nebula版本: 3.2.0
Exchange版本:3.0.0
安装方式:docker
是否生产:否
硬件信息:云服务器部署
节点数量3 graph,3 meta,5 storage
问题描述:
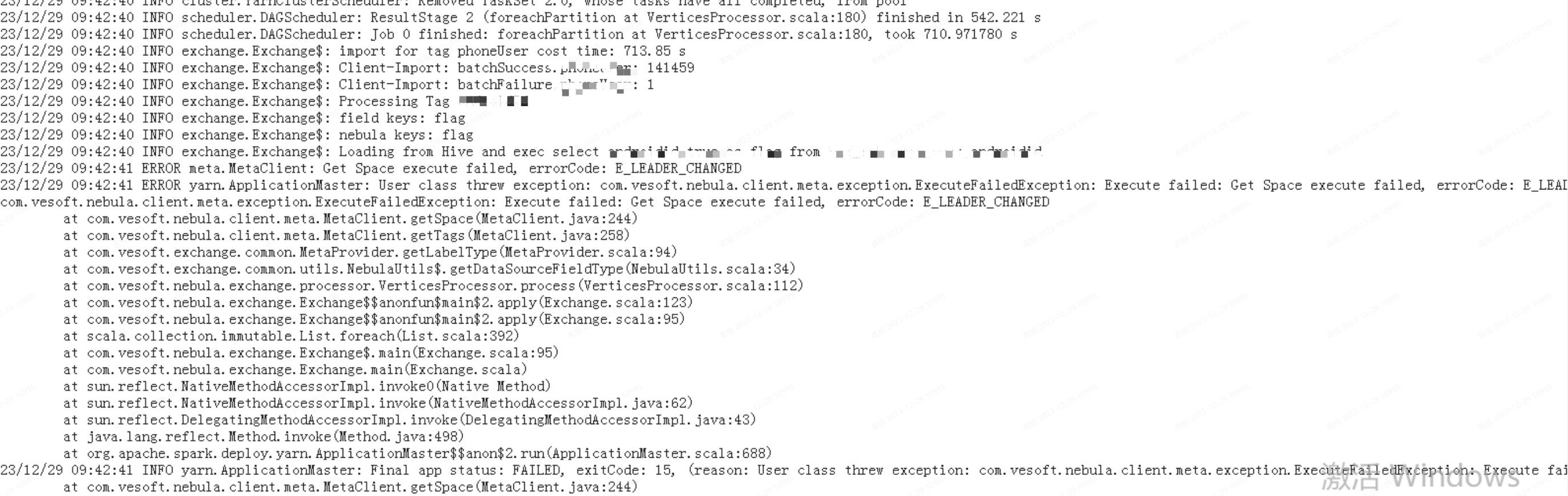
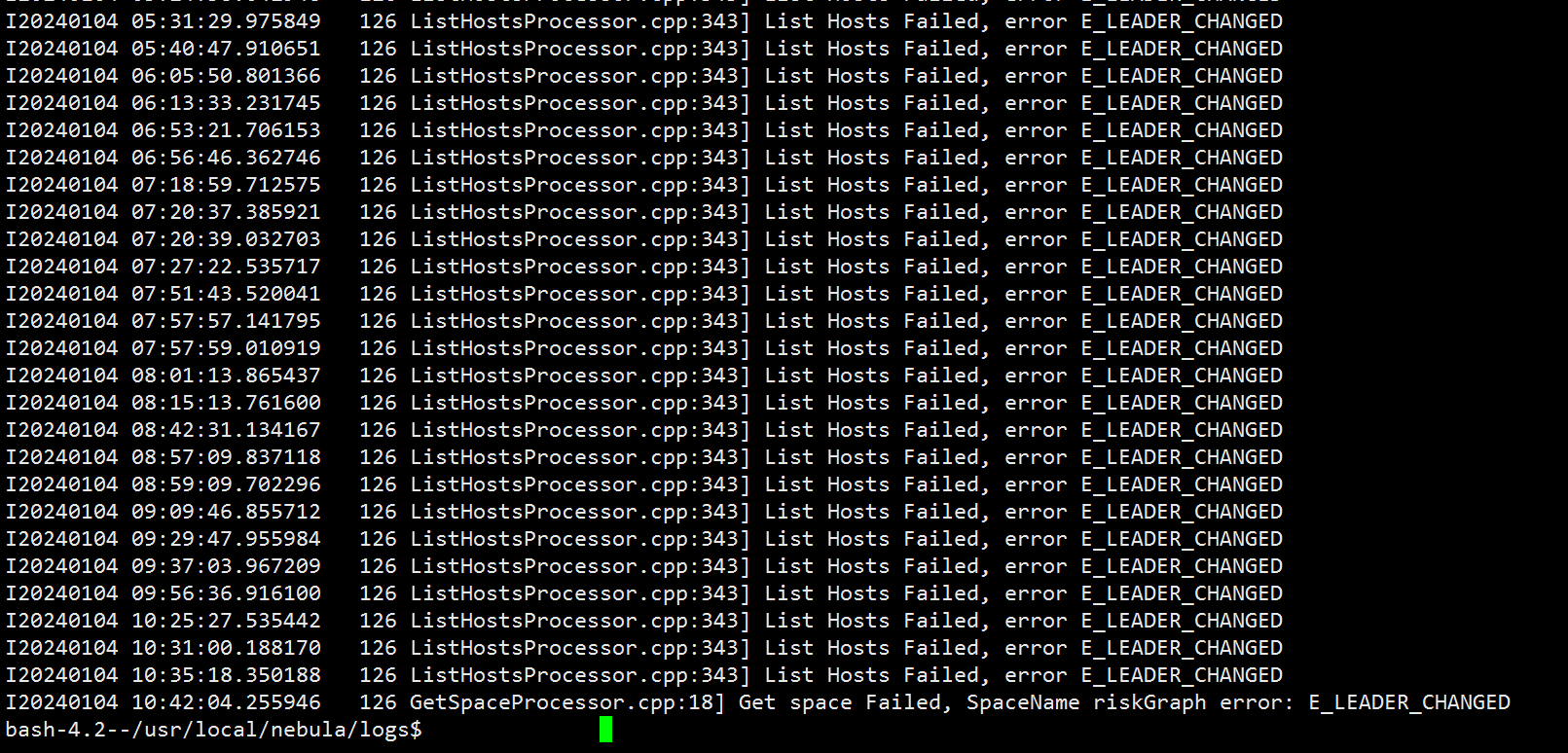
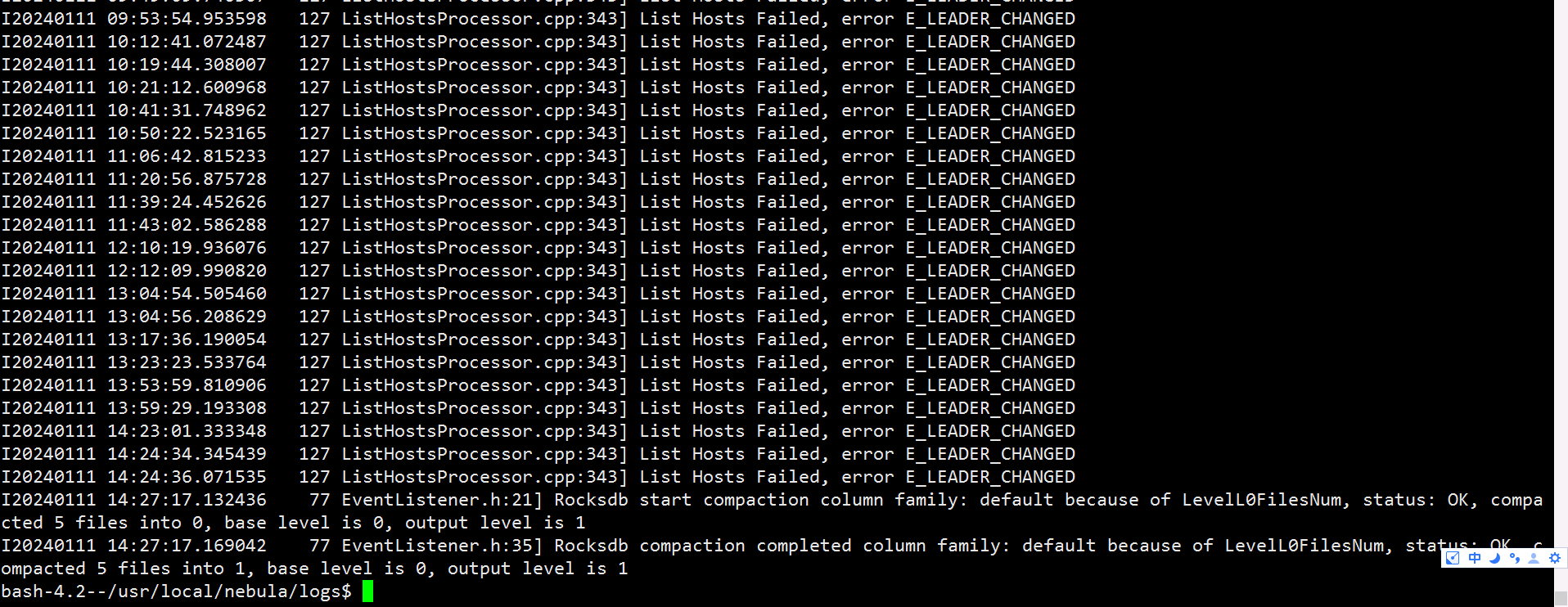
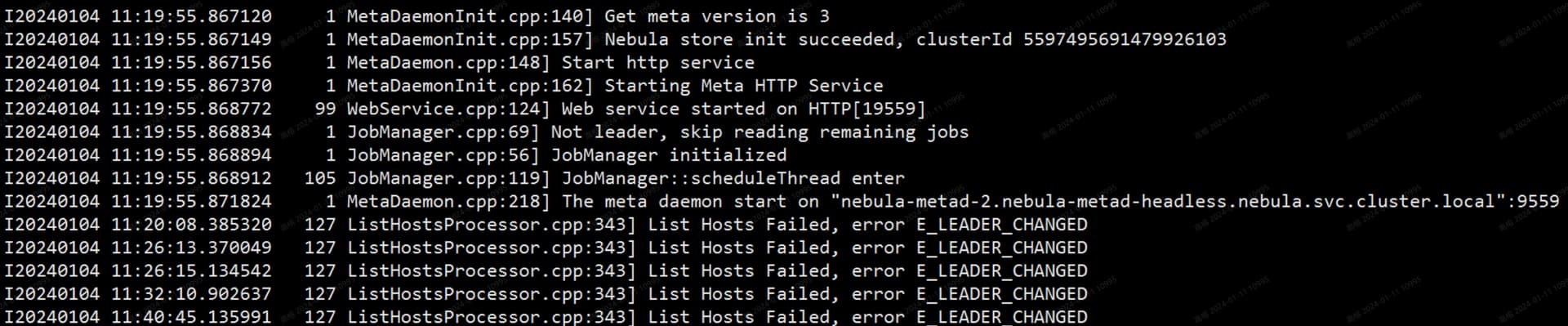
新建了一个3副本的图,用Exchange从Hive导入数据到Nebula时,会报Get Space execute Failed: E_LEADER_CHANGED的错,尝试了调整batch,partition,rate等写入速率相关的参数没有解决问题
conf里配置的会插入多个标签,在多次实验后发现报错总是发生在一个标签插入完成后,开始进行下一个标签的插入时基本必现该报错
而且在多次尝试后,Exchange会在启动后很快就会报E_LEADER_CHANGED
connection: {
timeout: 60000
retry: 3
}
execution:{
retry:3
}
error: {
max: 32
output: /tmp/errors
}
rate: {
limit: 512
timout: 60000
}
tags: [
{
name:phoneUser
type: {
source: hive
sink: client
}
exec: "select ***SQL***"
fileds: [flag]
nebula.fields: [flag]
vertex: {
fields: cust
}
batch: 1000
partition: 20
}
{
name: phone
type: {
source: hive
sink: client
}
exec: "select ***SQL***"
fileds: [flag]
nebula.fields: [flag]
vertex: {
fields: phone
}
batch: 1000
partition: 20
}
]