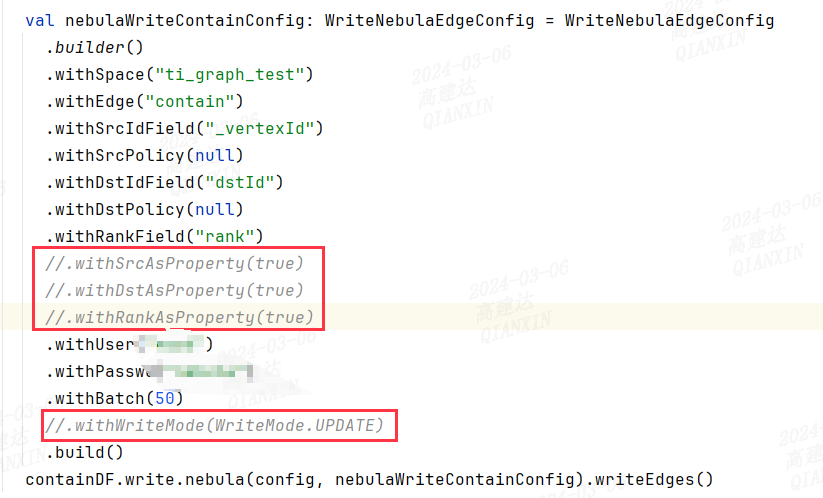
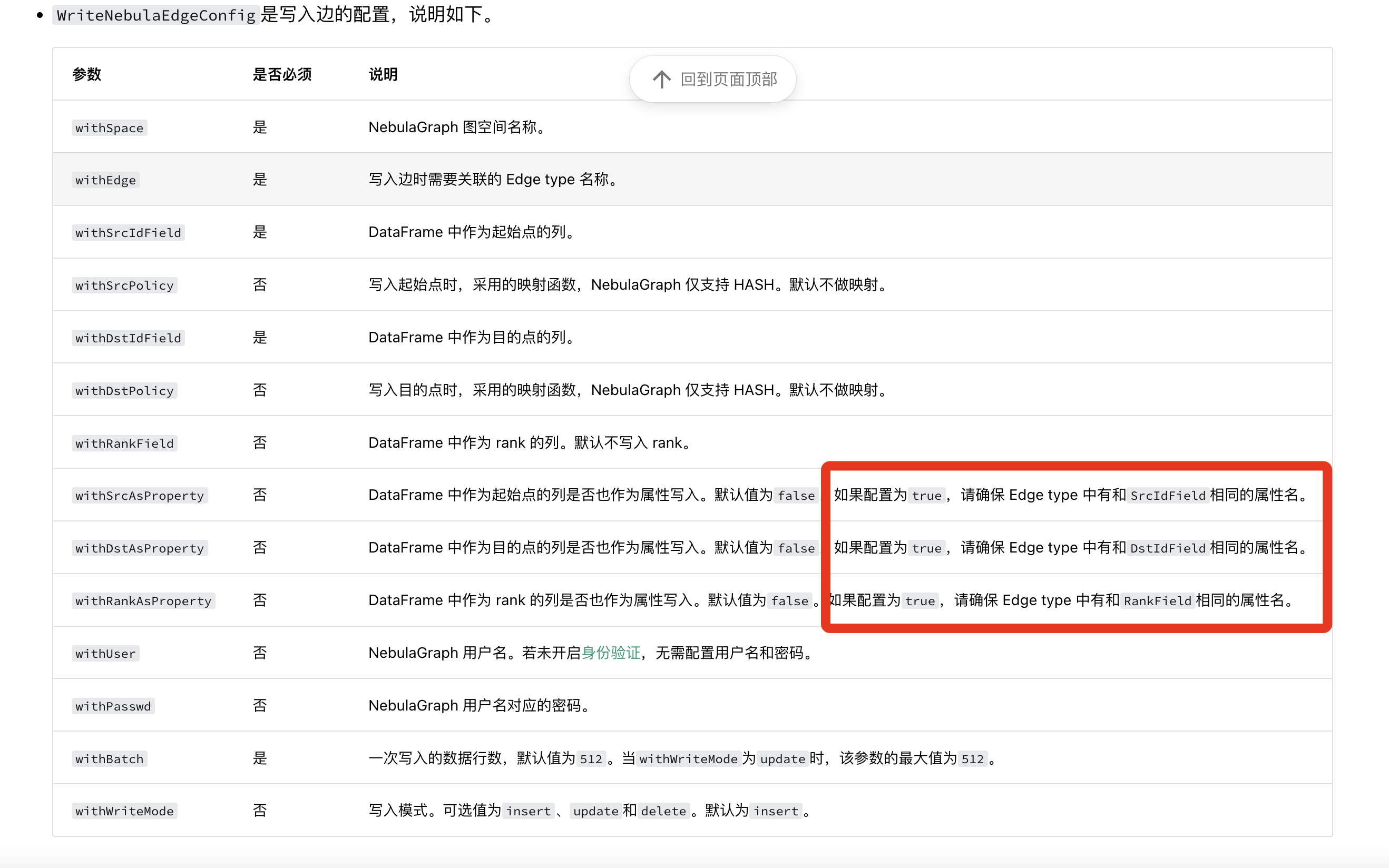
最近在使用spark-connector来将HDFS上的数据导入到nebula,但是在使用spark-connector时遇到问题:图片中带框的部分指的是使用DF中对应的列名吗?
我在编写对应代码的时候,将DF的列名设置成了如下的格式:
该EDGE的创建语句为:
CREATE EDGE connect ( action string NULL, ts timestamp NULL, port string NULL, label string NULL ) ttl_duration = 0, ttl_col = “”
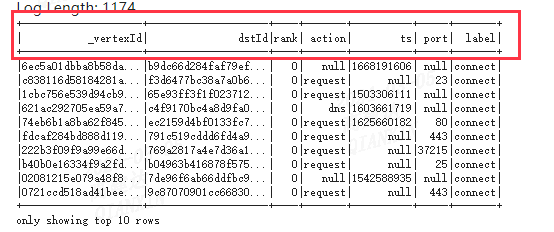
spark运行日志显示:

代码部分:
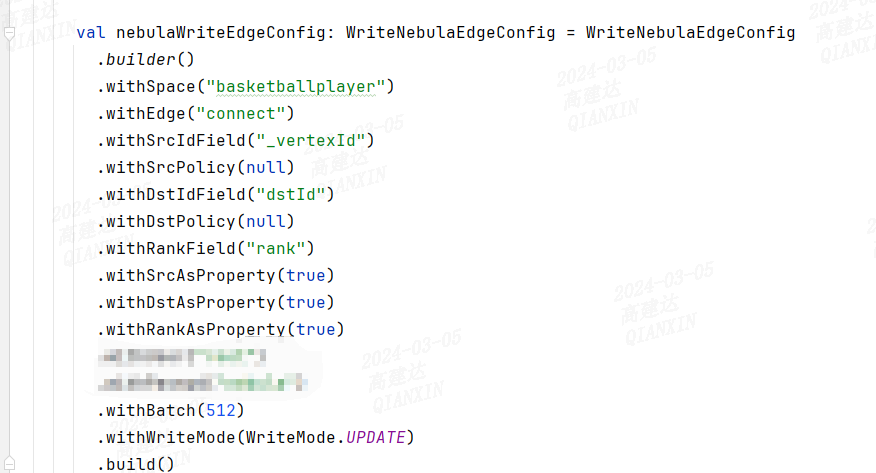
主要就是不知道DF中的列名和edge的schema通过哪里设置给它对应起来。