Nebula 与 Neo4j、ArangoDB 等图数据库的 Benchmark
本文出品自:苏宁智能监控与运维产研中心算法 Lab
苏宁线上的电商系统以及基础设施随着时间推移日益复杂,随着大规模的异常检测的落地以及结合传统基于规则的告警,我们迫切需要有效的告警收敛机制,而如何发现根告警(Root Alarm)变得更为紧迫。
通过构建运维和告警双重知识图谱能够有效解决这样的挑战。而知识图谱的核心是图,选择分布式图数据库是一项非常严谨的工作,我们选择了业界比较流行的两个图数据库与 Nebula 进行了对比和评测。
1. 评测对象
-
Nebula Graph:版本 1.1
-
Neo4j: Neo4j 是目前业界广泛使用的图数据库,有社区版本和商用版本,我们使用社区版本,社区版本不支持集群。
-
ArangoDB: ArangoDB 是一个开源的多模态数据库,可用来存储文档,图等类型的数据。支持集群,具有良好的读写性能。
2. 测试数据集
测试数据使用的是 GitHub - weinberger/nosql-tests: NoSQL benchmark tests for documents and graphs 中的测试数据。
数据总共包含 1632803 点,30622564 边。其中,Onehop 查询平均一个节点有 18 个邻居;Twohop 查询平均一个节点有 800 个邻居。
3. 测试环境
机器配置:
- CPU:16c
- 内存:128G
- 磁盘:2400G
Neo4j 只测试单机,Nebula 和 ArangoDB 分别测试了单机和集群:
- 单机:1台
- 集群:3台
版本信息:
- CentOS 7.3
- Nebula 1.1.0
- ArangoDB 3.7.2
- Neo4j 3.3.1
4. Benchmark结果
4.1 批量数据导入和 onehop、twohop 查询

以 ArangoDB 单机测试结果作为基准 1,对比结果如下图所示:

查询场景评测如下:

从查询语法的视角考察,AQL,nGQL 和 Cypher 都比较简练。但是,从可读性以及语法的学习复杂性考察,nGQL 类似 SQL,更加符合大家的使用习惯。
4.2 其他评测场景
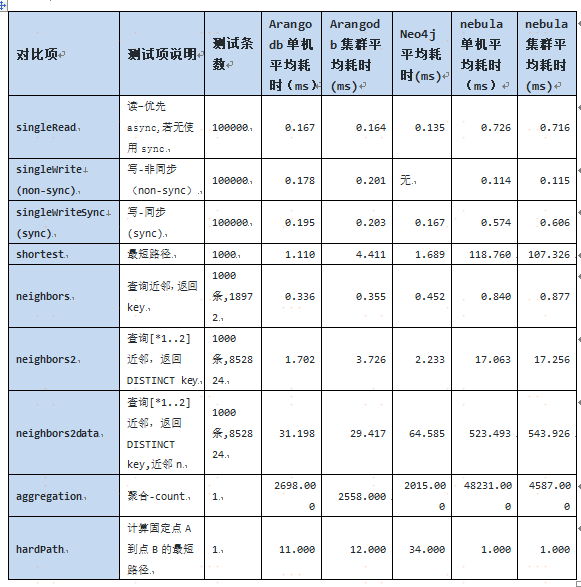
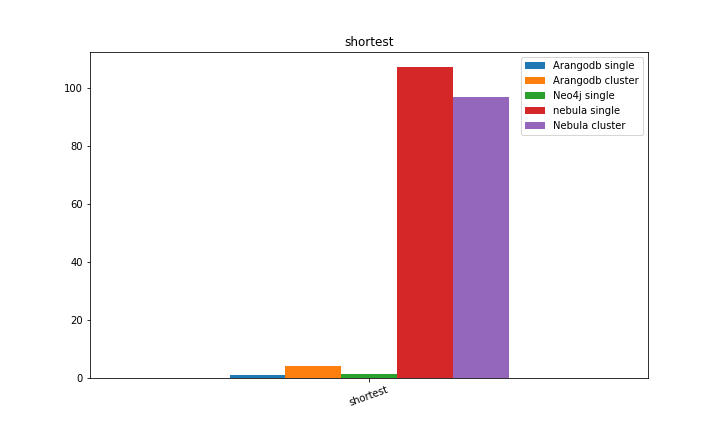
以 ArangoDB 单机测试结果作为基准 1,对比结果如下图所示:
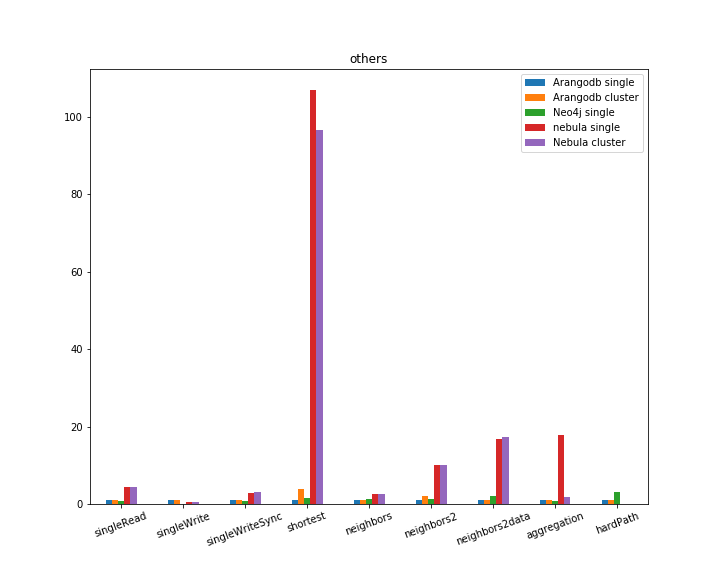
拆分再细看一下每个场景的对比,



5. 结论
通过上述测试结果可知,nebula 的批量导入速度快于 ArangoDB,但 Nebula 的 onehop 和 twohop 查询均慢于 ArangoDB 和 Neo4j,关于这一点,可以进一步讨论, 但是考虑到 Neo4j 社区版本不支持集群,ArangoDB 批量导入性能并不理想,而且处于半开源状态, 社区版的 SmartGraph 等核心能力并不开源,最后我们选择 Nebula Graph,当然, Nebula Graph 能够比肩 Neo4j 等分布式图数据库,这本身就是国人的骄傲!后续生产场景下的实践我们也会陆续和社区分享,一起促进 Nebula Graph 生态的发展。
作者:
- 汤泳 苏宁智能监控与运维产研中心总监
- 胡创奇 苏宁智能监控与运维产研中心算法 Lab
- 夏丹 苏宁智能监控与运维产研中心算法 Lab
- 张波 苏宁智能监控与运维产研中心算法 Lab