match (c:person)-[r1:tend_city]->(i:city) where i.city.name=="深圳" with c
match (c:person)-[r1:have_skill]->(s:skill) where s.skill.name =="Java" with c
match (c:person)-[r1:have_gackground]->(e:education_background) where e.education_background.name == "本科" with c
match (c:person)-[r1:study_major]->(m:major) where m.major.name in ["计算机科学","软件工程"] with c match (c:person)-[r1:have_degree]->(d:degree) where d.degree.name in ["学士","硕士"]
return c.person.name as person;
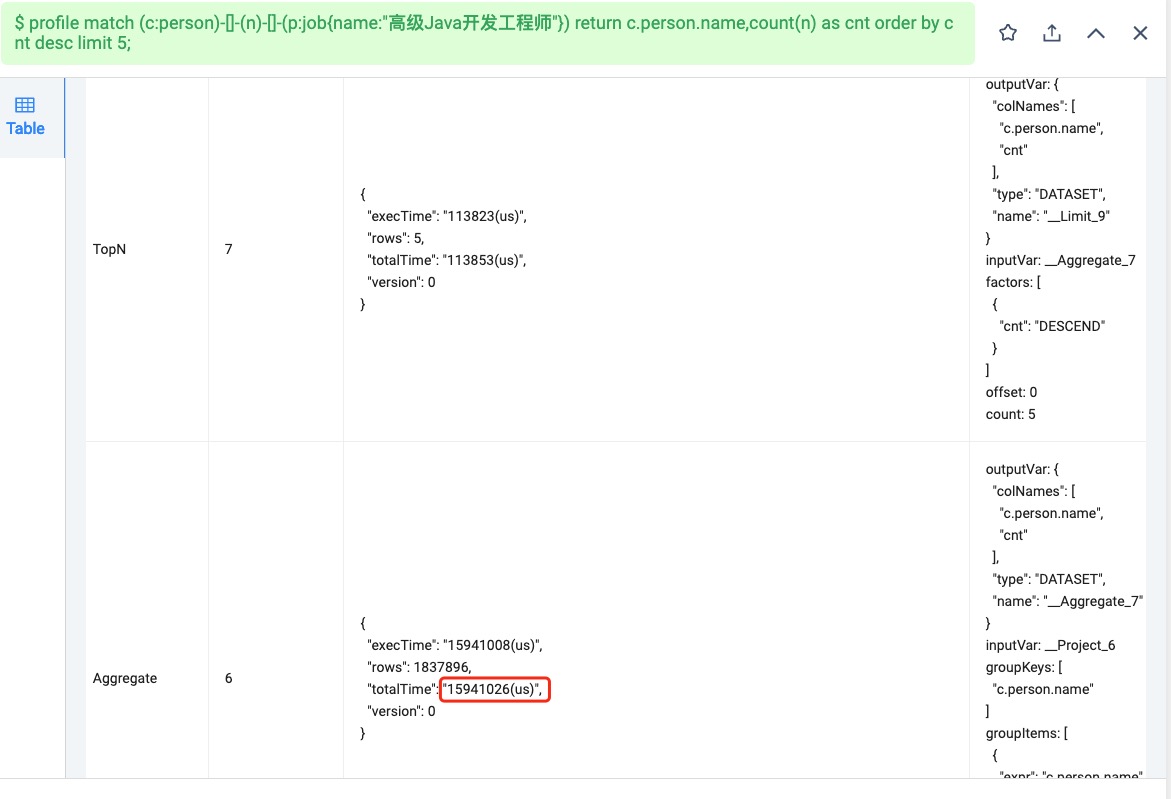
需要 4.3 秒,跑 match (c:person)-[]-(n)-[]-(p:job{name:"高级Java开发工程师"}) return c.person.name,count(n) as cnt order by cnt desc limit 5;需要 73 秒,
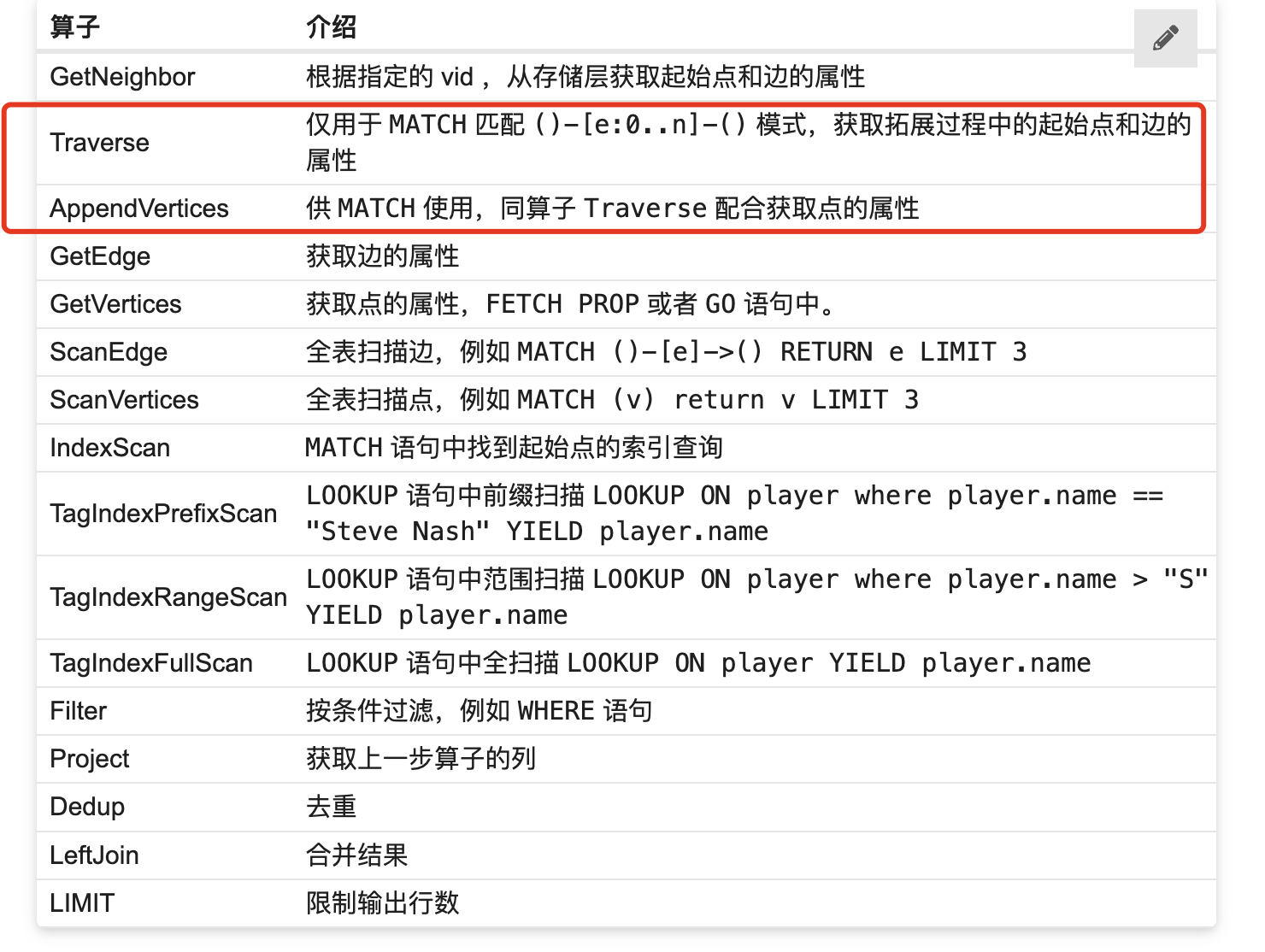
好的,这是顶点数500多万,边数4000万,profile match (c:person)--(n)--(p:job{name:“高级Java开发工程师”}) return c.person.name,count(n) as cnt order by cnt desc limit 5;的执行计划。 result.csv (25.9 KB)
profile match (c:person)-[:except_post|have_degree|have_gackground|have_manage_experience|have_skill|study_course|study_major|tend_city]-(n)-[:provide_post|require_course|require_degree|require_education_background|require_major|require_manage_experience|require_skill|require_work_city]-(p:job{name:"高级Java开发工程师"}) return c.person.name,count(n) as cnt order by cnt desc limit 5;
由于业务中其他的tag和edgetype都是person和job这两个tag的关联点和边,因此中间的-(n)-包含了剩余的所有tag和edgetype,以下是我指定了edgetype后的语句和执行计划,还是很慢
profile match (c:person)-[:except_post|have_degree|have_gackground|have_manage_experience|have_skill|study_course|study_major|tend_city]-(n)-[:provide_post|require_course|require_degree|require_education_background|require_major|require_manage_experience|require_skill|require_work_city]-(p:job{name:“高级Java开发工程师”}) return c.person.name,count(n) as cnt order by cnt desc limit 5; result.csv (7.8 KB)
应该把 city 的深圳做为 vid,skill 的 name 的 java 做为 vid,background 的 name ,major 的 name 都做为 vid,通过 vid 查询效率会高很多
2.第二个的查询应该是有向的?建议把边的方向加上。
第一条语句你改成:
match (c:person)-[r1:tend_city]->(i:city) where id(i) ==“深圳” match (c:person)-[r1:have_skill]->(s:skill) where id(s)=“Java” match (c:person)-[r1:have_gackground]->(e:education_background) where id(e) == “本科” match (c:person)-[r1:study_major]->(m:major) where id(m) in [“计算机科学”,“软件工程”] match (c:person)-[r1:have_degree]->(d:degree) where id(d) in [“学士”,“硕士”] return c.person.name as person;