本文来自我的个人公众号:https://mp.weixin.qq.com/s/Y_0EvkTTbb8tbth7gk2mXQ
本文翻译自:
大型语言模型 (LLM) 的第一波炒作来自 ChatGPT 和类似的基于网络的聊天机器人,相信在座的各位都并不陌生了,甚至不少人也已经以不同的方式试用过它的功能,这些模型非常擅长理解和生成文本,但是也存在一些问题。
LLM 的一大问题是所谓的知识截止。知识截止术语表明大模型不知道训练后发生的任何事件。例如,如果我们向 ChatGPT 询问 2023 年的事件,我们将得到以下响应。
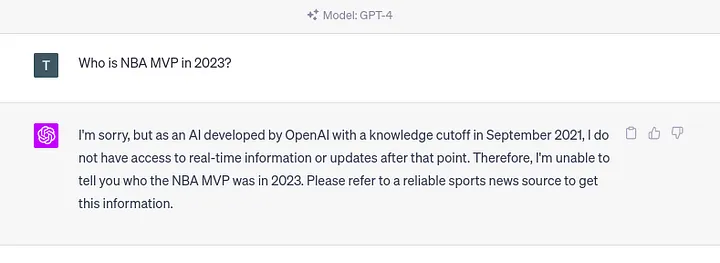
如果我们向大模型询问其训练数据集中不存在的事件,也会出现同样的问题。因为大模型不仅无法获取知识截止日期以后的知识,也不了解任何可能可用的私人或机密信息。更不用说大模型知道的许多公开信息可能已经过时了。
因此,更新和扩展大模型的知识在今天非常重要。
大模型的另一个问题是,他们接受的训练是尽可能生成听起来逼真的文本,但这些文本可能并不准确。有些虚假的信息比其他信息更难发现。特别是对于缺失的数据,LLM 很可能会编造一个听起来令人信服但实际上是错误的答案,也就是我们所说的大模型会产生幻觉。
因此,我们在使用时必须非常小心,不要盲目相信大模型所提供的一切。验证大模型的答案或产生更准确的结果是另一个需要解决的大问题。
当然,大模型还有其他问题,比如偏见、快速注入等等。不过,我们不会在这里讨论它们。在这篇文章中,我们将介绍并重点讨论微调和检索增强大模型(RAG)的概念,并评估它们的优缺点。
01 LLM 的监督微调
我们可以通过提供额外的问答对在监督训练阶段微调大模型,以此来优化大模型的性能。
此外,我们还确定了两种不同的方法来微调大模型。
一个方法是微调模型以更新和扩展其内部知识。
另一个方法侧重于针对特定任务(例如文本摘要或将自然语言翻译为数据库查询)微调模型。
首先,我们将讨论第一个方法,使用微调技术来更新和扩展大模型的内部知识。
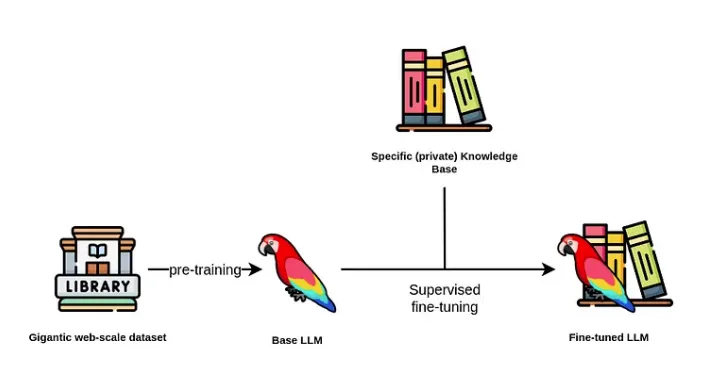
通常,大多数人倾向于使用已经预训练好的基础大模型,以此避免对大模型进行预训练。因为基础大模型需要使用庞大的文本语料库进行预训练的,通常有数十亿甚至数万亿个标记,这意味着成本可能高达数十万甚至数百万美元。
选择基础大模型后,便可以开始下一步对其进行微调。由于 LoRa 和 QLoRA 等可用技术,微调这一步骤的成本相对便宜。
然而,构建训练数据集更加复杂并且可能会变得昂贵。如果负担不起聘请专门的注释团队的费用,使用 LLM 构建训练数据集来微调想要的 LLM 是一个比较好的选择。
例如,斯坦福大学的 Alpaca 训练数据集就是使用 OpenAI 的大模型创建的。制作5.2万份训练说明的成本约为500美元,相对比较便宜。

Vicuna 模型是通过从 ShareGPT 收集的用户共享对话来对大模型进行微调。

H2O 还有一个相对较新的项目,名为 WizardLM,旨在将文档转换为问答对,可用于微调 LLM。
我们有一些利用大模型从知识图谱上下文构建问答对的想法。
然而,目前还有很多未知数。例如,能否为同一问题提供两个不同的答案,然后大模型以某种方式将它们组合到内部知识库中?
另一个考虑因素是,如果不考虑其关系,知识图中的某些信息是不相关的。因此,我们是否必须预先定义相关查询,或者是否有更通用的方法来实现?或者我们可以使用表示主语-谓语-宾语表达式的节点-关系-节点模式来生成相关对吗?
想象一下,我们以某种方式设法根据知识图谱中存储的信息生成包含问答对的训练数据集并对大模型进行微调,因此现在大模型包含了更新的知识。但是,对模型进行微调并没有解决知识截止问题,因为它只是将知识截止推迟到了更晚的日期。
因此,建议仅在数据更新的速度较缓的情况下通过微调技术来更新 LLM 的内部知识。例如,我们可以使用微调模型来提供旅游信息。
然而,当我们想要在响应中包含特定时间(实时)的内容或个性化的促销活动时,我们就会遇到麻烦。同样,微调模型并不适合分析工作流程,例如在分析工作流程中我们会询问公司在上周获得了多少新客户。
除了知识截止问题,目前微调还可以帮助减轻幻觉,但不能完全消除它们。
一方面原因在于大模型在提供答案时没有引用其来源。因此,你不知道答案是来自预训练数据、微调数据集,还是大模型编造的。
另一方面,如果我们使用 LLM 创建微调数据集,则可能存在另一个可能的虚假来源。
最后,经过微调的模型无法根据提出问题的用户自动提供不同的响应。同样,不存在访问限制的概念,这意味着与大模型互动的任何人都可以访问其所有信息,所以从根本上大模型就不能够获取机密信息。
02 检索增强生成(RAG)
大模型在自然语言应用程序中表现非常好,例如:文字概括、提取相关信息、实体消歧、从一种语言翻译成另一种语言,甚至可以将自然语言转换为数据库查询或脚本代码。
此外,以前的 NLP 模型通常是特定于领域和任务的,这意味着我们很可能需要根据我们的用例和领域来训练自定义自然语言模型。然而,由于大模型的泛化能力,单个模型可以应用于解决各种任务集合。
我们观察到使用检索增强大模型的强烈趋势,我们不再使用大模型来访问其内部知识,而是使用大模型作为我们的公司或私人信息的自然语言接口。
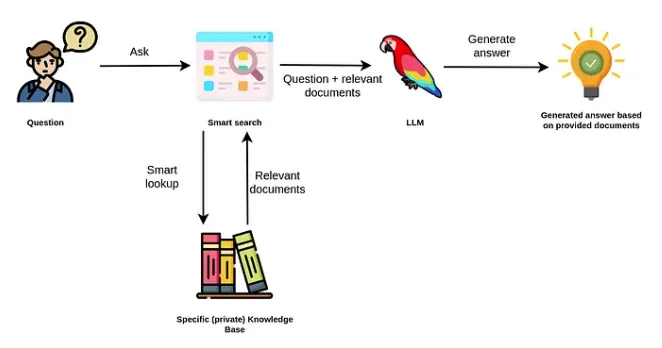
RAG 使用大模型根据数据源中额外提供的相关文档生成答案。
因此,我们不必依赖大模型的内部知识来得出答案。相反,大模型仅用于从我们传入的文档中提取相关信息并进行总结。

例如,ChatGPT 插件可以被视为 LLM 应用程序的 RAG。启用浏览插件的 ChatGPT 界面允许大模型搜索互联网以访问最新信息并使用它来构建最终答案。
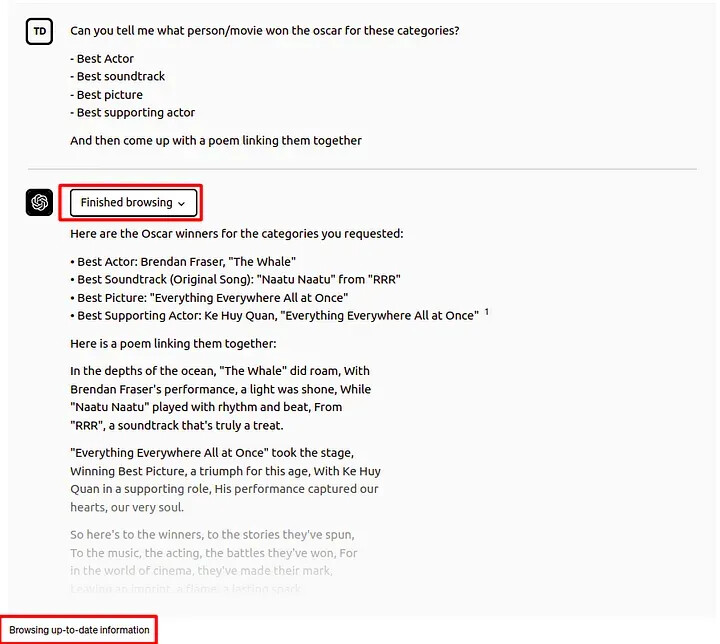
在这个例子中,ChatGPT 能够回答谁赢得了 2023 年各个类别的奥斯卡奖。但是,请记住,ChatGPT 的截止知识日期是 2021 年,因此它无法从其内部知识知道谁赢得了 2023 年奥斯卡奖。因此,它是通过浏览插件访问外部信息,以使得它能够用最新的信息来回答问题。这些插件在 OpenAI 平台内提供了一个集成的增强机制。
如果一直在关注 LLM 领域,可能听说过 LangChain 库。我们之前也有出过一篇文章来介绍如何使用。
它就能作为插件来增强大模型。
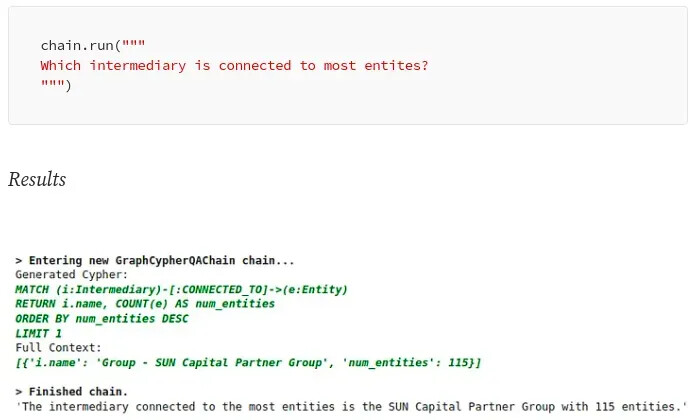
LangChain 库可用于允许大模型从各种来源(例如 Google 搜索、矢量数据库或知识图谱)访问实时信息。例如,LangChain 添加了 Cypher 搜索链,它将自然语言问题转换为 Cypher 语句,用它从图数据库中检索信息,并根据提供的信息构造最终答案。

通过 Cypher 搜索链,LLM 不仅用于构建最终答案,还用于将自然语言问题翻译为 Cypher 查询。
另一个用于检索增强 LLM 工作流程的流行库是 LlamaIndex (GPT Index)。LlamaIndex 是一个综合数据框架,旨在通过使大型语言模型 (LLM) 能够利用私有或自定义数据来增强其性能。
首先,LlamaIndex 提供数据连接器,方便摄取各种数据源和格式,涵盖从 API、PDF、文档到 SQL 或图形数据的所有内容。此功能可以轻松地将现有数据集成到大模型中。
其次,它提供了使用索引和图表构建摄取数据的有效机制,确保数据得到适当安排以供大模型使用。
此外,它还包括一个高级检索和查询界面,使用户能够输入 LLM 提示并接收回上下文检索的知识增强输出。
ChatGPT 插件和 LangChain 等检索增强的 LLM 应用程序背后的想法是避免仅依赖内部 LLM 知识来生成答案。相反,大模型用于解决诸如从自然语言构建数据库查询以及基于外部提供的信息或利用插件/代理进行检索构建答案等任务。
与微调方法相比,RAG 具有一些明显的优势:
答案可以引用其信息来源,这使我们可以验证信息并可能根据要求更改或更新基础信息
不太可能产生幻觉,因为我们不依赖大模型的内部知识来回答问题,而仅使用相关文件中提供的信息
当我们将问题从 LLM 维护转换为数据库维护、查询和上下文构建问题时,更改、更新和维护 LLM 使用的基础信息会变得更加容易
可以根据用户上下文或其访问权限对答案进行个性化
另一方面,在使用检索增强方法时,我们应该考虑以下限制:
- 答案取决于智能搜索工具
- 应用程序需要访问我们的特定知识库,无论是数据库还是其他数据存储
- 完全无视语言模型的内部知识限制了可以回答的问题数量
有时大模型无法遵循指示,因此如果在上下文中找不到相关答案数据,则存在上下文可能被忽略或出现幻觉的风险。
总结
这篇文章深入探讨了大型语言模型 (LLM) 的局限性,例如:知识截止,幻觉,以及缺乏用户定制。
为了克服这些问题,我们了解了两个概念,即大模型的微调和检索增强生成(RAG)。
克服大模型局限性的第一种方法是微调。大模型的微调涉及监督训练阶段,其中提供问答对来优化大模型的表现。这可用于更新和扩展大模型的内部知识或针对特定任务对其进行微调。
然而,微调并不能解决知识截止问题,因为它只是将截止日期推后。它也不能完全消除幻觉。因此,我们建议对缓慢变化的数据集使用微调方法,其中允许出现一些幻觉。由于微调大模型相对较新,我们渴望了解更多有关微调方法和最佳实践的信息。
克服大模型局限性的第二种方法是所谓的检索增强生成,其中大模型充当访问外部信息的自然语言接口,从而不仅仅依赖其内部知识来产生答案。检索增强方法的优点包括引用来源、可忽略的幻觉、易于更改和更新信息以及个性化。
然而,它严重依赖智能搜索工具来检索相关信息,并且需要访问用户的知识库。此外,它只能回答查询,前提是它具有解决问题所需的信息。
我们可以根据自己的需要来选择适合自己的方法。
拓展阅读
- Knowledge Graphs & LLMs: Harnessing Large Language Models with Neo4j | by Oskar Hane | Neo4j Developer Blog | Medium
- https://youtu.be/bZQun8Y4L2A
- Using LoRA for Efficient Stable Diffusion Fine-Tuning
- Stanford CRFM
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality | LMSYS Org
- Getting Started with LangChain: A Beginner’s Guide to Building LLM-Powered Applications | by Leonie Monigatti | Towards Data Science
- LangChain has added Cypher Search | by Tomaz Bratanic | Towards Data Science
- LlamaIndex on TWIML AI: A Distilled Summary (using LlamaIndex) — LlamaIndex, Data Framework for LLM Applications