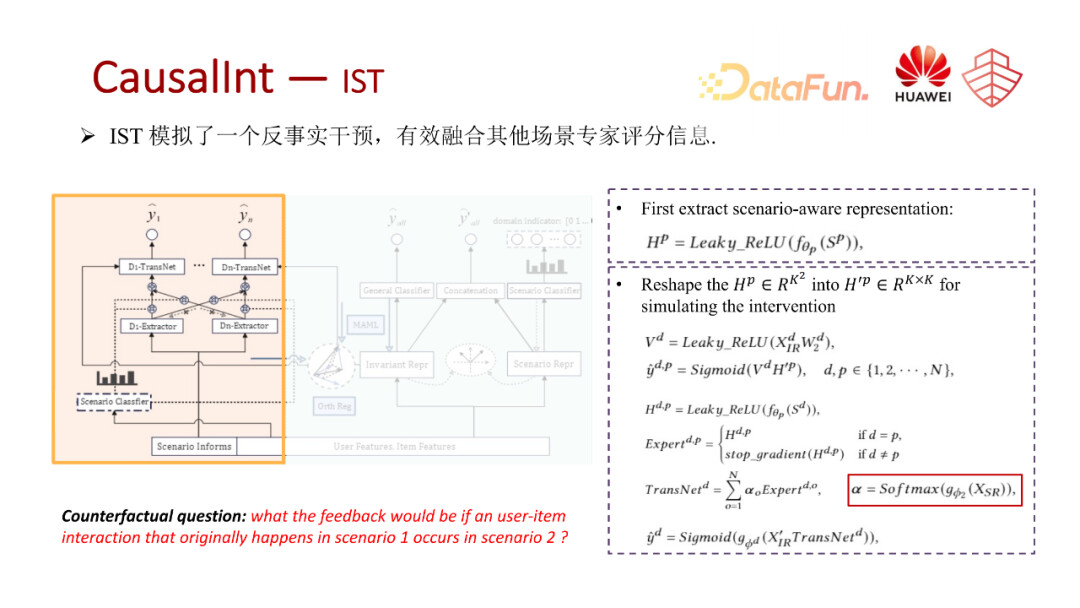
第三个模块是信息迁移模块。这个部分模拟了实验的干预策略,让单个场景中出现的 user-item 表征分别和不同场景的信息进行一个交互。
我们模拟的是如果场景的 user- item 交互出现的场景j中,它会有一个什么样的结果,这样一个反事实的问题,并将多个场景的评分网络,作为多个专家,对这一个交互进行打分。 最终会用第一个模块学习到这个场景的表征所对应的场景的分类器,对当前样本进行一个加权,也就是预测有多大的概率去相信当前这个场景所对应专家的一个打分结果,从而实现专家网络输出的分数的融合,从而实现不同场景之间的信息迁移。
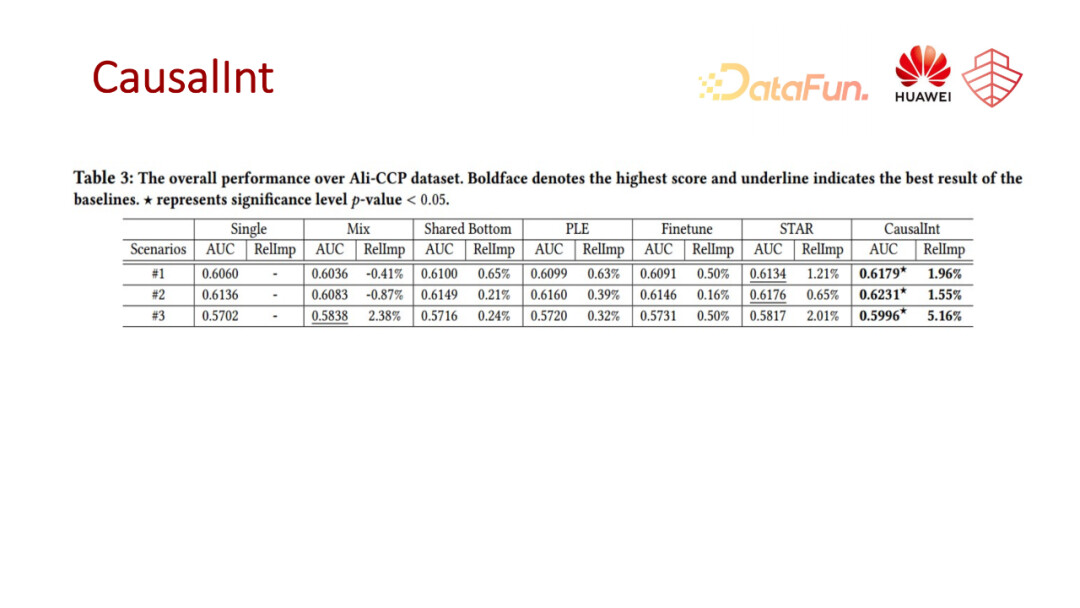
我们把模型在一份公开数据集和华为私有数据集上做了一些离线的 AB 实验,可以看到相比于单场景建模多任务模型,还有一些迁移学习的微调模型,包括多场景的一些基线模型,相对来说都会有比较明显的效果增益。
我们对模型的各个模块进行了一些消融分析。整体上看,各个子模块都带来了一些效果上的增量。比如表8中,我们进行了场景信息迁移模块中不同注意力网络的实现方式的对比,比如直接做 multiply、或者直接用 mmoe 类似的这种端到端训练做一个 gate 网络去做多专家分数的融合,可以看到,还是我们通过构建判别模型训练出来的 gate 网络的效果会更好一些。

( 3 )多场景算法: DFFM
接下来第三个要介绍的是我们发表在今年 CIKM 的一个工作,叫 DFFM,这块工作主要是面向单塔的多场景建模模型,利用动态权重网络,对特征交互还有用户行为进行场景自适应的学习。
特征交互和用户行为,做推荐的同学应该都比较了解,是 CTR 模型中很重要的两个概念。

特征交互是很多深度推荐学模型的基础,比如我们通常会通过手动的方式或者设计神经网络的方式来实现二阶、三阶的交互构建,或者直接通过MLP构建更高阶的隐式交互。
用户在不同场景下会产生不同的行为,体现在特征交互上,会根据场景而有所差异,也就是说不同的特征交互在不同场景上应该会有不同的权重。其次,用户行为可以反馈出用户的一些兴趣,用户在不同场景下产生的历史行为反映出用户在当时场景下的一些特定偏好,因此我们在多场景联合建模的时候也应该考虑这两点,即多场景下的共性和特性。
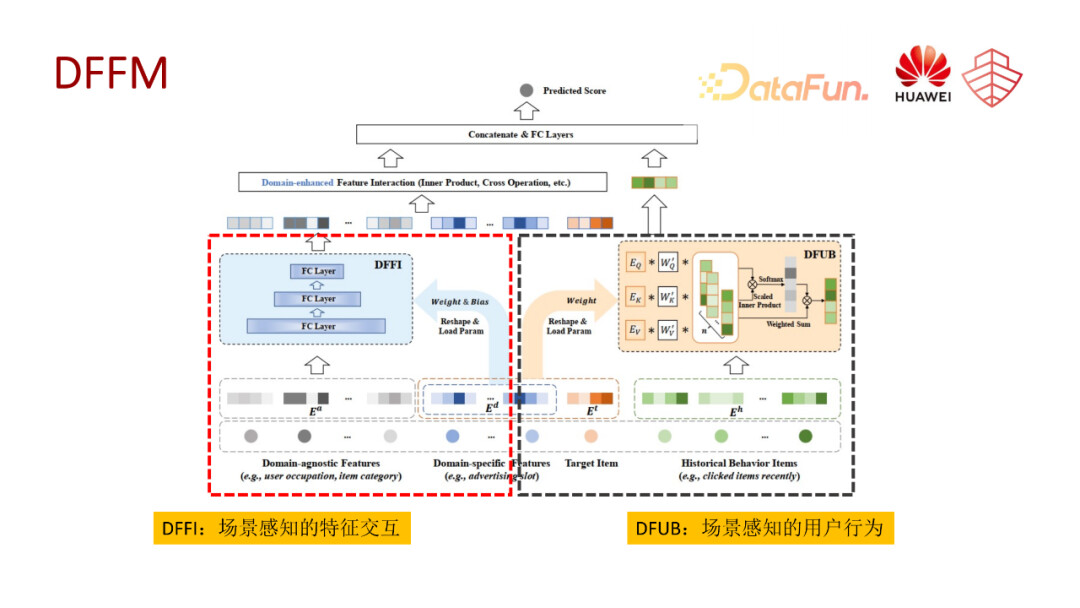
因此我们提出了一个面向特征交互以及用户行为场景感知的建模模型 DFFM。它主要包含两个模块。第一个 DFFI,是场景感知的特征交互模块,第二个 DFUB,是场景感知的用户行为模块。

场景感知的特征交互模块以内积的交互方式为例,在不区分场景条件下,其实交互方式就是为两个特征向量直接做内积,在多场景下,我们会使用一些场景的表征,比如 domain id,然后把这种场景表征进行一个转化和拆分,成立一个动态权重的网络,对原始特征进行一个转化。比如就是一个场景表征,通过转化和拆分,把它分解成一个权重网络和偏置,然后以此来对我们的一些原始特征,比如这里的 ei 和 ej 做一个转化,在此基础之上再进行二阶或者多阶的特征交互,最终和原始的向量 concat 到一起,获得 DFFI 模块的一个输出表征。这里交互方式肯定是不局限于内积,也可以是外积或者是 DCN、autint 的一些交互方式。

第二个模块,场景感知的用户行为模块。我们从用户行为的粒度入手,利用场景相关的特征学习用户行为之间的关联,具体而言就是 DFUB 模块使用的是多头自注意力机制来处理用户行为序列。相比于传统的多头自注意力机制只考虑序列内部的一些 item 交互,我们将 target item 和场景的表征都同时考虑进来构建多头注意力网络的 q-k-v 矩阵。它的转换矩阵分为两部分,一部分是它自身随机初始化的一个旋转矩阵,另一个就是由 target item 转化而来的一个旋转矩阵。通过这种方式,我们将 target item 和场景的信息,包含进注意力机制的 item 之间的交互中,最终多头的输出会 concat 到一起,作为 DFUB 模块最终的表征输出。
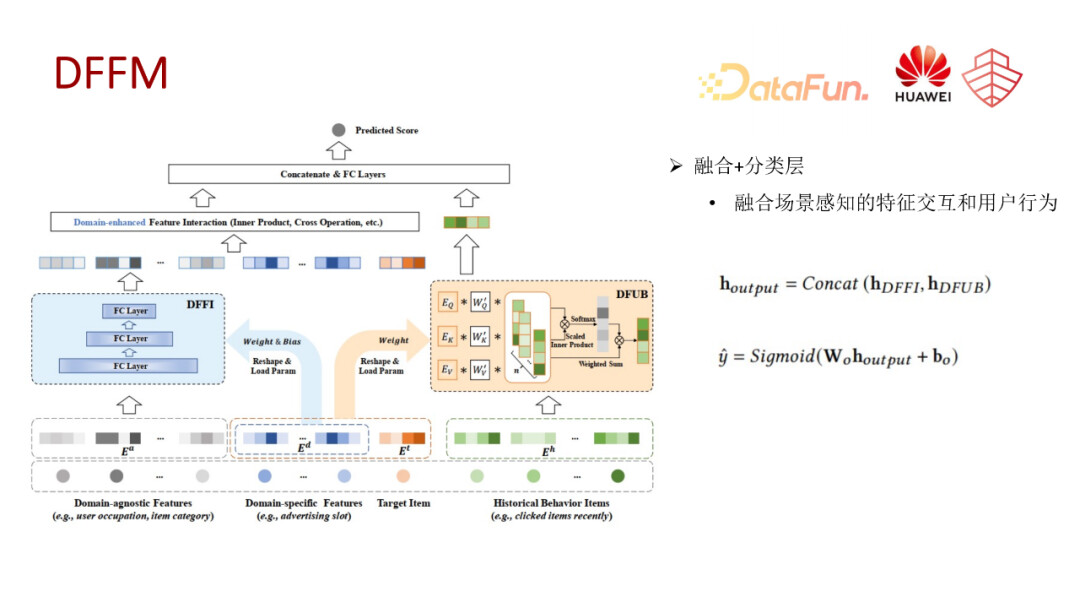
最终我们会综合 DFFI 和 DFUB 两个模块的表征构建一个分类器,这个分类器可以是一个简单的 MLP,或者其他更高级的一些分类网络,还可以再叠加一些交互网络。
这里展示了 DFFM 在两份公开数据上的一些离线效果评估,可以看到其相对于已有的一些 SOTA 模型,可以带来比较明显的效果增益。

同时我们把这个模型在三方媒体的场景上去做了落地,因为它的场景数量相对来说比较多,而且不是很确定,我们这里使用了一个单塔的模型进行上线和验证。可以看到逐步上线了 DFFI 模块以及完整的 DFFM 模块,效果上都是有着比较明显的增益,这里展示的是 ecpm 收益。
03 相关工作
最后,我们整理了近期发表的一些多场景和多任务方面的工作。

前两个是多任务方面的,第一个就是 TAML,基于多粒度的专家网络和级联学习的多任务优化;第二个是面向多任务的特征选择框架。
下面五篇主要面向的是多场景建模,比如 DFFM 面向特征层面,主要包括一些特征的交互和用户行为的建模;HAMUR 是面向交互网络的场景适配器网络;Instance 主要是面向样本层面的,也就是多场景中的样本选择算法;刚才介绍的 CausalInt,主要是面向多场景的训练框架,着重解决负向信息的迁移问题;PLATE 是一个基于提示学习的迁移学习的新范式。
最后两个是做多任务学习的联合训练。综合了多任务、多场景,多模态、多行为、多兴趣,以及语言模型辅助推荐系统去做推荐的联合建模方案。
以上就是本次分享的内容,谢谢大家。
04 问答环节
Q1: 模型离线全量训练的时候,比如用90天样本,实验要比 base 好,但模型天级增量更新时实验比 base 的效果变差了,了解一下可能是哪些原因?
A1:主要是工程和算法的影响,工程上增量训练依赖实时特征获取以及实时样本回流,主要涉及到样本的准确性;算法层面上,增量更新时,也会有一些策略影响模型更新的效果,比如学习率,样本从一个 batch size 到一个小批量的增量训练,学习率通常需要做一些调整,比如衰减或者更小的量级。然后是特征的准入和淘汰上也会影响模型效果。然后不同的算法在增量训练过程中会有不同的策略,比如蒸馏模型的滚动蒸馏,这些也都会影响模型效果,具体问题需要具体排查了。
Q2: 多任务学习中有没有一个额外的学习信号?就是通过什么方式来让这三种不同类型的专家学到不同的知识?
A2: 现在很多包括我们像 MMOE,还有 PLE 这些基于多专家网络,然后加上稀疏性门控网络的这种模型,其实都会采用这种方式非常隐式的方式去学习他们权重之间的一个分布。一点是参数的初始化方式和随机种子。第二点是专家权重网络的输出上增加一些扰动,扰动可以岁训练过程逐渐减少。
Q3: 主场景可能样本比较多,可能会支配整个学习过程,有没有试过多个场景做一个自适应的规划,就类似阿里 star 模型,类似的一些方式有没有用过?
A3: 其实我们之前和他们作者有过一些交流,就是这种方式可能在同一个 batch 内,如果是有不同的场景的数据,特别是场景数据比较多,然后你 batch 又比较小,这种情况下效果其实不是特别好。但是如果是像阿里这边直接使用那种交替式训练,比如说一个 batch 只有一个场景的数据,其实还是有一定的效果的。针对于这个之支配参数,其实刚才有介绍过一个梯度主导的问题,其实这篇这块也有一些工作,然后我们其实之前也尝试过,其实一个最简单方法就是类似于 grandnorm,直接从梯度的量纲去做一对梯度做一些惩罚,对梯度大的,根据训练的 step 去调节当前这个任务所对应 loss 的权重。
以上就是本次分享的内容,谢谢大家。