导读 本文将分享关于推荐系统以及大模型的一些思考,从推荐系统的评测和数据层面讨论关于大模型是不是推荐系统的一个好的解决方案的问题。
今天的介绍会围绕下面四点展开:
-
推荐系统的问题定义及其在工业界与学术界的差异
-
推荐系统的离线评测及典型的数据泄漏问题
-
推荐系统的数据构建问题
-
大模型在推荐系统的模型层面的定位问题
01 推荐系统的问题定义及其在工业界与学术界的差异
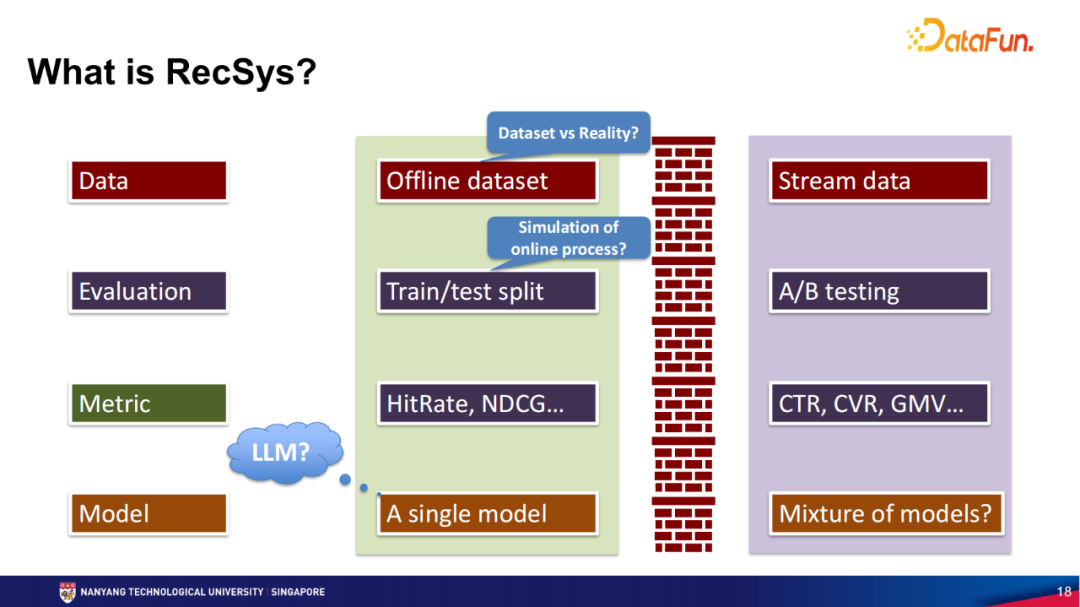
首先来介绍一下什么是推荐系统。对于推荐系统的理解,学术界和工业界之间存在着一定的差异,包括数据、评测、性能指标及模型等层面的差异。例如,在数据层面,学术界很难获取到真实的在线数据,所以获取的是离线数据,通常情况下是一个静态的数据集,例如MovieLens和Amazon, Yelp等通用数据集。工业界需要通过推荐系统获得一些收益,并且推荐系统本身是在线的,所以能看到的数据是通过实时的用户交互而产生的在线数据。在评测层面,学术界通常是将一个离线的数据集分成两部分,一部分用来训练推荐模型,另一部分用于评测,通过对离线数据的划分,进而推断推荐模型在一些指标维度上的性能表现。而在工业界当中,通常是使用A/B testing,来测试线上环境中算法的有效性。在性能指标标准层面,学术界通常是用一些准确度的标准,例如HitRate、NDCG等,而工业界则需要转化率或者算法带来的收益作为评测标准。在模型层面,在学术界,通常是为了证明提出来的一个模型比其他模型更有效,而在工业界则是使用多个模型的混合,考虑不同模型在不同场景带来不同的收益。本次讨论的问题是,在单模型的情况下,大语言模型是否是一个好的解决方案。判断一个方案是不是好的方案首先要理解如何评测该方案。
02 推荐系统的离线评测及典型的数据泄漏问题
对于推荐系统而言,评测是非常困难的。在《Recommender Systems Handbook》一书中有一个章节专门对推荐系统的评测问题进行了讨论。其中提到了两点:第一点是,离线实验通常是为了找到一些在实际线上阶段中可能会表现更好的方法,这样就不需要把表现不好的方法用作线上测试,避免算法表现不好导致用户流失,所以需要选取一些具有很强潜力的算法用于线上测试;另一点是在线下离线测试时需要尽可能模拟线上环境进行测试,提前预估算法在线上环境的运行指标效果,从而减少算法发布到线上环境后效果不足。

该书中也提到了5种测试的设置方式,主要体现在当具备一个静态数据集的条件下,该如何去划分训练集和测试集。这5种数据划分设置如下:
-
第一种是最贴近线上环境的划分方式。将所有的用户交互按时间顺序放到一个时间轴线上,每一个点代表一个用户交互。之后有一个滑动时间切分点,从左往右滑动,在切分点之后的下一个交互点就是下一个测试样本,沿着时间轴线从左至切分点之前的交互点是训练集。同时这个切分点一直往右滑动,即训练集一直在增加,模型会通过对这个不断扩充的训练集的学习去判断切分点之后的下一个交互。这种划分方式是最贴近于线上环境的。我们知道了用户过去买了什么,用户过去点击了什么,进而预测用户的下一个点击会是什么。采用这种划分方式的测试是非常难做的。
-
第二种划分是稍微有些弱化的方式,不再是每一个点都作为一个测试样本,而是选取一些点作为测试样本,所以测试的次数会变少,复杂度也相应地会降低。
-
第三种划分是不考虑全局的时间线,只是选取一个时间点,在这个时间点之前的所有数据都属于训练集,之后的数据属于测试集。
-
第四种是通过用户维度的一个时间线,不考虑全局的时间线。按照每个用户的时间线,除去该用户的最后一个交互,其它所有交互都是训练集,该用户的最后一个交互是测试样本。这是比较常用的一种划分方式,即Leave-one-out划分方式。
-
第五种是一种更弱化的方式,通过随机划分,将数据集划分出一部分为训练集,另一部分为测试集。

在已有的88篇RecSys会议发表的文献中,有近60%的文献采用了随机划分或Leave-one-out划分。这两种划分都没有考虑数据划分选取的时间线。接下来我们具体讨论这种没有考虑全局时间线会造成的问题。

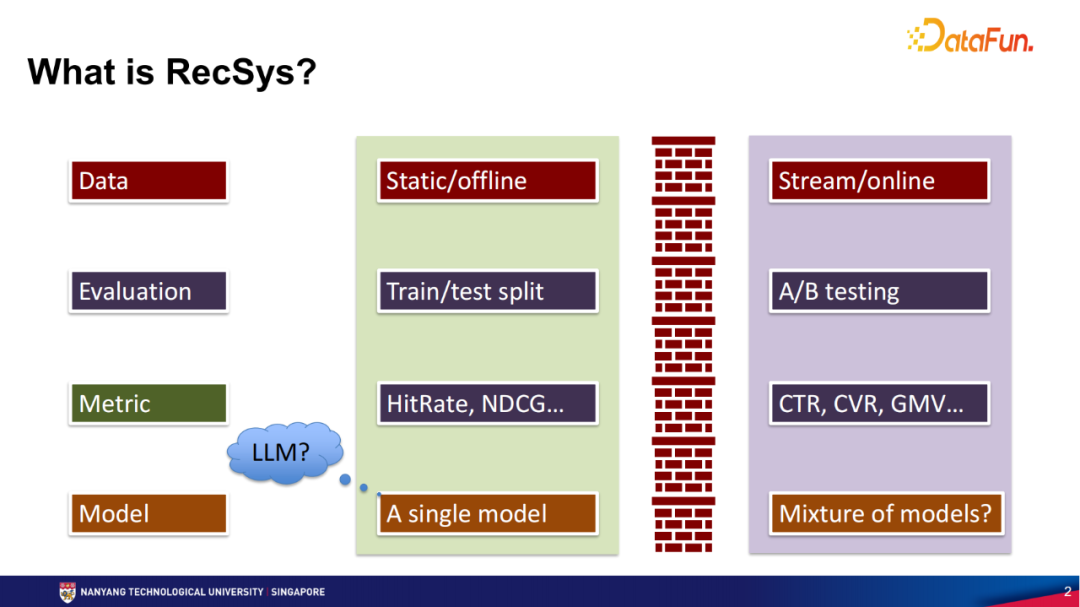
首先来看一下现实中推荐系统是如何服务用户的。如下图所示,用户 u1、u2和u3,在之前有若干的交互,tc代表现在的时间点。用户如果现在去访问某一个网站,或者现在打开某一个APP,那么tc时间点就相当于线上的测试时间点。在这个时间点,推荐算法会推荐一些item给这个用户进行交互。不管该用户之前的历史交互发生在什么时间,该用户所有的历史交互实际上是发生在点击这个网站,或者点开APP这个时间点tc之前。现实中的推荐系统要真正做到的是从用户过去的行为来学习,并去判断用户的下一步交互。
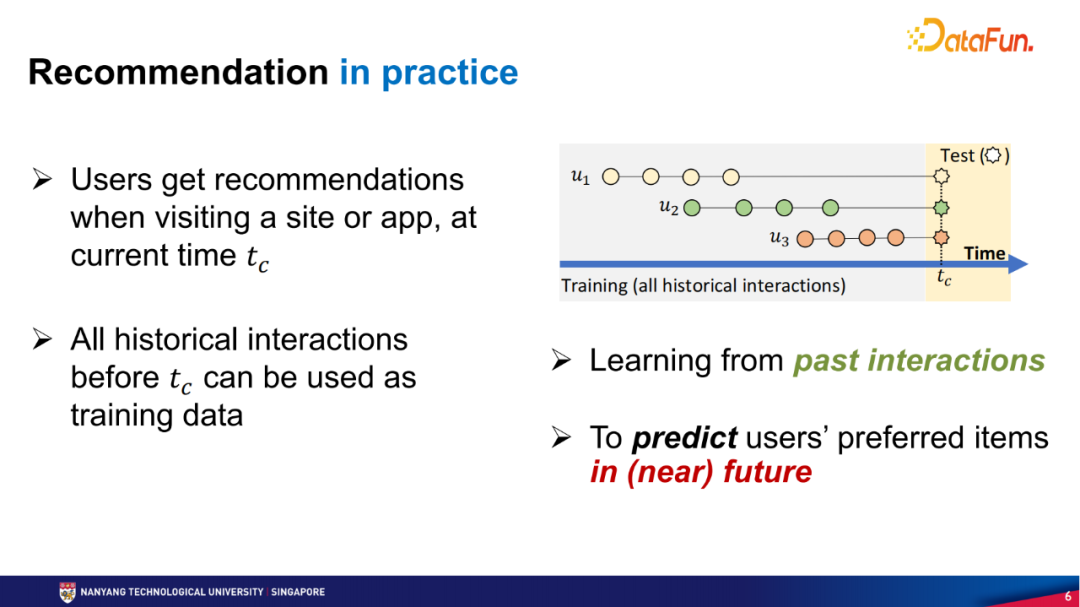
这里举一个最简单的基线算法(基于流行度的推荐)作为例子,通过统计什么样的商品正在流行进行推荐,比如微博的热搜,或是一些流行商品推荐。下图有两个例子,一个是每周最畅销的书籍,另一个是小时级内最畅销的商品。这些畅销的书籍或商品都是随着时间的变化而变化的,也就是去年某一周的畅销书跟今年某一周的畅销书应该是不一样的。用户如果现在访问这些网站,看到的就是当前时间段最流行的物品。
学术界对推荐系统问题进行了一些简化,试图用一个统一的推荐系统的问题定义去涵盖几乎所有不同场景的推荐的问题,比如音乐,电商,书籍推荐等等。很多情况下,我们发现推荐系统的问题定义是将用户与物品之间的交互表示成一个二维的矩阵,在这个矩阵里面会存在一些用户交互的历史记录,反映了某一个用户喜欢的某一个物品。我们的任务是去判断这个用户是否是喜欢另外的某一个物品,并且根据该用户对物品的喜好程度进行排序。

上述推荐系统的问题定义里面没有全局的时间线,可能存在的最大问题之一就是数据泄漏问题。我们在ACM TOIS的一篇文章里面做了更具体的探索,在这个问题研究中我们采用Leave-one-out划分方法得到训练集和测试集。我们知道Leave-one-out划分方法是将用户的最后一个交互作为测试。但是现实中我们不能保证所有的用户是遵循统一的时间线去进行交互的,所以会存在有的用户产生的交互时间比较早,而有的用户交互发生的时间比较晚。如果我们将三个用户的交互沿着时间线的分布画出来,如下图,那么就能看到第一个用户的测试点在tx1时间线位置,第二个用户的测试点在tx2时间线位置,第三个用户的测试点在tx3时间线位置。除去这三个测试点,时间轴线上剩下的交互点会作为训练集,这样做的问题在于第二个用户的部分交互和第三个用户的所有交互是发生在第一个用户的测试点之后的,但是推荐系统是将第二个用户和第三个用户的这些交互一并作为训练集的一部分来判断第一个用户在tx1测试点的交互。如果我们考虑最基本的流行度概念的话,我们是将整个训练集里面的最流行的物品做成一个推荐列表推荐给第一个用户,其中部分训练集的交互点是发生在tx1测试点之后的,那么推荐这些训练集的物品就是没有意义的,因为有些物品在tx1的测试点时还没有出现,第一个用户在tx1测试点不太有可能去看到这些物品。这就是典型的数据泄漏问题。类似的例子还有球赛直播,直播的时候观众可以观看球赛进展的情况,但是不太可能预测到什么时候有射门的镜头以及射门之后球有没有进。但是在离线情况下,如果我们模仿leave-one-out的设置,把射门的时间点作为测试点,让系统判断射门之后球有没有进。但是除了这些射门的时间点,系统可以看到完整的球赛录像, 相当于系统用这个整个球赛录像中的信息去判断第一个射门有没有进球第二个射门有没有进球。这样的离线环境下的射门判断和在看直播时候的射门判断是不一样的。

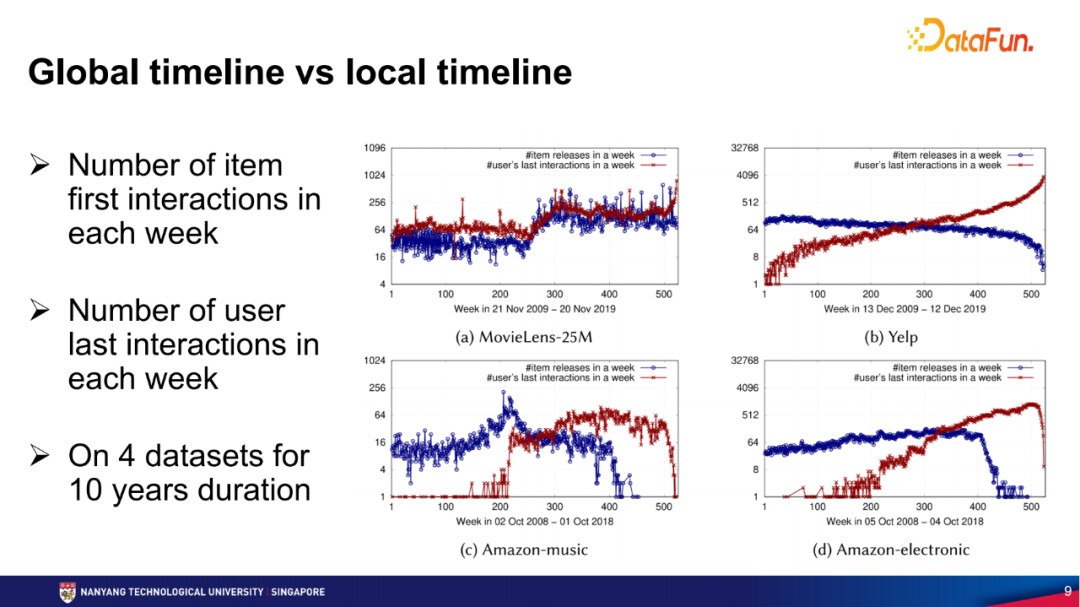
现实中的数据集是不是真的存在类似的情况呢?我们分析了4个数据集,包括MovieLens-25M、Yelp、Amazon-music和Amazon-electronic。下图中蓝色点的时间点是某一个item第一次有评论的时间,我们认为是item在平台上推出(release)的时间。蓝色点在y-轴的位置是这个星期内有多少个item是新推出的item。红色点在y-轴的位置是这个星期内有多少个用户最后的交互落在这个星期,之后用户就离开平台了,不再有其他交互。在Leave-one-out划分时这些红色点就是对应用户的测试点。从下图中的4个数据集上可以看到,有很多用户其实在很早的时候就离开这个平台了,也就是以后不再参与这个交互,同时,也有很多item是后来才被导入的,所以按照这种数据划分,现实数据集中确实会出现数据泄漏问题。
数据泄漏问题会对算法有影响吗?我们用另外一个模式来解释。下图中,对于用户A,SAB是用户A交互过的物品集合,这个X是用户A交互的最后一个物品,通常情况下X应该是用户A的测试物品。同时,用户B交互了SAB和SBC等物品集合,这个Y是用户B的最后一个测试,t1、t2和t3都是时间点。用户C有交互SBC,Z是用户C的最后一个测试。因为用户A和用户B有共同的交互SAB,也就是都喜欢某一类物品,所以通过协同过滤CF的推荐方式,我们基本会判断用户A和B有一定的兴趣相似,同样地,用户B和C也有一些共同的交互SBC,那么通过协同过滤CF方法,我们也可以认为用户B和C有一定的兴趣相似,同样地通过协同过滤CF方法我们可以推断出用户A和C也是有相似兴趣的。
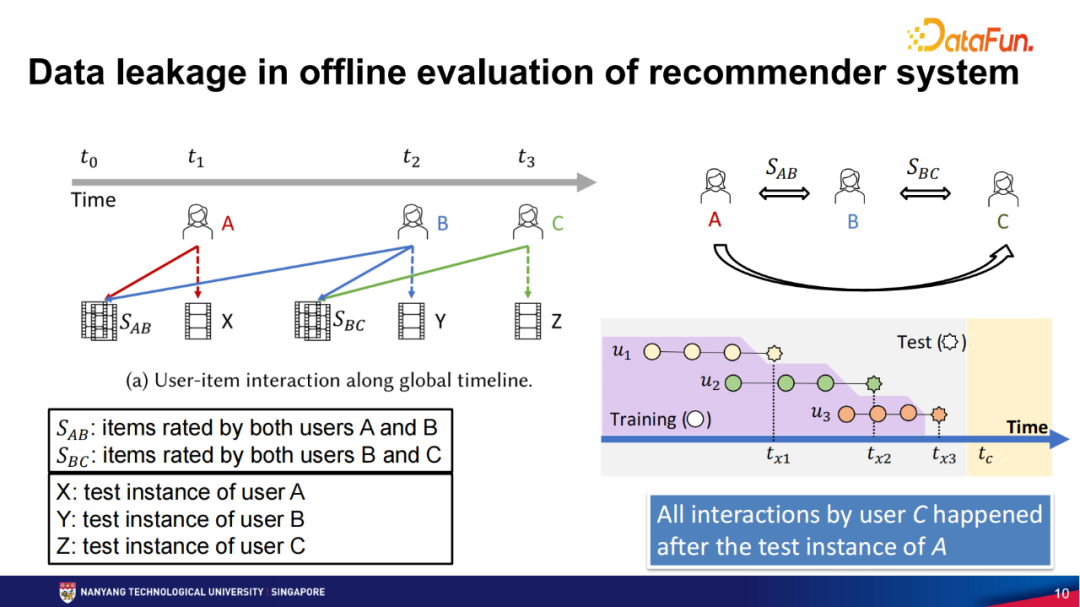
可以看到用户A所有的交互都是发生在t1之前,它对用户C来说可能有一定的贡献,但是用户C所有的交互是发生在用户A离开系统之后的,现实中是不可能对用户A的推荐产生影响的。但是因为数据泄露,用户C的这些交互对用户A的评测点起到什么作用呢,我们并不清楚,所以我们进行了一些测试。我们采用上述4个数据集进行了测试,采用Leave-one-out作为数据划分,选取了4个常见的推荐模型,BPR、NeMF、LightGCN和SASRec。

实验问题设置选取了上述4个数据集的10年的数据。我们选了其中一年,例如第5年作为测试集,那么第1年至第4年的所有用户交互都是已知的并作为训练集的一部分,选取第5年期间用户的最后一个交互作为测试,第5年期间用户的其它交互作为训练集。所有发生在第6年至第10年的交互相对这个测试集来讲都是未来的数据,也就是在现实中不可能拿到的,但是在离线数据可以拿到,我们要做的就是评测这些未来数据的影响。实验中,我们把第6年到第10年的数据依次加入训练集来测试数据泄露的影响。
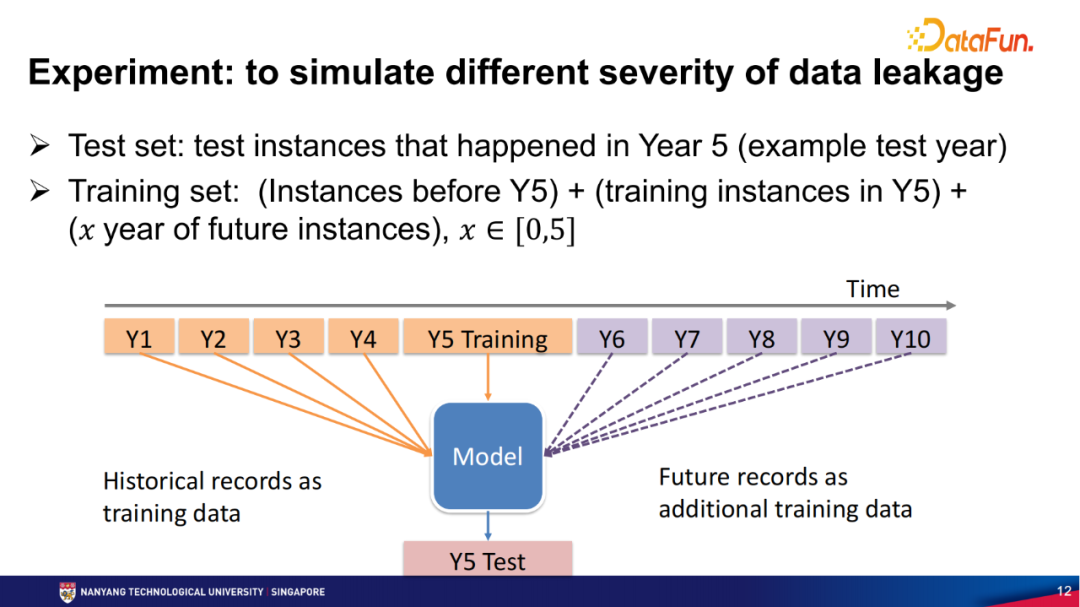
实验的第一个测试是为了说明是否真正得到了一些未来的Item的推荐,比如一个新的手机是在用户离开这个平台之后才发布的,对于这个用户来说就是一个未来的Item。通过这个实验我们发现无论采用哪个数据集,无论哪个推荐模型,都会推荐一些未来的Item,这在现实中是不存在的。

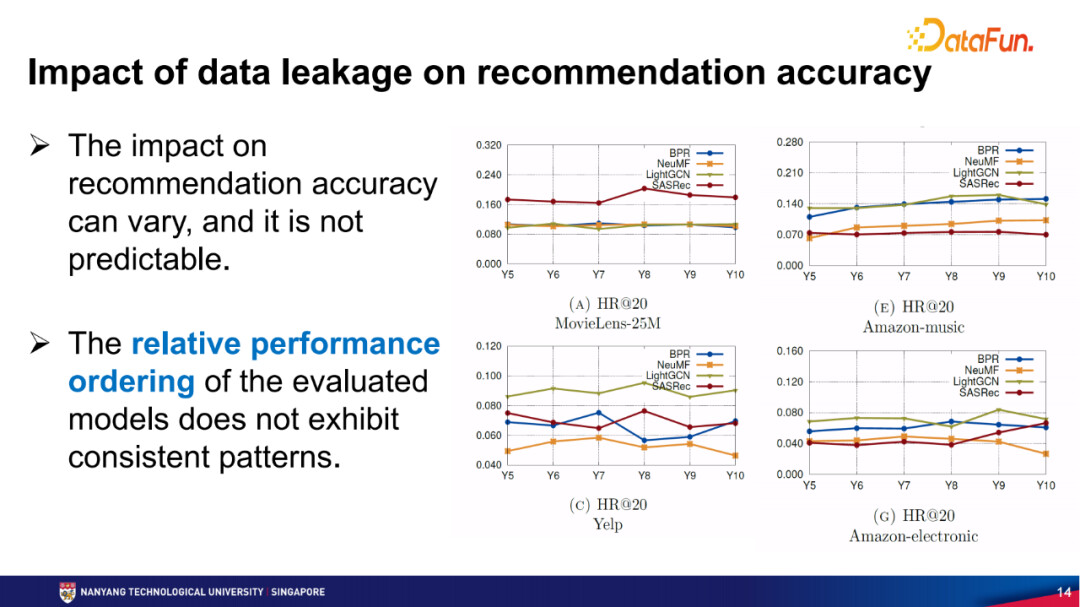
当然这个现实中不存在的现象并不代表采用的数据划分方式或评测方式没有意义。如果最后评测出来的所有方法之间相对的准确性有一定的排序的话,比如方法a永远是最好的,方法b永远是第二好的,不管是否有用到未来的item数据,这样的条件下我们也是能够在一定程度上判断出方法a会比较好,方法b会比较差。
在实际当中是否是这样呢?下图中可以看到,第5年的方法排序情况,第6年开始后的数据都是未来的item,在现实中不存在的,但是在离线数据中是存在的。可以看到对不同的数据集上这些方法的排序是不一样的。这在一定程度上说明,在Leave-one-out划分的情况下,我们很难得知哪一个方法更好,因为在这种情况下,我们并不知道有多少这种未来的item交互参与评测,因此对每个测试的点,用到的未来交互是不一样的,也就很难去评测和定性地分析,我们只能笼统地去做一个判断。这就可能造成在很多推荐系统的文献中,某篇文章讲基线模型a比较好,而另一篇文章讲基线模型b比较好。
03 推荐系统的数据构建问题
接下来讨论数据构建的问题,这里只讨论一个数据集MovieLens,原因是MovieLens可能是所有推荐数据集里面最常用的,大概有70%的推荐系统论文会使用该数据集。
MovieLens数据集的数据收集过程如下。首先需要建立一个新的账号去这个网站进行交互,刚开始系统对这个新账号是一无所知的,因此系统会问这个用户大概喜欢什么样的电影,这个时候系统会给出一些组别,有些可能是动作片,有些可能是记录片,有些可能是言情片,这个新账号用户喜欢哪种就给对应的组别一个分数。例如给动作片和言情片分别打分为2分,儿童片打分为1分,这些是属于喜欢的,另外一些是不喜欢的。然后系统会根据得到的分数,给出第一个网页,列出一些相对有名的电影,并且电影的数量也不是特别多,那么新账号用户就开始给这些具体的电影打分。有了这些打分之后,系统会给出下一个网页,显示出更多的电影让用户打分。因为系统对新账号已经有所了解,它会通过内部的一个推荐算法来找出新账号用户可能更喜欢的电影。这个时候推荐系统推荐的候选电影池会变得更大,用户会在第二个网页上打分,然后系统会进入第三个网页,同样的,因为系统会根据之前的打分推荐电影,直到新账号用户觉得差不多看过的电影都打分完毕。大概50%的用户在一天之内完成了所有的电影打分,之后就离开这个平台不再打分。85%的用户是在三天之内完成所有的电影打分,之后离开平台。
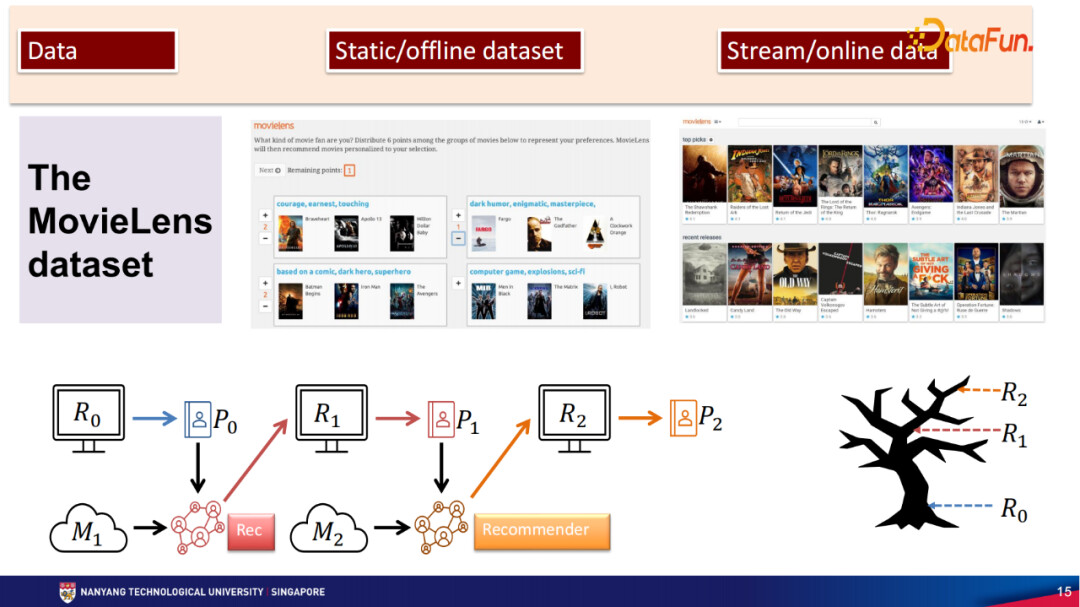
所以在MovieLens数据集中其实是反映了两种交互,第一种是User跟Movie之间的交互,这类交互说明用户看过这个电影,但是用户具体是在什么时候看的,是以什么方式看的,我们是不知道的。第二种交互是User跟MovieLens网站平台之间的交互,用户会在系统网页中给电影打分。我们拿到的MovieLens数据集也就是用户跟网站之间的打分交互,所以并不能体现用户当时决定去看这个电影的时候是怎么想的。比如Harry Potter系列一共有7部电影,花了10年的时间拍出来,用户也花了10年的时间看完整个系列,但是去打分的时候就只是在一天之内给这7部电影打分。所以在这个交互下得到的信息可能无法反映用户在现实中决定是否看电影的考量判断过程。总结下来用户跟MovieLens系统的交互更像是路边调查问卷,是一种电影喜好的总结。

基于上述情况, MovieLens数据集是一个冷启动的数据集,而不是一个完全模拟线上推荐系统的数据集。因此我们会怀疑在MovieLens数据集得到的结果跟在现实中得到的结果可能不一致。
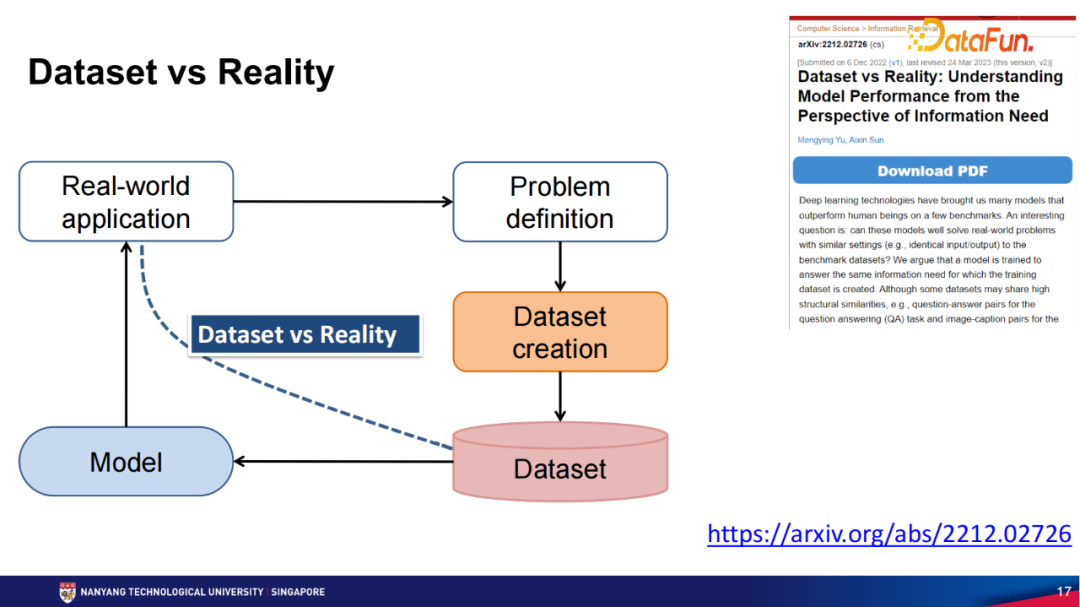
我们也有另外一篇文章专门去讨论数据集,以及数据集跟现实场景的差异。为了研究一个课题,我们会有一个很严格的问题定义,即定义要做的事情或要解决的问题,之后我们会根据这个问题定义去收集相应的数据集,需要清楚的是这个数据集本身是通过问题定义来确定怎么收集的,对应地,我们的模型完全是在这个数据集上学出来的。但是我们的模型无法看到实际的落地场景,所以这个模型是完全被数据集来定义的,如何正确使用数据集将决定模型能否更贴近现实。如果我们的数据集完美地反映了现实中的场景,并且我们测试的方式也完美地反映了现实中的场景,那么我们得到的模型就会在实际场景中更有效。
04 大模型在推荐系统的模型层面的定位问题
现在再来看一下本文探讨的主题,大模型是否是下一个推荐系统解决方案,这其实取决于大模型能否完全描述用户在一个线上场景做决策的情况。
下图是NLP领域的发展情况。刚开始的时候我们仅关注于word embedding,就是将文本转化成深度学习模型可以采用的一种输入模式。之后研究的重点变为具体应用而设计的模型结构。当语言模型有新进展时,例如BERT、RoBERTa等模型出现时,应用模型的具体结构就变得不是那么重要了,很多时候考虑的是BERT加一个判别层就达到一个很好的效果。当现在有了大语言模型之后,我们发现模型结构在很大程度上被简化成一种提示的或询问的形式,就是描述问题,让大模型给一个判断,这个时候应用模型结构就变得微乎其微了,更多的时候是去优化提示。当我们把这个场景应用到推荐时,核心问题在于如何去描述一个推荐问题的场景,然后将该描述输入给大模型,让它能够做出一定的判断。另一方面就是如果在推荐研究中用大模型作为一个推荐的解决方案,现有常用的离线评测在多大程度上能够反映了线上的落地场景。

最后来总结一下学术界对于大模型作为推荐系统解决方案的研究。其弱势在于,没有实际的推荐场景,也无法拿到实际用户或者item的具体属性,另外,在学术界也没办法仅仅通过离线测试得到算法能为整个落地场景带来怎样的收益。当然,其强项是不需要考虑落地成本,对模型设计也没有约束限制,只要能得到有一定价值的结果就可以,有些想法可能会给工业界提供一些参考或启发。

最后在这里也感谢我们的研究团队及合作者,纪依桐、范昱辰、张杰教授和李晨亮教授。本次分享的内容都来自我们近期发表的几篇文章。谢谢大家。
以上就是本次分享的内容,谢谢大家。