steam
2
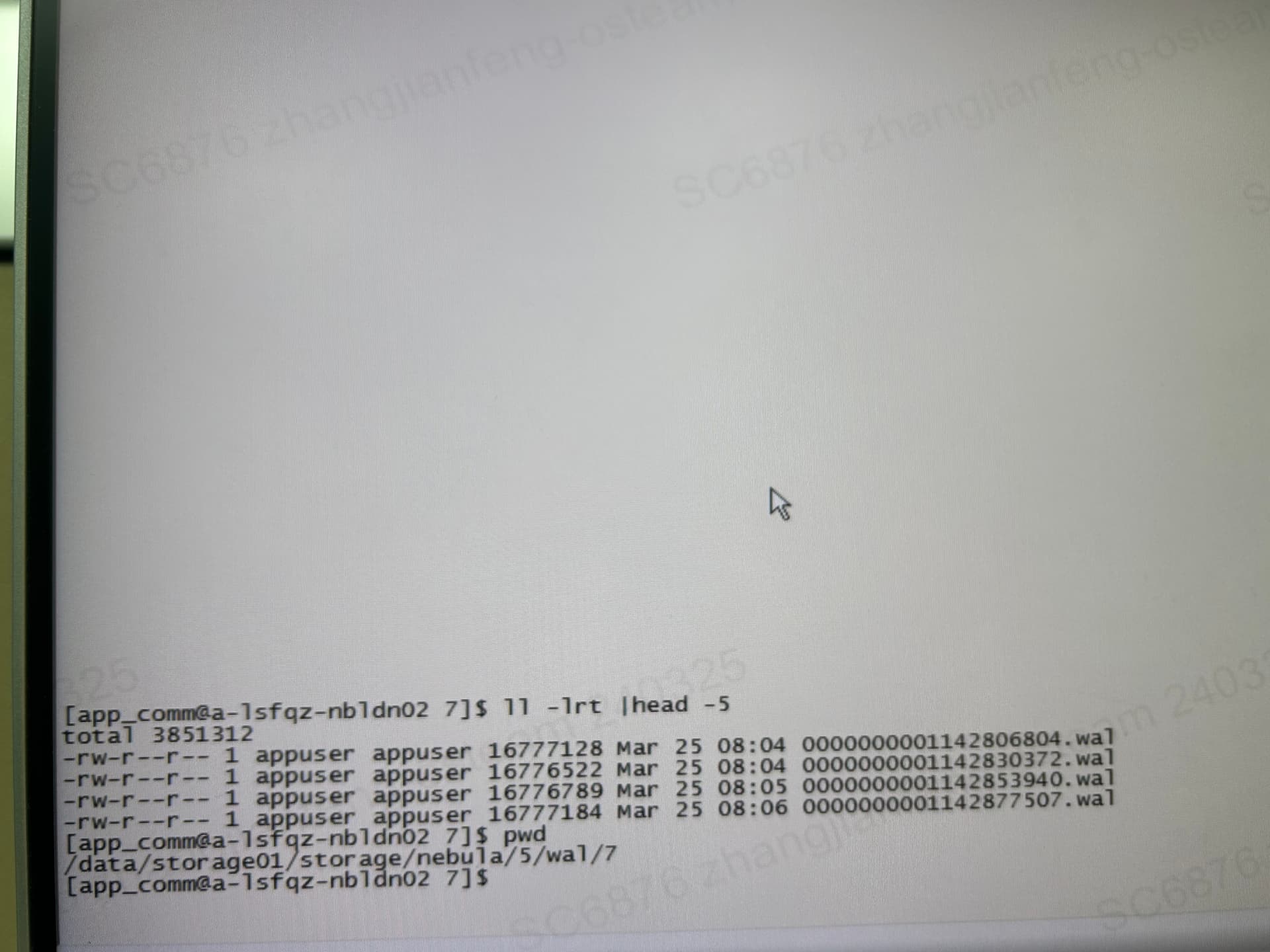
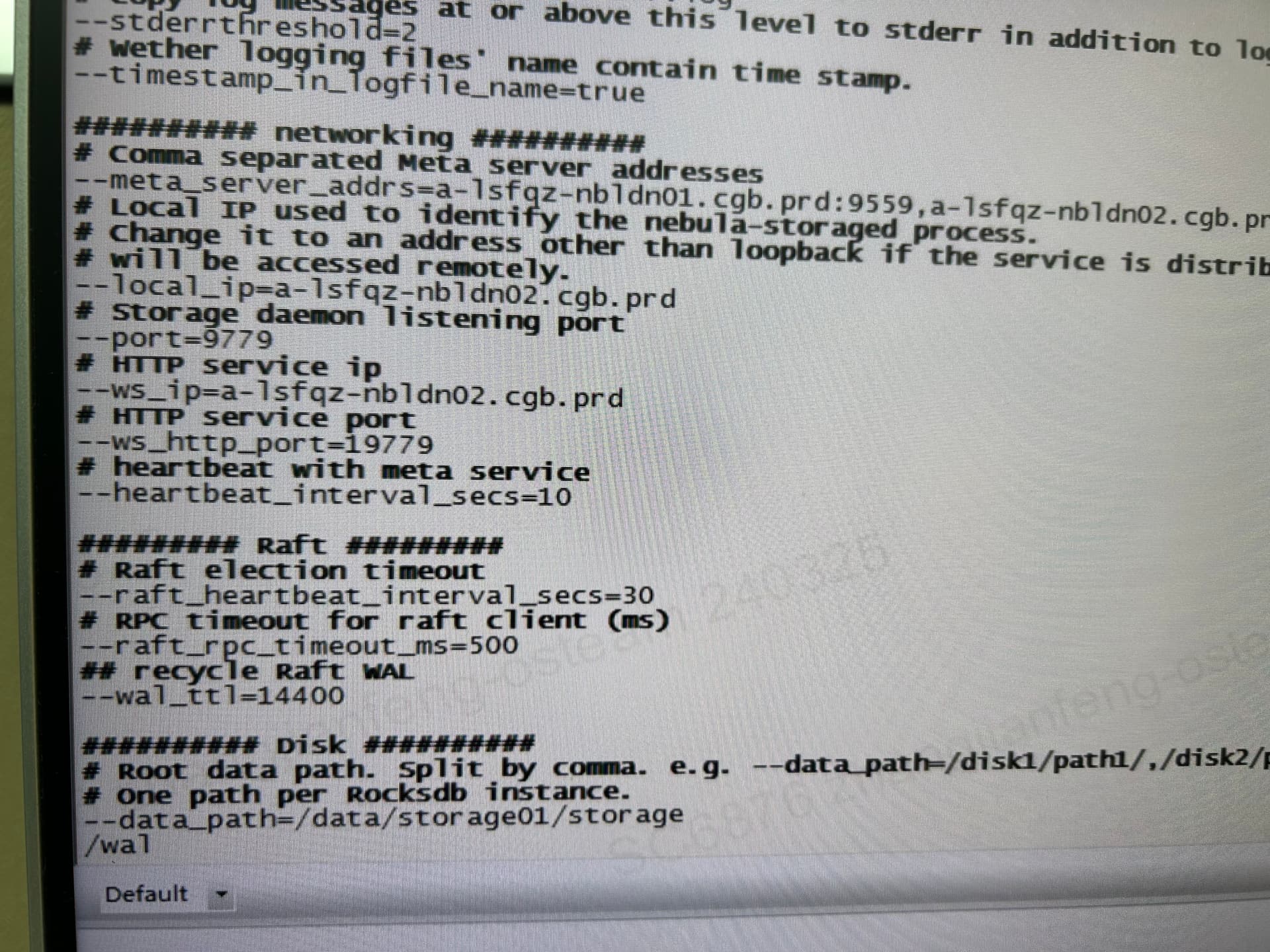
看 wal 的日志是 4 小时过期,这里已经过了 4 小时是么?
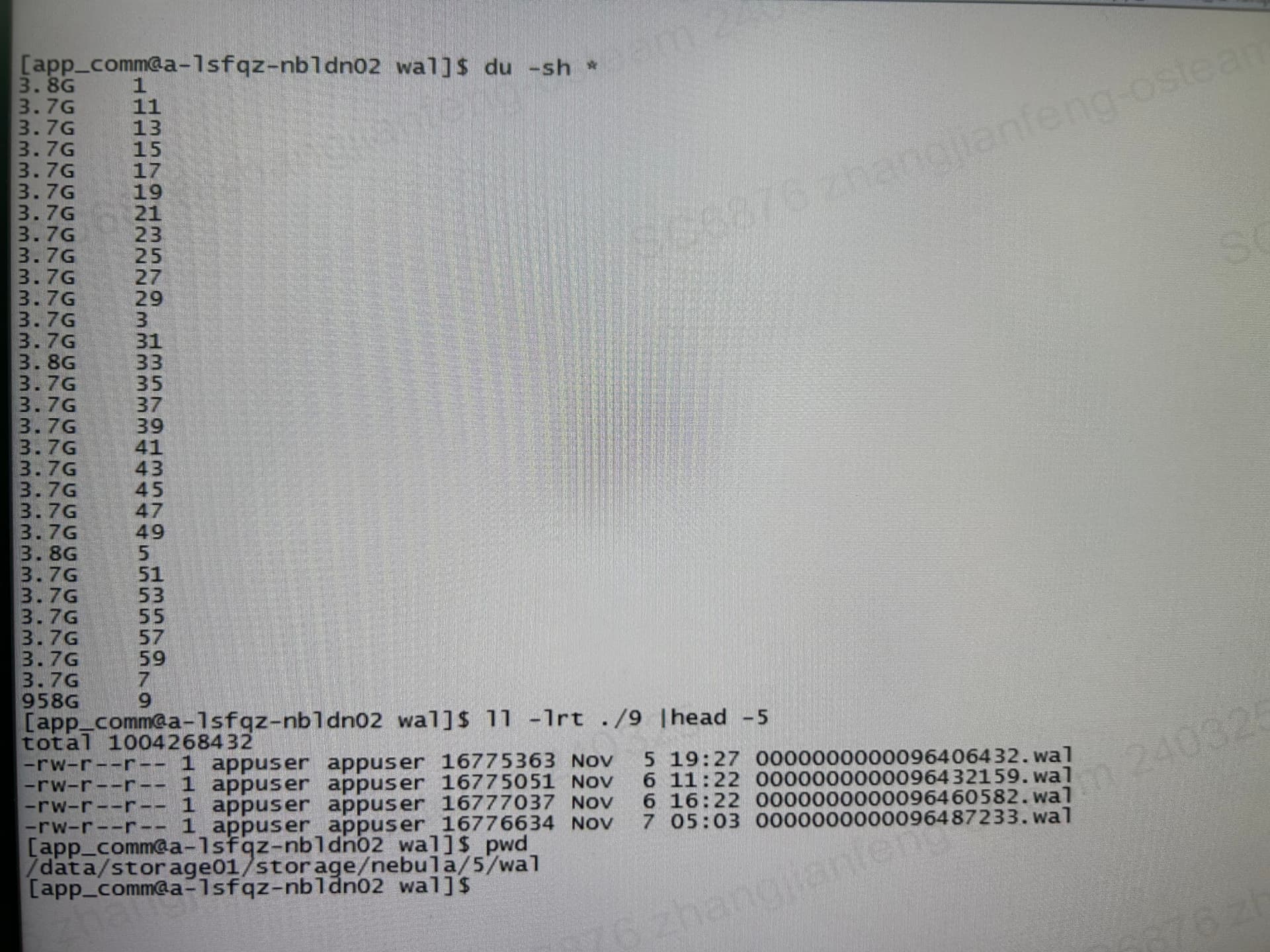
如图2所示,有问题的分片从23年11月直到现在所有wal日志都没删除。
steam
4
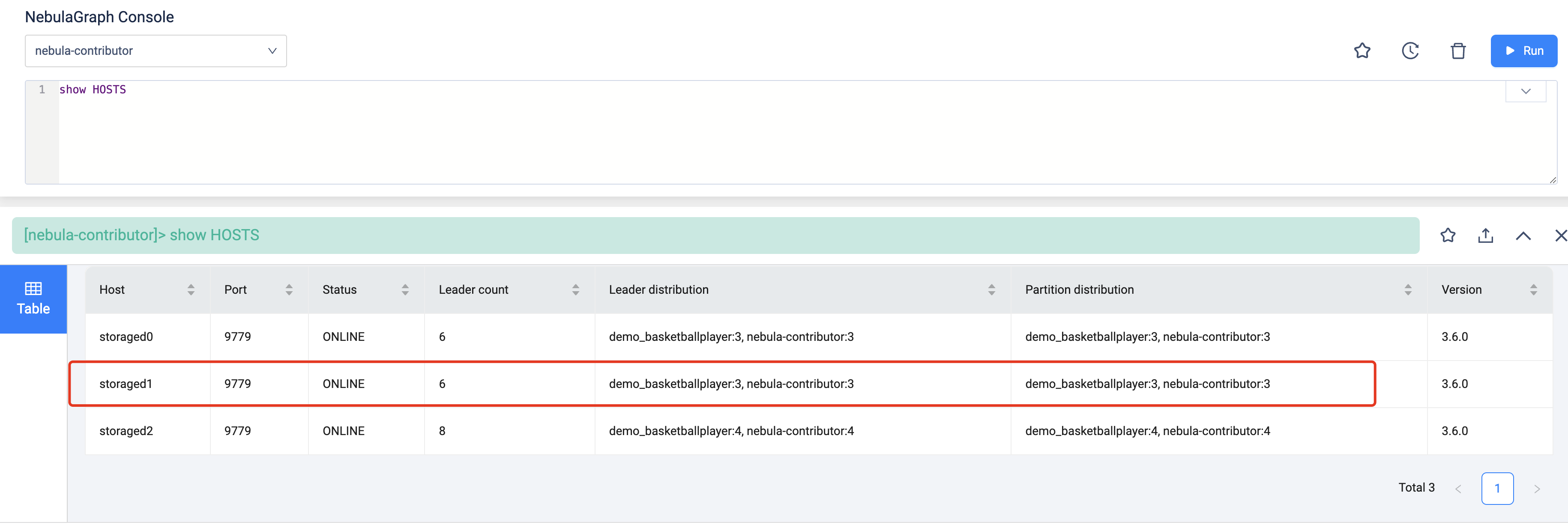
你 show hosts 看下,看下目前的图空间分布;
比如此时的 storage1 是你有问题的 partition 所在的机器,然后你找到这个机器所有的图空间数据,分别去这些图空间执行下 SHOW PARTS
看下这个分别是不是有数据在上面,没有的话重启下机器,可能就清理掉 wal 日志了。
有问题的partition所在机器是有数据在上面的。是否按照你说的重启就可能清理掉wal日志?另外这个重启是指重启storage服务吗?
重启storage需要备份吗?目前nebula集群是配了3副本的,应该不需要备份把?另外如果说storage重启后还是没触发wal清理是否需要手动删除。
wal自动清理这块有在日志里体现吗?如果有的话日志关键字是什么?谢谢
steam
9
刚咨询过研发,他是说你重启的话,理论上这个日志会被清理的。 我让他空了再来帖子里补充下注意事项。
我让他空了再来帖子里补充下注意事项。
生产上重启此节点后,wal日志还是没正常清理。请问还有什么方法可以解决吗。
system
关闭
11
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。