- 部署方式:分布式
- 安装方式:TAR
- 是否上生产环境:N
- 硬件信息
- 磁盘 HDD 12T * 1
- CPU 40 core
- 内存信息 128GB
- 问题的具体描述
在tag40亿规模的nebula-2.6.2版本中执行类似
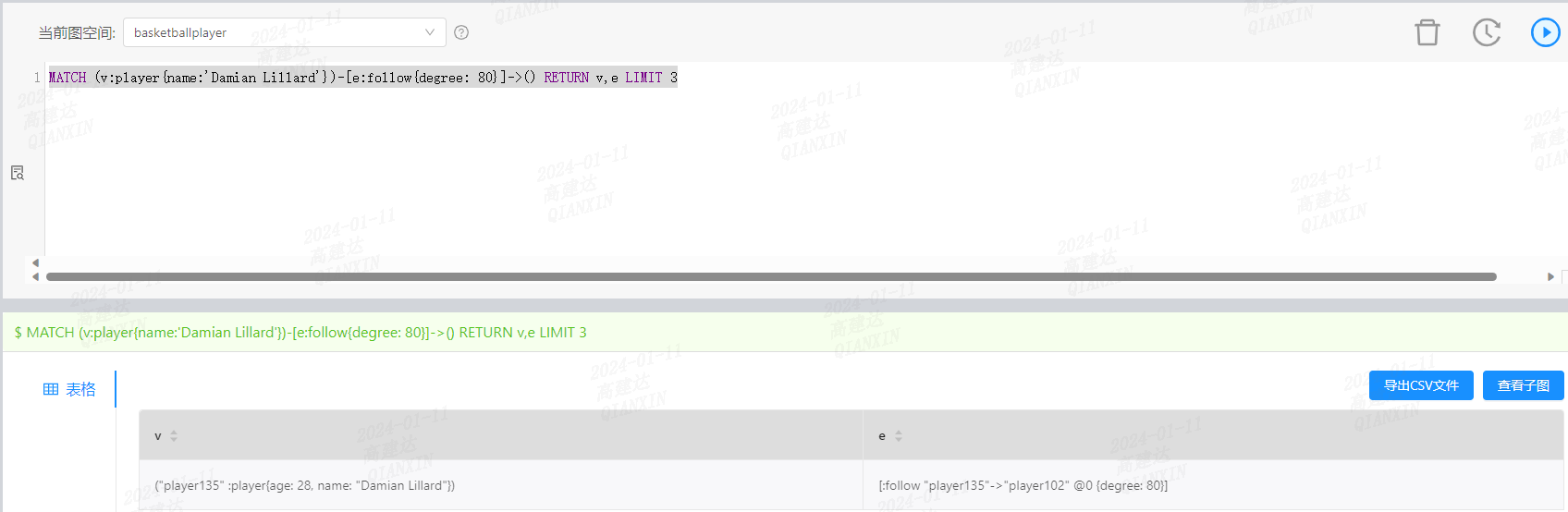
MATCH (v:player{name:‘Damian Lillard’})-[e:follow{degree: 80}]->() RETURN v,e LIMIT 3
的nGQL,总是执行不出结果。看到了nebula-3.4.0版本可能limit做了下推,就在测试环境模拟了一下,但是发现这样的语句好像也没有limit下推。想了解下怎么优化下。
nebula-3.4.0执行结果:
执行计划:
PROFILE MATCH (v:player{name:‘Damian Lillard’})-[e:follow{degree: 80}]->() RETURN v,e LIMIT 3
| 13 | Project | 12 | ver: 0, rows: 1, execTime: 11us, totalTime: 12us | outputVar: { colNames: [ v, e ], type: DATASET, name: __Limit_7 } inputVar: __Limit_12 columns: [ $-.v AS v, $-.e[0] AS e ] |
|---|---|---|---|---|
| 12 | Limit | 4 | ver: 0, rows: 1, execTime: 8us, totalTime: 12us | outputVar: { colNames: [ v, e, __VAR_0 ], type: DATASET, name: __Limit_12 } inputVar: __AppendVertices_4 offset: 0 count: 3 |
| 4 | AppendVertices | 11 | { ver: 0, rows: 1, execTime: 113us, totalTime: 491us resp[0]: { exec: 69(us), host: 10.58.42.222:9779, total: 373(us) } total_rpc: 422(us) } | outputVar: { colNames: [ v, e, __VAR_0 ], type: DATASET, name: __AppendVertices_4 } inputVar: __Traverse_3 space: 1 dedup: true limit: -1 filter: orderBy: src: none_direct_dst($-.e) props: [ { props: [ _tag ], tagId: 2 }, { props: [ _tag ], tagId: 9 }, { props: [ _tag ], tagId: 3 } ] exprs: vertex_filter: if_track_previous_path: true |
| 11 | Traverse | 8 | { ver: 0, rows: 1, execTime: 144us, totalTime: 12221us step[1]: [ { exec: 410(us), host: 10.58.42.223:9779, storage_detail: { FilterNode: 284(us), GetNeighborsNode: 296(us), HashJoinNode: 266(us), RelNode: 297(us), SingleEdgeNode: 100(us), TagNode: 134(us) }, total: 5605(us), total_rpc_time: 12065(us), vertices: 5 }, { exec: 717(us), host: 10.58.38.173:9779, storage_detail: { FilterNode: 546(us), GetNeighborsNode: 557(us), HashJoinNode: 510(us), RelNode: 559(us), SingleEdgeNode: 169(us), TagNode: 287(us) }, total: 11926(us), total_rpc_time: 12065(us), vertices: 6 }, { exec: 914(us), host: 10.58.42.222:9779, storage_detail: { FilterNode: 770(us), GetNeighborsNode: 779(us), HashJoinNode: 733(us), RelNode: 780(us), SingleEdgeNode: 201(us), TagNode: 484(us) }, total: 7917(us), total_rpc_time: 12065(us), vertices: 2 } ] } | outputVar: { colNames: [ v, e ], type: DATASET, name: __Traverse_3 } inputVar: __IndexScan_1 space: 1 dedup: true limit: -1 filter: (follow.degree==80) orderBy: src: $_vid edgeTypes: edgeDirection: OUT_EDGE vertexProps: [ { props: [ name, age, _tag ], tagId: 2 }, { props: [ a, b, _tag ], tagId: 9 }, { props: [ name, _tag ], tagId: 3 } ] edgeProps: [ { props: [ _src, _type, _rank, _dst, degree ], type: 4 } ] statProps: exprs: random: false steps: 1…1 vertex filter: edge filter: if_track_previous_path: false first step filter: ((player.name==Damian Lillard) AND (follow.degree==80)) tag filter: (player.name==Damian Lillard) |
| 8 | IndexScan | 2 | { ver: 0, rows: 51, execTime: 0us, totalTime: 20186us resp[0]: { exec: 320(us), host: 10.58.42.223:9779, storage_detail: { IndexLimitNode(limit=9223372036854775807): 231(us), IndexProjectionNode(projectColumn=[_vid]): 231(us), IndexVertexScanNode(IndexID=8, Path=()): 227(us) }, total: 15805(us) } resp[1]: { exec: 325(us), host: 10.58.38.173:9779, storage_detail: { IndexLimitNode(limit=9223372036854775807): 236(us), IndexProjectionNode(projectColumn=[_vid]): 235(us), IndexVertexScanNode(IndexID=8, Path=()): 241(us) }, total: 18309(us) } resp[2]: { exec: 736(us), host: 10.58.42.222:9779, storage_detail: { IndexLimitNode(limit=9223372036854775807): 447(us), IndexProjectionNode(projectColumn=[_vid]): 449(us), IndexVertexScanNode(IndexID=8, Path=()): 486(us) }, total: 19968(us) } } | outputVar: { colNames: [ _vid ], type: DATASET, name: __IndexScan_1 } inputVar: space: 1 dedup: false limit: 9223372036854775807 filter: orderBy: schemaId: 2 isEdge: false returnCols: [ _vid ] indexCtx: [ { columnHints: , filter: , index_id: 8 } ] |
| 2 | Start | ver: 0, rows: 0, execTime: 0us, totalTime: 20us | outputVar: { colNames: , type: DATASET, name: __Start_2 } |