-
nebula 版本:(3.5.0)
-
部署方式:分布式
-
安装方式: RPM
-
是否上生产环境:N
-
问题的具体描述
使用阿里云上的datawork运行spark任务向nebula写入数据,使用的nebula-spark-connector_2.2的依赖包
每次运行任务总是写入一半就报错连接超时 如下图:
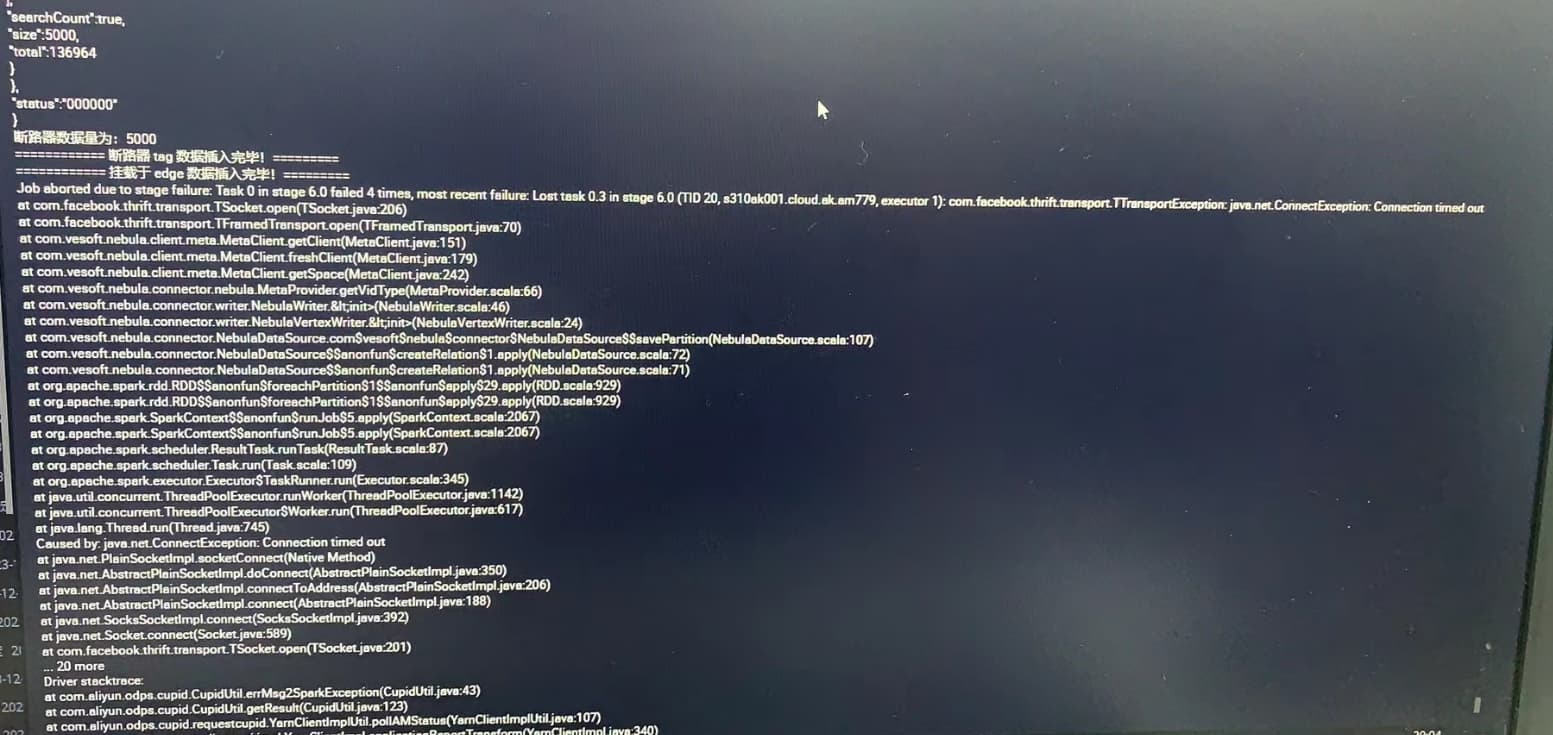
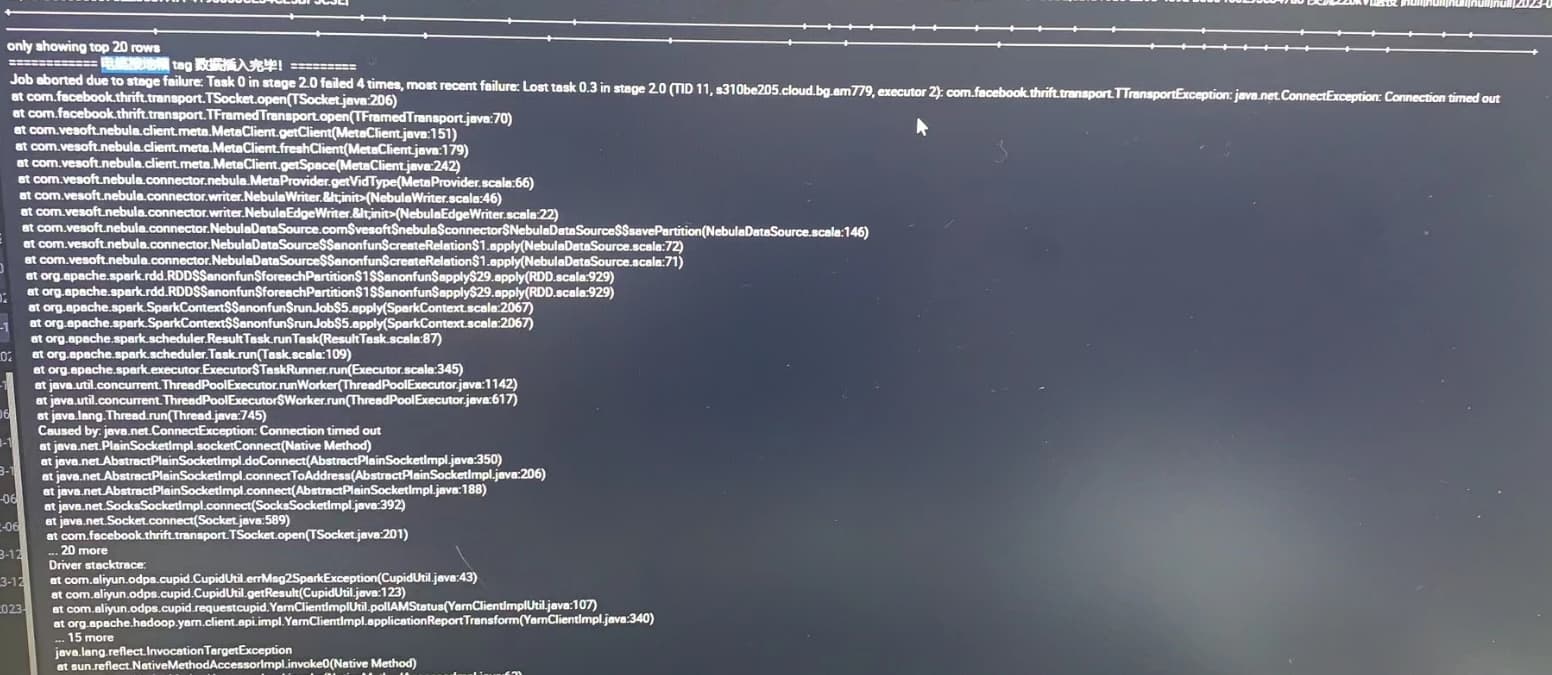
请问这是什么原因呢
nebula 版本:(3.5.0)
部署方式:分布式
安装方式: RPM
是否上生产环境:N
问题的具体描述
使用阿里云上的datawork运行spark任务向nebula写入数据,使用的nebula-spark-connector_2.2的依赖包
每次运行任务总是写入一半就报错连接超时 如下图:
请问这是什么原因呢
我们没有这个包,这是所有 spark-connector 的发版信息 Releases · vesoft-inc/nebula-spark-connector · GitHub
你确认下你用的 spark-connector 的版本号
主要问题是 数据能写入 但是读出来5000条 我配置是一次性写入2000条 我写入一半 就报错了 但是有的能写入5000条 有的也能写入几十万条 但是都会报错连接超时 这是什么情况
目前知道的是 那边的映射ip是做过slb的,就是说 一个ip 对应了集群的3个ip 是不能这样映射还是说 我的代码有问题呢
我们之前有用户遇到过类似问题,是因为用户环境有权限限制,然后spark集群只有部分节点申请了网络权限,导致落到其他没有网络权限的spark节点上的任务都报错connection timed out 导致任务失败。
你要确认下spark集群所有节点是否都能连通lb 的ip。
ps:你的数据能导进去了,说明你的代码没问题的
怎么确认spark集群所有节点是否都能连通lb 的ip
运行环境是 阿里云的odps-spark环境 所以这个我应该怎么验证呢
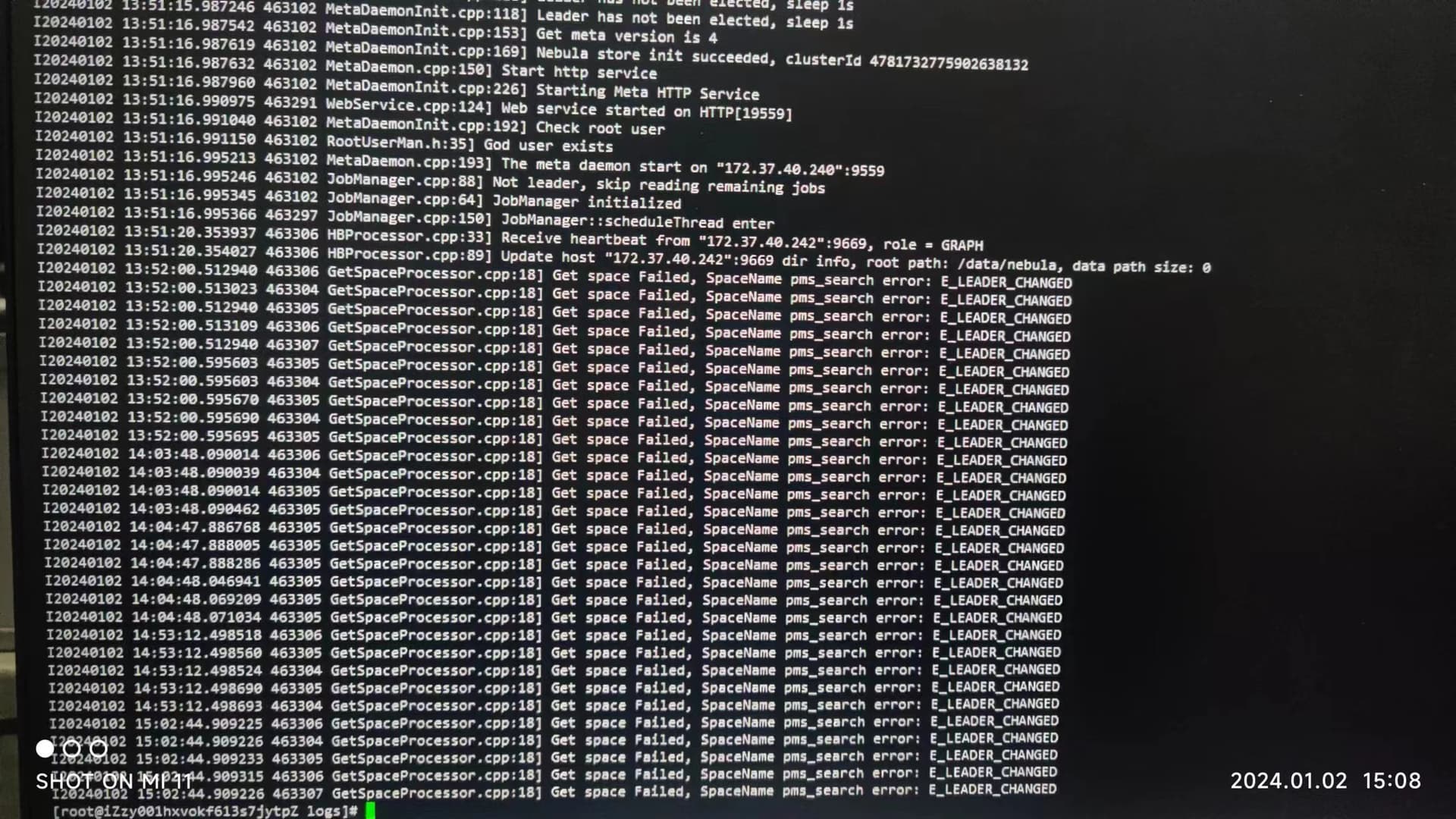
刚才我设置了一个节点进行数据写入,但是程序数据写入一半还是报错连接超时 数据倒是比上次多了1000条左右 这是meta连接出现问题了吗
是meta 连接异常了,你看下meta 服务的日志,是不是发生了leader change。
有可能你的spark节点可以连上你在exchange配置文件中所配置的那个meta 服务,但是连不上 leader change后的meta服务。
如果写数据的时候出现 连接了 第一台的ip+9559 第二台的ip+9669 这样能写进去数据吗 因为做slb映射后 连接是动态的 随机匹配的
那不行啊,metaclient 只能去连9559的地址
我的意思是 我本身是一个集群 但是slb映射是动态的 就好比 a b c 三台服务器, 写数据的时候 连接的ip不是一台服务器的ip 比如 连接了a服务器这台 IP 的meta端口9559 但是 graph端口9669 所在的 IP 连接却是 b服务器的 IP 这样能写进去吗 中间写入会报错吗
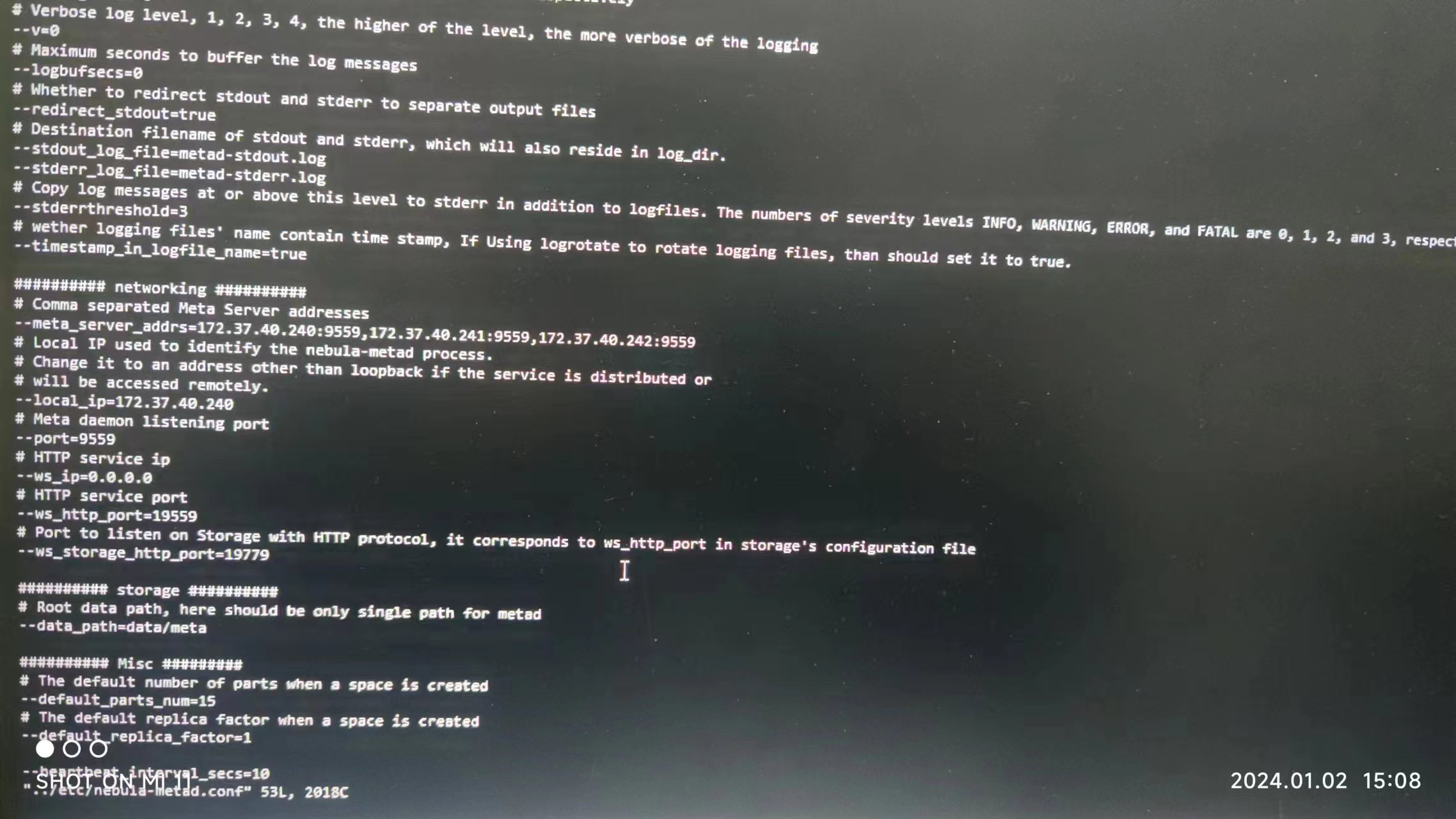
graph 是做查询的,meta 存有元数据以及和存储进行通信。上面 nicola 的意思就是,无论你 meta 在 ipA 还是 ipB,它的 meta 信息一定要填 meta 服务所在的 ip。而不是 graph 服务所在的 ip(默认 meta 的端口是 9559,graph 的端口是 9669,一般来说填 9559 所在的地址指的就是 meta 所在的地址)。
我的集群 是 每一台服务器都有一个meta graph 和 stroage 所以 我才问你们 如果做了slb映射 他的选择是动态的 假设连接了 a服务器的graph ip+9669端口 和b服务器的 meta ip+9559端口 这种情况 会报错吗
先看下 meta 这几个服务能不能互相通信,再看看能不能调整下 spark-connector 的 batch 值(调小点),还遇到这个问题不。
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。