20个小时才导入60G,还failed了 ![]()
![]() 请问有什么办法吗
请问有什么办法吗
个人建议贴上你的硬件信息,以及配置信息,再补充一下如何导入,此外导入慢先看下io和cpu使用情况,确定瓶颈在哪里?建议:先关闭自动compact,修改文件etc/nebula-storaged.conf,将disable-compact改成true,wal文件写也关闭
1 个赞
不好意思,我说错了,我是在studio里导入速度慢,但换成impoter也失败了,
配置信息如下:Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 1
Core(s) per socket: 32
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 134
Model name: Intel Xeon Processor (Icelake)
Stepping: 0
CPU MHz: 2992.966
BogoMIPS: 5985.93
Virtualization: VT-x
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 4096K
L3 cache: 16384K
NUMA node0 CPU(s): 0-31
您好,请问用impoter导入,但报错ErrMsg: Storage Error: RPC failure, probably timeout., ErrCode: -1005,导着导着会发现storage 挂掉了(unhealthy)
不是机器配置,是 importer 的 yaml 文件,你贴出来看看你的设置是什么。
可能是 batch 设置高了,![]() 你先把配置文件贴一下。以及你 nebula 和 nebula-importer 的版本分别是什么。
你先把配置文件贴一下。以及你 nebula 和 nebula-importer 的版本分别是什么。
诶,我这边好像没有batch, nebula 和impoter都是3.4.0(o(╥﹏╥)o好感谢您的频频现身)
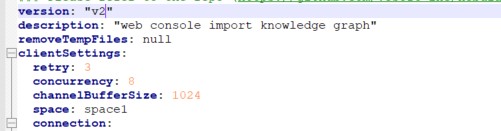
你可以读一读这个文章,batchsize 不是越大越好的,大概就是你的门就那么大,突然来了 1024 个人就堵在哪里了,如果是 10 个人就能畅行一样。
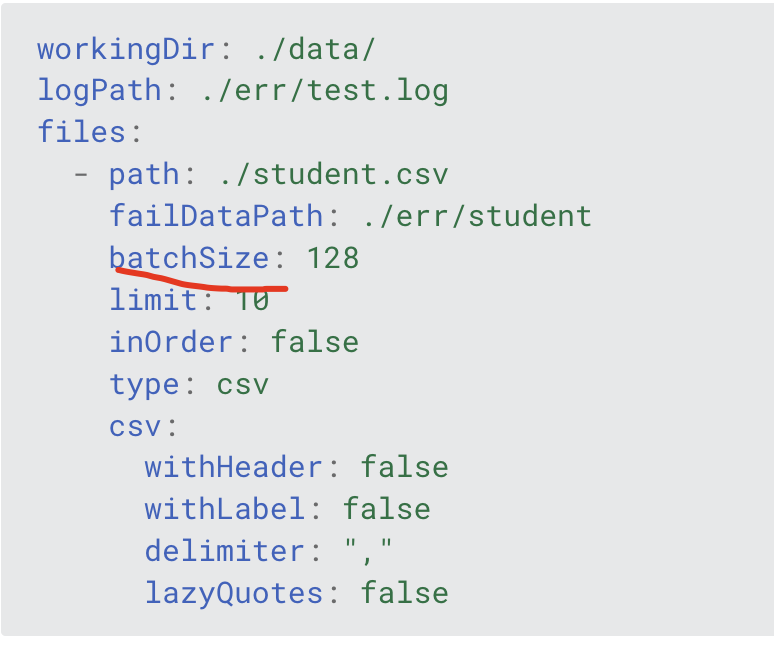
你先设置成 128 看看能不能完成导入。能完成的话,你再调下 batchsize 看下什么值能达到最大的导入速度。
您好,修改后状态停在“Waiting for stats manager done”12分钟了,久久没有start to read file ![]()
你看看原始的 yaml 配置是不是有缩进问题。然后 retry 改成 1 看看可以不
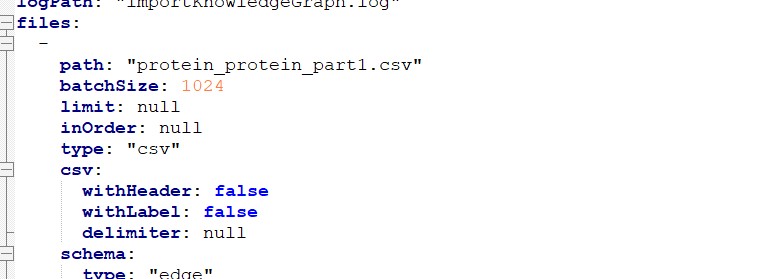
改成1了还是卡着捏,yaml放到studio跑是可以导的缩进应该没有问题吧 ![]()
![]()
你把配置文件贴全了,不要截图一半一半的,直接一个 yaml 文件 cv 贴过来看看。
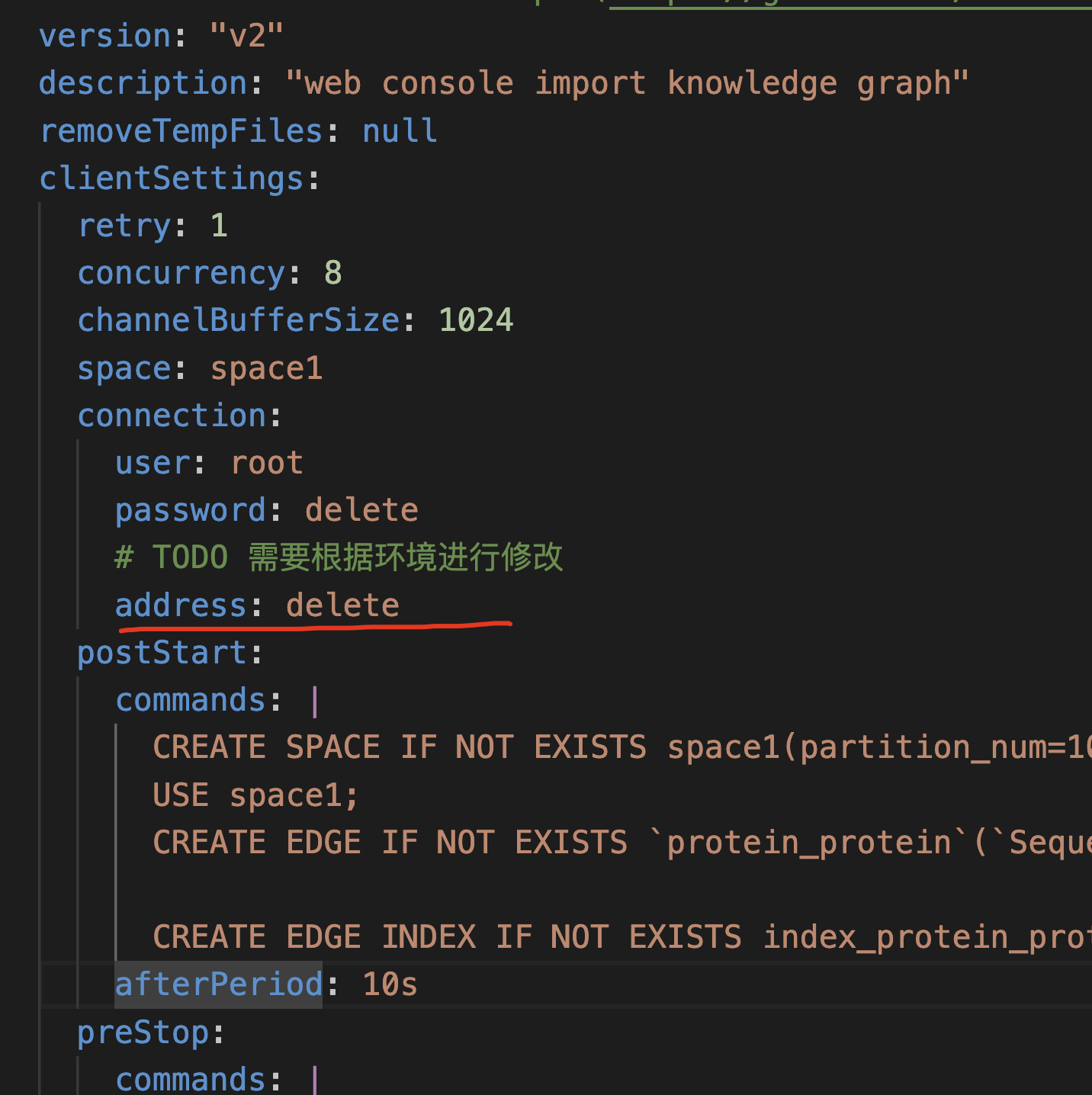
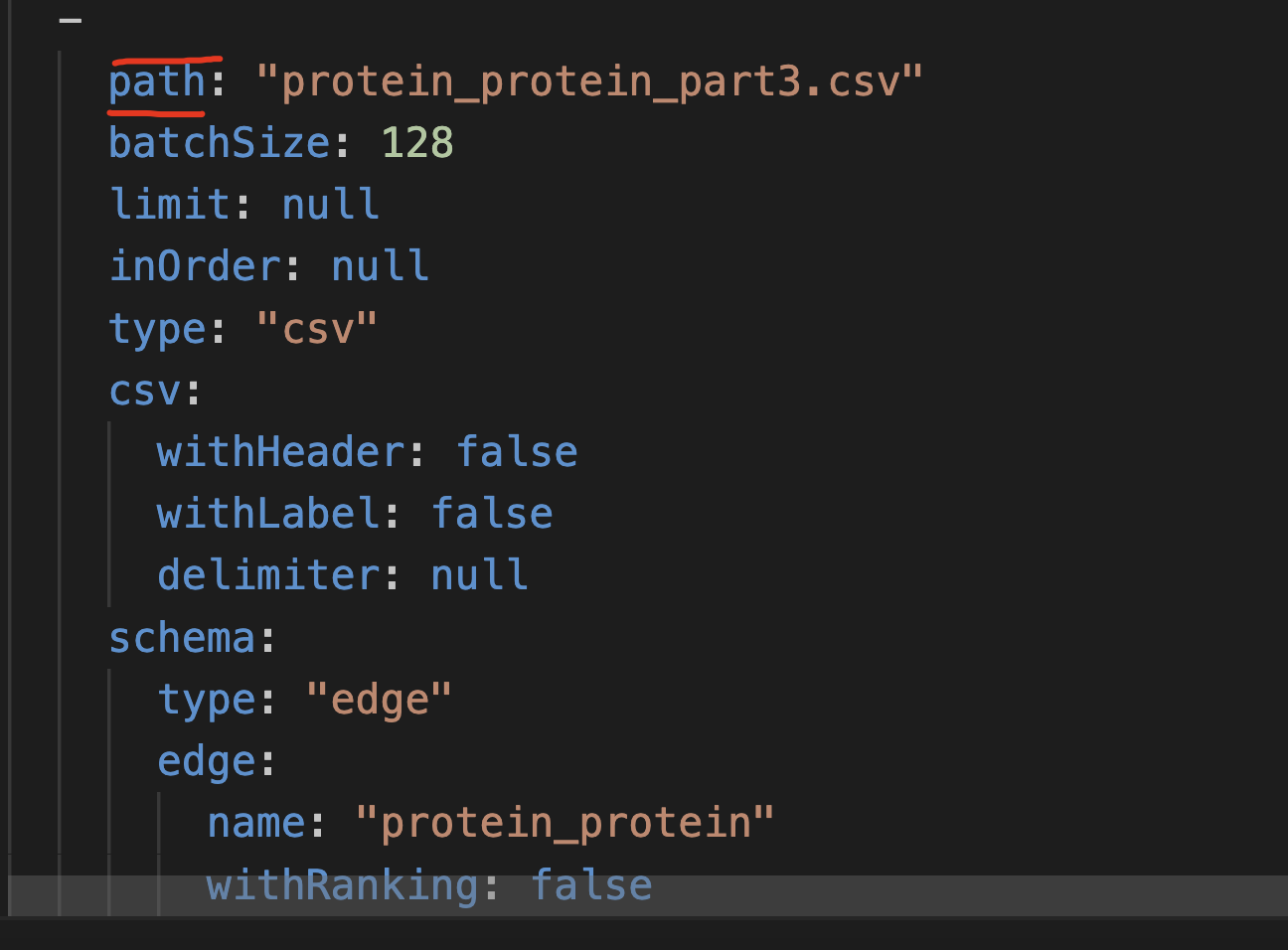
啊 delete是我自己刚刚删掉的,刚刚发现是我path里路径写错了,我挂载的地址修改了但yaml里没修改,这个path可能影响不是很大(从目前开始在读来看),谢谢捏!!!很感谢!!!!
导入速度依旧好慢啊,每秒只有2100左右…请问还有其他加速的方法吗
调 batch size 和 concurrency 试试。
啊我发现即使不改这些参数,速度也会变,现在变得每秒只有400多条了…