从版本3.1升级到3.6,一样是三台机器,但是新集群机器配置有所降低;
最近在做双跑,在数据量级差不多的情况下(点边都小于5亿),在夜间执行compact期间(compact耗时5分钟左右),读写最大耗时从老集群的几十ms升高到600ms+,新集群虽然机器配置有所降低,但是cpu,内存使用率应该都低于40%,算还有不少余量,为什么对耗时影响会大那么多呢?
compact时可能会有大量磁盘io,如果磁盘性能不够,会影响时延。以及版本升级后,如果graph space比较多,rocksdb按照新的方式拆分,也可能会因为overhead(比如锁)造成时延增加。
(可以试试看下执行计划的耗时
1 个赞
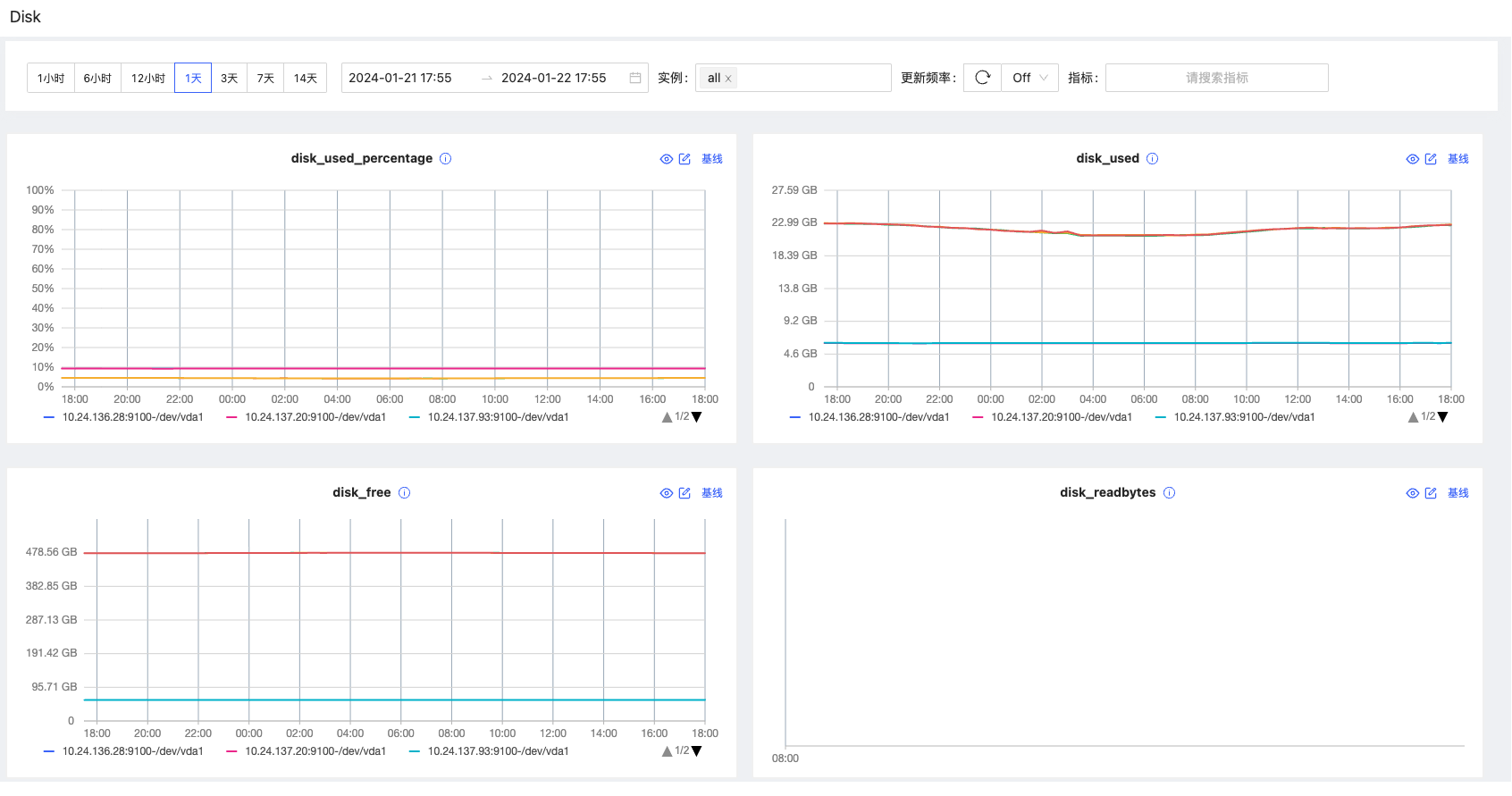
如上图
是多个space 一起compact 的吗? 我记得某个版本之前多个 space compact 是顺序排队的,后面改成并发了
并没有,只有单个图空间在compact
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。