本文来自我的大规模数据系统专栏《系统日知录》,专注存储、数据库、分布式系统、AI Infra 和计算机基础知识。欢迎订阅支持,解锁更多文章。你的支持,是我前行的最大动力。
主要“编译”自书籍《Operating Systems: Three Easy Pieces[1]》第 40 章,这是一本非常深入浅出的书,推荐给所有对操作系统感到迷茫的同学。本文件系统基于一个非常小的硬盘空间,以数据结构和读写流程为主线,从零到一的推导出各个基本环节,可以帮你快速建立起对文件系统的直觉。
文件系统基本都是构建于块存储之上的。但当然,现在的一些分布式文件系统,如 JuiceFS[2],底层是基于对象存储的。但无论块存储还是对象存储,其本质都是按 “数据块” 进行寻址和数据交换的。
我们首先会探讨一个完整的文件系统在硬盘上的数据结构,也即布局;然后再通过打开关闭、读写流程将各个子模块串起来,从而完成对一个文件系统要点的覆盖。
总体布局
假设我们的块大小是 4KB,然后有一块非常小的硬盘,只有 64 个块(则总大小为 64 * 4KB = 256KB),且该硬盘只给文件系统用。由于硬盘是按块进行寻址的,则地址空间为 0~63 。

图注:就这么点空间的迷你硬盘
基于此迷你硬盘,我们一起来逐步推导下这个极简文件系统。
文件系统的首要目的肯定是存储用户数据,为此我们在磁盘留出一块数据区(Data Region)。假设我们使用后面 56 个块作为数据区。为什么是 56 个呢?从后面就可以知道,其实是可以算出来的——我们可以大致算出元信息和真正数据的比例,进而可以确定两部分大小。
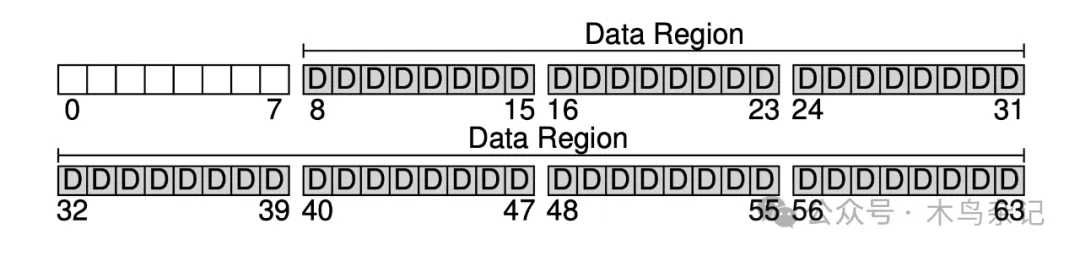
图注:隔出来数据区
接下来,我们需要为系统中的每个文件保存一些元信息,比如:
- 文件名
- 文件大小
- 文件归属者
- 访问权限
- 创建、修改时间
等等。保存这些元信息的数据块,我们通常称为 inode (index node)。如下,我们给 inode 分配 5 个 block。
!

图注:隔出来索引区
元信息所占空间相对较小,比如 128B 或者 256B,我们这里假设每个 inode 占用 256B。则每个 4KB 块能容纳 16 个 inode,则我们的文件系统最多可以支持 5 * 16 = 80 个 inode,也即我们的迷你文件系统最多可以支持 80 个文件,但由于目录也要占 inode,所以实际可用文件数要少于 80。
现在我们有了数据区,有了文件元信息区,但在一个正常使用的文件系统中,还需要追踪哪些数据块被用了,哪些还没有被使用。这种数据结构我们称之为分配结构(allocation structures)。业界常用的方法有空闲链表(free list),即把所有空闲块按链表的方式串起来。但为了简单,这里使用一种更简单的数据结构:位图(bitmap),数据区用一个,称数据位图(data bitmap);inode 表用一个,称 inode 位图(inode bitmap)。
位图的思想很简单,即为每一个 inode 或者数据块使用一个数据位,来标记是否空闲:0 表示空闲,1 表示有数据。一个 4KB 的 bitmap 最多能追踪 32K 的对象。为了方便,我们给 inode 表和数据池各分配一个完整的块(虽然用不完),于是便有了下图。
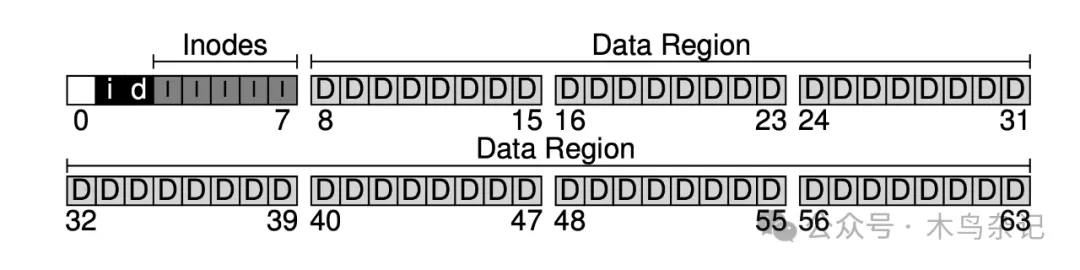
图注:造两个 map 作为空闲列表
可以看出,我们的基本思路是从后往前进行数据布局,最后还剩一个块。该块我们是故意留的,用以充当文件系统的超级块(superblock)。超级块作为一个文件系统的入口,通常会保存一些文件系统级别的元信息,比如本文件系统中有多少个 inode 和数据块(80 和 56),inode 表的起始块偏移量(3),等等。

图注:最后一个 block 是入口,称为超级块
则当文件系统被装载( mount )时,操作系统会首先读取超级块(所以放最前面),并据此初始化一系列参数,并将其作为数据卷挂载到文件系统树中。有了这些基本信息,当该卷中的文件被访问到时,就能逐步找出其位置,也就是我们之后要讲的读写流程。
但在讲读写流程之前,需要先放大一些关键数据结构看看其内在布局。
索引节点(Inode)
inode 是索引节点(index node)的简称,是对文件和文件夹的索引节点。为了简单,我们使用数组来组织索引节点,每个 inode 会关联一个编号(inumber),也即其在数组中的下标(偏移量)。
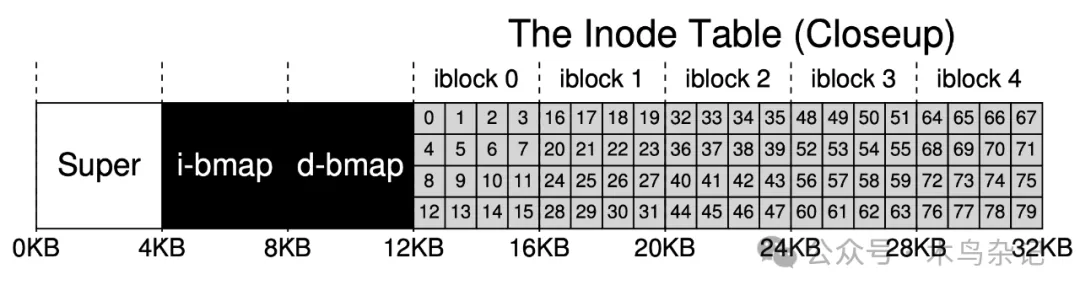
图注:索引区的详细布局
上面提到过一嘴,每个 inode 占 256B。则给定一个 inumber,我们就可以计算出其在硬盘中的偏移量(12KB + inumber * 256),但由于内外存交换是按块来的,我们可以据此进而计算出其所在磁盘块。
inode 主要保存文件名、一些元信息(权限控制、各种事件、一些标记位)和数据块索引。数据块索引其实也是元信息,单拎出来说是因为它很重要。
我们使用一种比较简单的索引方式:间接指针(indirect pointer)。即 inode 中保存的不是直接指向数据块的指针,而是指向一个指针块(也在数据区分配,但保存的都是二级指针)。如果文件足够大,可能还会引出三级指针(至于我们这个小系统是否用的着,大家可以估算下)。
但我们统计发现,在大多数文件系统中,小文件占多数。小到什么地步呢?一个数据块就可以存下。

因此实践中,我们在 inode 中使用一种直接指针和间接指针混合的方式进行表示。在我们的文件系统中,就是使用 12 个直接指针和 1 个间接指针。所以只要文件尺寸不超过 12 个数据块,就可以直接用直接指针。只有过大时,才使用间接指针,并且在数据区新分配数据块,来存间接指针。
我们的数据区很小,只有 56 个 block,假设使用 4byte 进行索引。则二级指针最多可支持 (12 + 1024) · 4K ,也就是 4144KB 大小的文件。
另一种实践中常用的方式是数据段(extents)。即将每个连续数据区用起始指针和大小来表示,然后将一个文件的所有数据段串起来。但多段数据时,如果想访问最后一个数据段或者随机访问,性能会很差(下一个数据段的指针都保存在上一个数据段中)。为了优化访问速度,常将该数据段的索引链表存在内存中。Windows 的早期文件系统 FAT 就是这么干的。
目录组织
在我们的文件系统中,目录组织得很简单——即和文件一样,每个目录也占用一个 inode,但在 inode 指向的数据块不是存文件内容,而是存储该目录中所包含的所有文件和文件夹的信息,通常是用 List<entry name, inode number> 表示。当然要转为实际编码,还要存文件名长度等信息(因为文件名是变长的)。
看一个简单例子,设我们有一个文件夹 dir (inode 编号是 5),里面有三个文件(foor,bar 和 foobar),其对应的 inode 编号分别是 12,13 和 24 。则在该文件夹的数据块中存储的信息如下:

图注:dir 内容的编码
其中 reclen (record length)是文件名所占空间大小,strlen 是实际长度。点和点点是指向本文件夹和上级文件夹的两个指针。记录reclen 看着有点多此一举,但要考虑到文件删除问题(可以用特殊的 inum,比如 0 来标记删除)。如果文件夹下的某个文件或者目录被删除,存储就会出现空洞。reclen 的存在,可以让删除留下的空洞为之后新增的文件复用。
需要说明的是,线性的组织一个目录中的文件是最简单的方式。实践中,还有其他方式。比如说在 XFS 中,如果目录中文件或者子文件夹特别多,会使用 B+ 树进行组织。从而在插入时,可以很快地知道是否有同名文件。
空闲空间管理
当我们需要新建文件或者目录项时,就需要从文件系统中获取一块可用空间。因此,如何高效的管理空闲空间,是个很重要的问题。我们使用两个 bitmap 进行管理,优点是简单,缺点是每次都得线性的扫描查找所有空闲 bit 位,且只能做到块粒度,块内如果有剩余空间,就管不到了。
读写路径
有了对磁盘上的数据结构的把握之后,我们再来通过读写流程将不同的数据结构串一下。我们假设文件系统已经被挂载:即超级块(superblock)已经在内存中。
读取文件
我们的操作很简单,就是打开一个文件(如 /foo/bar),进行读取,然后关闭。简化起见,假设我们文件大小占一个 block,即 4k。
当发起一个系统调用 open("/foo/bar", O RDONLY)时,文件系统需要首先找到文件 bar 对应的 inode,以获取其元信息和数据位置信息。但现在我们只有文件路径,那怎么办呢?
答曰:从根目录往下遍历。根目录的 inode 编号,我们要么保存在超级块中,要么就写死(比如 2,大部分 Unix 文件系统都是从 2 开始的)。也即,必须能事先知道(well known)。
于是文件系统将该根目录的 inode 从硬盘调入内存,进而再通过 inode 中的指针找到其指向数据块,进而从其包含所有子目录和文件夹中找到 foo 文件夹和其对应 inode。递归的重复上述过程,open 系统调用的最后一步是将 bar 的 inode 载入内存,进行权限检查(比对进程用户权限和 inode 访问权限控制),分配文件描述符放到进程打开文件表中,并将其返回给用户。
一旦文件被打开后,就可以继而发起 read() 的系统调用 ,真正地去读取数据。读取时,首先会根据文件的 inode 信息,找到第一个 block(除非读前实现用 lseek() 修改过偏移量),然后读取。同时,可能会更改 inode 的一些元信息,比如说访问时间。继而,更新进程中该文件描述符的偏移量,继续往下读,直到某个时刻,调用 close() 关闭该文件描述符。
进程关闭文件时,所需工作要少得多,只需要释放文件描述符即可,并不会有真正的磁盘 IO。
最后,我们再捋一下这个读文件过程。从根目录的 inode 编号开始,我们交替地读取 inode 和相应数据块,直到最终找到待查找文件。然后要进行数据读取,还要更新其 inode 的访问时间等元信息,进行写回。下表简单地总结了下这个过程,可以看出,读取路径全程不会涉及分配结构—— data bitmap 和 inode bitmap。
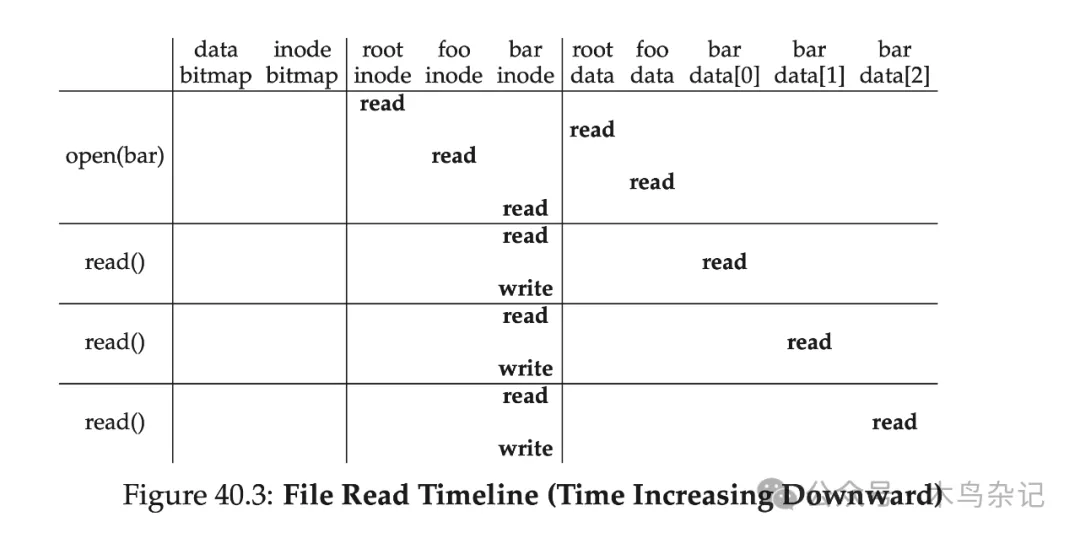
图注:文件读取时间线
从深度上来说,如果我们的待查找路径层级非常多,这个过程会线性增长;从广度上来说,如果中间查找时涉及到的文件夹,其包含的目录子项特别多,即文件树“很宽”,则每次在目录中进行查找时,可能需要读取不止一个数据块。
写入硬盘
写文件和读取文件的流程很类似,也是打开文件(从根目录一路找到对应文件);然后开始写入,最后关闭。但与读取文件不同的是,写入需要分配新的数据块,这就需要涉及我们之前的 bitmap 了,通常来说,一次写入至少需要五次 IO:
- 读取 data bitmap(以找到空闲块,并在内存中标记使用)
- 写回 data bitmap(以对其他进程可见)
- 读取 inode(增加新的数据位置指针)
- 写回 inode
- 在找到的空闲块中写入数据
这还只是对已经存在的文件进行写入。如果是尚未存在的文件进行创建并写入,那流程还要更为复杂:还要创建 inode,这就会引入一系列新的 IO:
- 一次对 inode bitmap 的读取(找到空闲 inode)
- 一次对 inode bitmap 的写回(标记某个 inode 被占用)
- 一次对 inode 本身的写入(初始化)
- 一次对父文件夹所对应目录子项数据块的读写(增加新建的文件和 inode 对)
- 一次对父文件夹 inode 的读写(更新修改日期)
如果父文件夹的数据块不够用,还得需要新分配空间,就又得读 data bitmap,和 data block。下图是创建 /foo/bar 文件的时间线上涉及到的 IO:
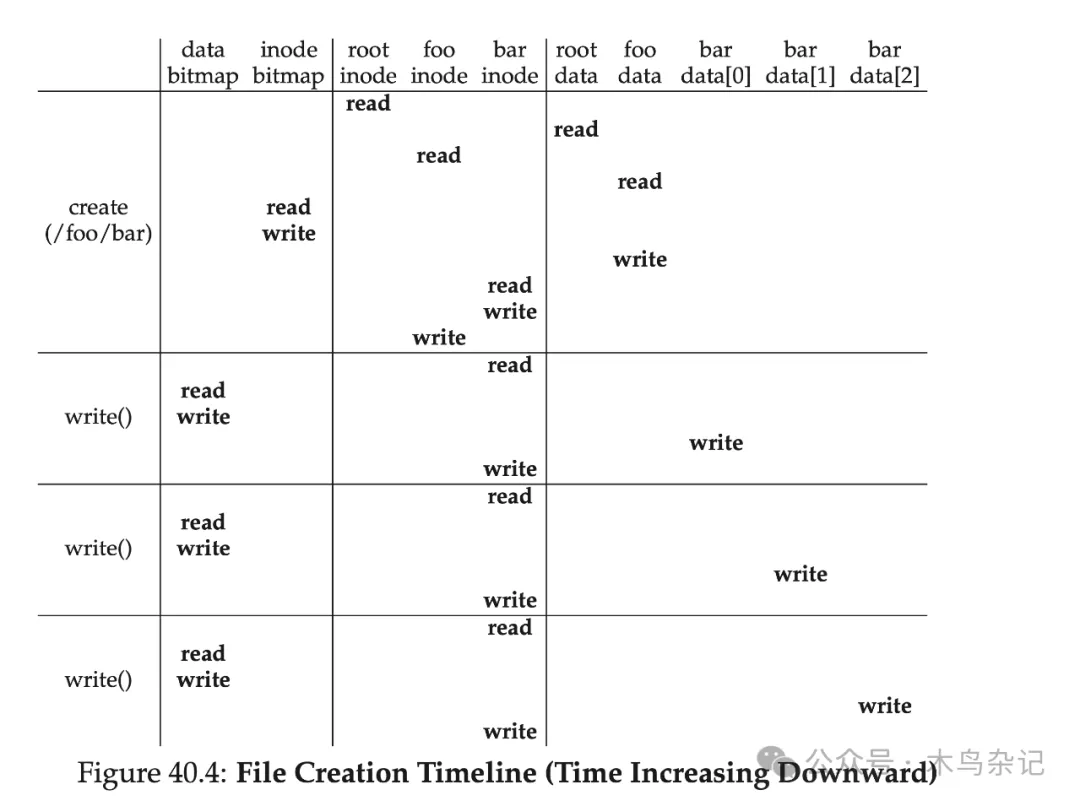
图注:创建文件的时间线
缓存和缓冲
从上面对读写流程的分析可以看出,即便如此简单的读写操作,都会涉及大量 IO,这在实践中是不可接受的。为了解决这个问题,大部分工业上的文件系统,会充分利用内存,将重要的(也就是频繁访问的)数据块缓存(cache)在内存中;与此同时,为了避免频繁刷盘,会将修改先应用到内存缓冲区(buffer)里,然后积攒后一块落盘。
早期的文件系统引入了固定尺寸缓存(fixed-size cache),如果满了,会利用 LRU 等替换算法进行页面淘汰。其缺点在于当缓存不满的时候浪费空间,满了又可能频繁换页。我们称这种风格为静态分区(static partitioning)。大部分现代文件系统,都是用动态分区(dynamic partitioning)技术。比如,将虚拟内存页和文件系统页放到一个池子中,称为统一页面缓存(unified page cache),从而上两者分配和更加弹性。上了缓存之后,对于同一个目录中多个文件的读取,后面的读取就可以省下很多 IO。
写流程由于前半程根据路径查找数据块时牵扯到读,所以也会从缓存中受益。但对于写的部分,我们可以通过缓冲区(writing buffering),来延迟刷盘。延迟刷盘有很多好处,比如说可以多次修改 bitmap 可能只需要刷一次;积攒一批更改,可以提高 IO 带宽利用率;如果文件先增后删,可能就直接省了刷盘。
但这些性能的提升是有代价的——意外宕机可能会造成数据丢失。所以,虽然现代文件系统大部分开启了读写缓冲,但也通过 direct I/O 的方式,来允许用户绕过缓存,直接写磁盘。对丢失数据很敏感的应用,可以利用其对应的系统调用 fsync() 来即时刷盘。
小结
至此,我们完成了一个至简的文件系统的实现。其“麻雀虽小,五脏俱全”,我们从中可以看出文件系统设计一些基本的理念:
-
使用 inode 存储文件粒度的元信息;使用数据块存真正的文件数据
-
目录是一种特殊的文件,只不过存的不是文件内容,而是文件夹子目录项
-
除了 inode 和数据块外,还需要一些其他的数据结构,比如 bitmap 来追踪空闲块
从这个基本的文件系统出发,我们其实可以看到特别多的可以取舍和优化的点,如果感兴趣,大家可以在本文基础上,去看看一些工业上的文件系统的设计。
参考资料
[1] Operating Systems: Three Easy Pieces: Operating Systems: Three Easy Pieces
[2] JuiceFS: GitHub - juicedata/juicefs: JuiceFS is a distributed POSIX file system built on top of Redis and S3.