版本3.6.0
数量级14w,硬盘顺序读写60MB,随机读写37MB,没有索引
NGQL:
查询某一部分:MATCH (v:player) return id(v) as pvid skip 128750 limit 10
查询总数: MATCH (v:player) return count(v) as count
问题:
查询某一部分时,skip最多时会达到8s的延迟;查询总数时,会有8s延迟。
已知:
原理我知道是基于log,但我想问的是我这种只需要查一个范围,没有任何过滤条件,那么有必要加索引吗(之前我给tag加索引没有作用),后续版本有没有考虑像nosql之类的数据库增加lsm树或者mysql之类的索引机制,能更快速的返回列表查询和总数记录快速返回呢?
另外我知道可以SHOW STATS可以快速查询总数,但是我需要实时知道总数时,又不可能每次都提交一个JOB STATS,这个job花费时间也不少
MATCH (v:player) return count(v) as count
扫描全表
MATCH (v:player) return id(v) as pvid skip 128750 limit 10
从头开始全表扫描 然后skip掉若干数据 所以skip越大 越接近全表扫描
一般来说,加索引对于找出特定类型(player)的点是有用的,但由于你的场景下不需要任何过滤条件,索引的作用大大减少。
TLDR:据我所知目前版本没有很好的办法拿实时总数
1 个赞
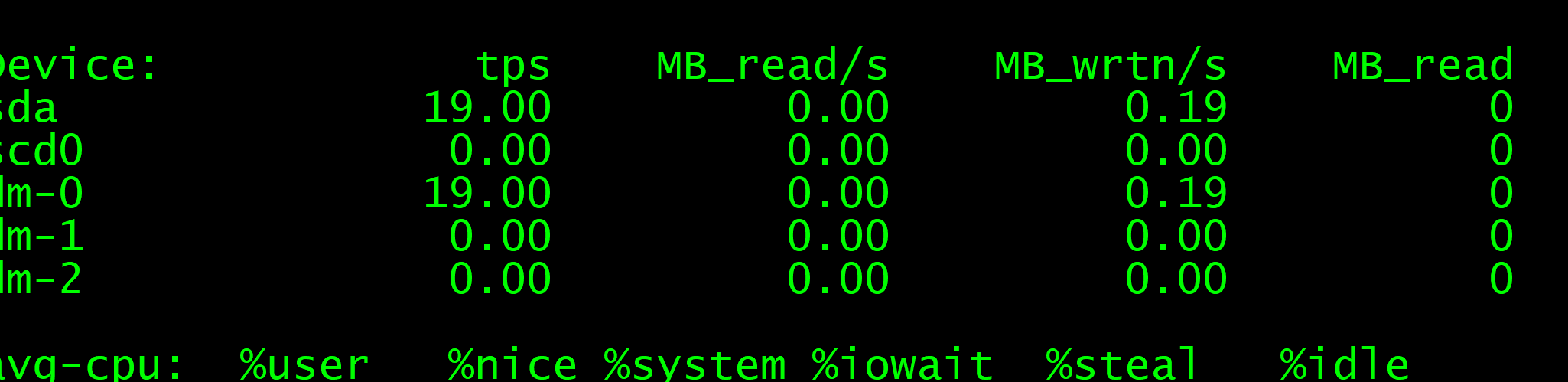
请教一下,我现在查询实例速度有点慢。
无查询语句时,skip 120000 limit 10,耗时6s,用iostat看磁盘读写只有0.20mb瞬时,缓存有几百兆,但耗时这么久感觉也不对劲。
有查询语句,有索引时,skip 0 limit 10,耗时6s,用iostat看磁盘读写只有0.04mb,缓存还是几百兆,耗时还是很久。
所以我应该怎么优化才能提高速度呀,这个索引底层是不是数据库常用的索引树呀
steam
5
正如上面的 critical27 说的,你的查询是全表扫描数据,所以你 limit 后面是 0 还是 100,是没有任何区别的,因为limit 没有下推,是捞所有数据之后做的 limit。
不过严谨点来说,你可以在你的语句前面加一个 profile,看下生成的执行计划中到底哪个地方用到了大量数据以及耗时久。
system
关闭
6
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。