nebula版本:3.2.1
graphd: 3
metad: 3
storaged: 7
磁盘是SSD的
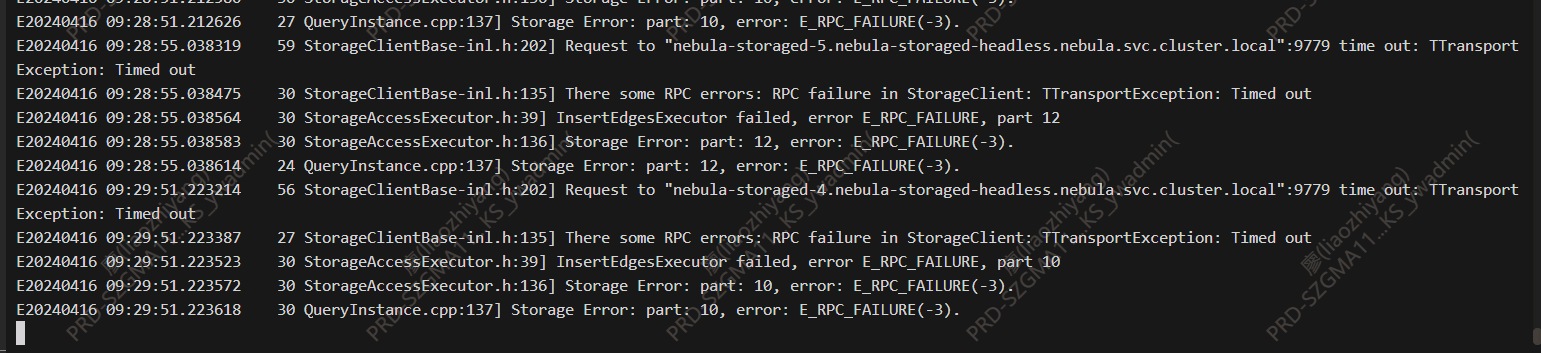
报错非常典型:
目前就是集群搭建完成后,插入点正常
插入边时一直报time out,偶尔能插入成功几条
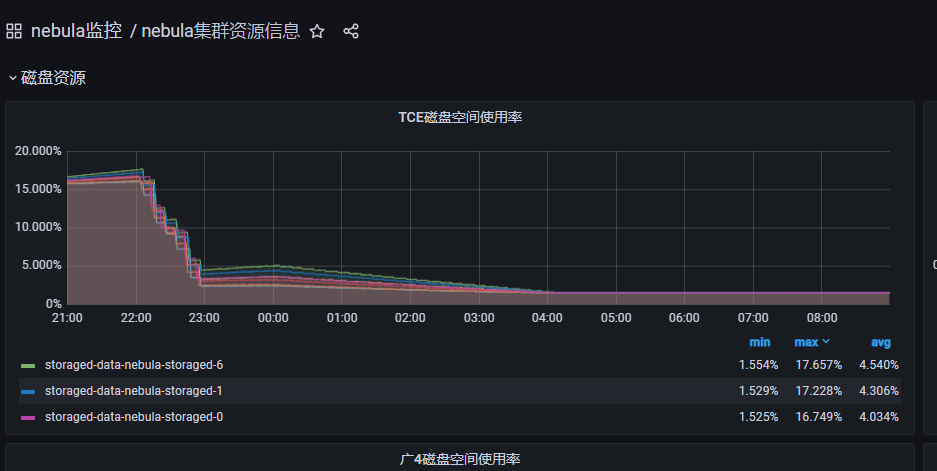
开始以为是用exchange导入数据太快导致storage在自动compact,可以看到在22点后集群的磁盘占用有比较大的下降
22点之前是在写点,磁盘上升很快
22点后还在继续写入边,但是频繁超时
但问题是0点以后导数任务已经停止了,截至目前9点,在studio提交单条的insert edge语句还是会报超时,insert vertex语句正常
看storage的日志目前没有在compact或者其他任务在执行,但是graph和storage交互还是会超时,超时时是默认的60000ms
求各位大佬指点。。。
steam
3
把你插入的语句贴一下看看,顺便 show hosts 看下服务是不是正常的。

在studio上随便写的,报E_RPC_FAILURE
VERTEX是可以插入的
steam
5
我插入了一个空属性的边,成功了,你看下你的边的 schema 是咋定义的。
大佬,我认为问题不在于schema定义之类的
因为schema和图里的tag和边结构,以及数据写入都在另一个环境的nebula验证过了的
目前的问题在于:
在新建的集群上搭建了一个nebula库
用exchange写入点可以正常写入,写入边一直报E_RPC_FAILURE(-3),然后上graphd的日志就像我发的日志截图一样,大量报超时(此时我认为是导数速度过快storage处理不过来,storaege日志也确实发现了不少minor compact的日志)
然后我在停止exchange导入任务很久后,用studio手工插入单条边数据依然会报E_RPC_FAILURE,所以我认为我之前假设的导入数据速度过快导致storage压力过大导致超时的假设也不成立,因为目前storage目前看没有在干活
所以不清楚该如何继续排查了
补充一下:
当前写入点还是可以正常写入不超时
写边会超时
很困惑
steam
9
你那边方便的话,可以先测试下看不借助客户端(nebula-studio)和连接器(nebula-exchange),用 nebula-console 看看是不是可以插入边看看么?
这两个参数我查阅到了论坛里的另一个帖子,里面有人建议这个数字为核数的一半
目前我的storage节点是16C,所以这两个参数的配置是8
请问需要改大么
而且目前我没有手动compact过,看日志storage是有default minor compact
steam
15
 我们可能是被同一个人教育的,他和我说 cpu 的一半。保持统一。
我们可能是被同一个人教育的,他和我说 cpu 的一半。保持统一。
方便的话,试试这个? 看下是不是客户端哪里有问题。
看下是不是客户端哪里有问题。
nebula-console这个暂时没有条件诶,环境不太自由,这里说的客户端是指怀疑exchange或者studio有问题吗?
目前是把集群铲掉后,扩大了storage节点的磁盘容量(500G——>1.4T)
之后不会再报E_RPC_FAILURE的错误了,感觉节点的容错能力好像变强了
但是写入边还是有问题:
我有一个不断增量写入点边的作业,通过jar包nebula-client连接nebula,持续不断的少量写入是正常的
但是此时如果开启spark任务开始导入全量数据,会发生两个问题
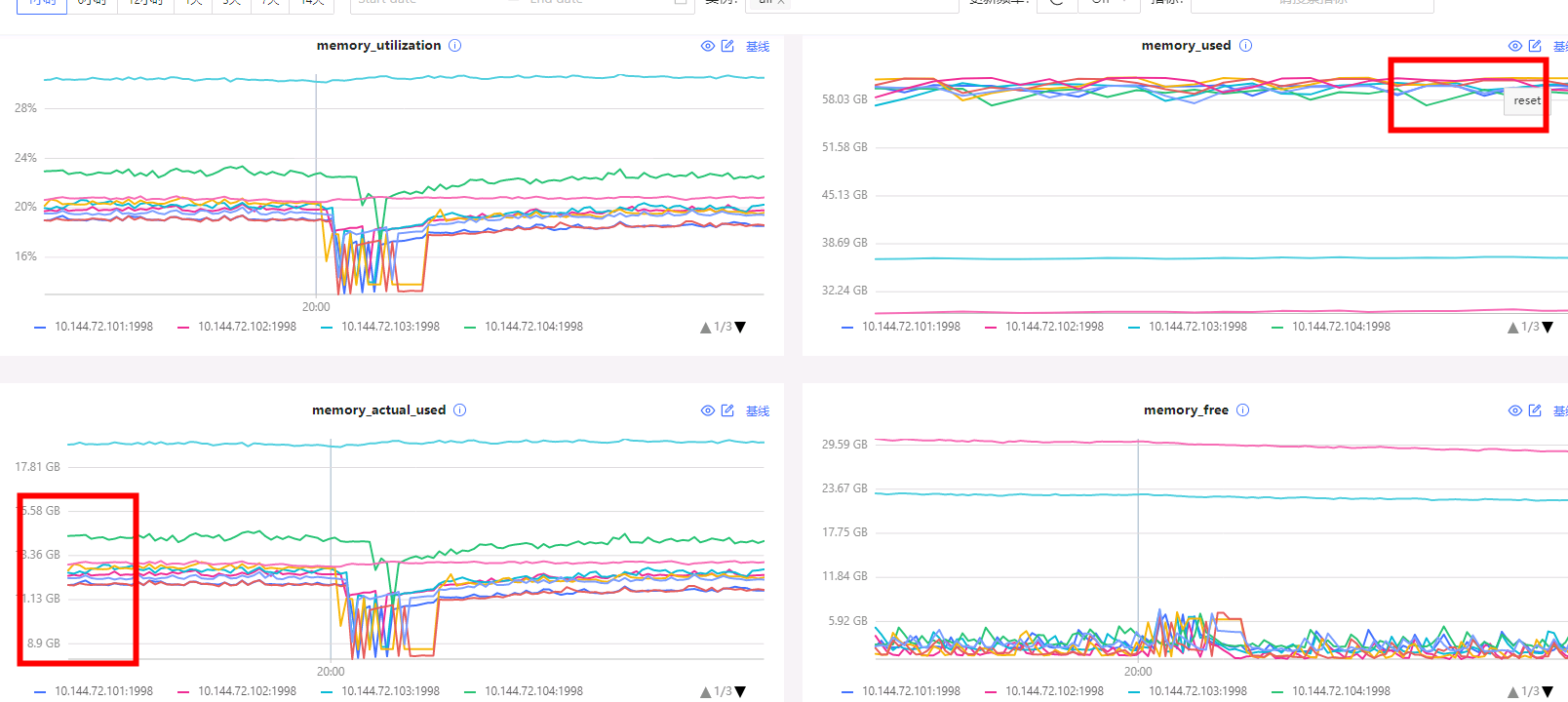
1、内存被打满,且从dashboard看实际使用内存不高,大部分是缓存
不过这个不至命,在exchange写入点时可以继续写入
2、开始写边后,就开始报raft buffer is full的报错,如我最开始的贴图
我在论坛上翻了不少帖子,还有官方文档
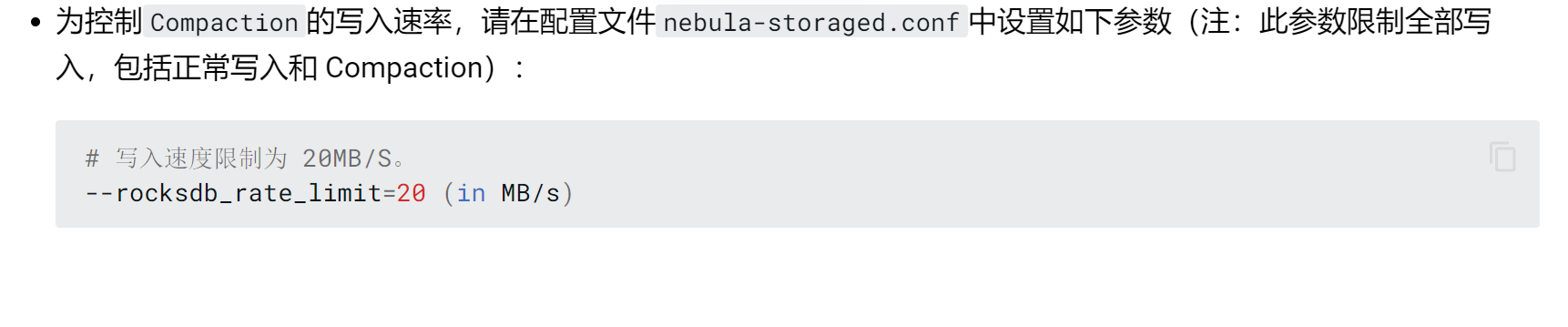
按照最佳实践调整了max_sub_compaction等两个参数,还有rate_limit(因为怀疑是default compact占用了磁盘IO导致 buffer消耗慢)
steam
17
嗯,排除下。 如果环境不方便的话,你方便把 exchange 的配置贴一贴么?
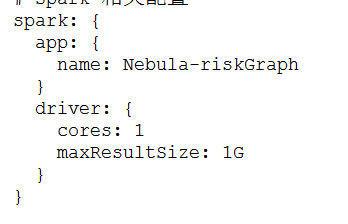
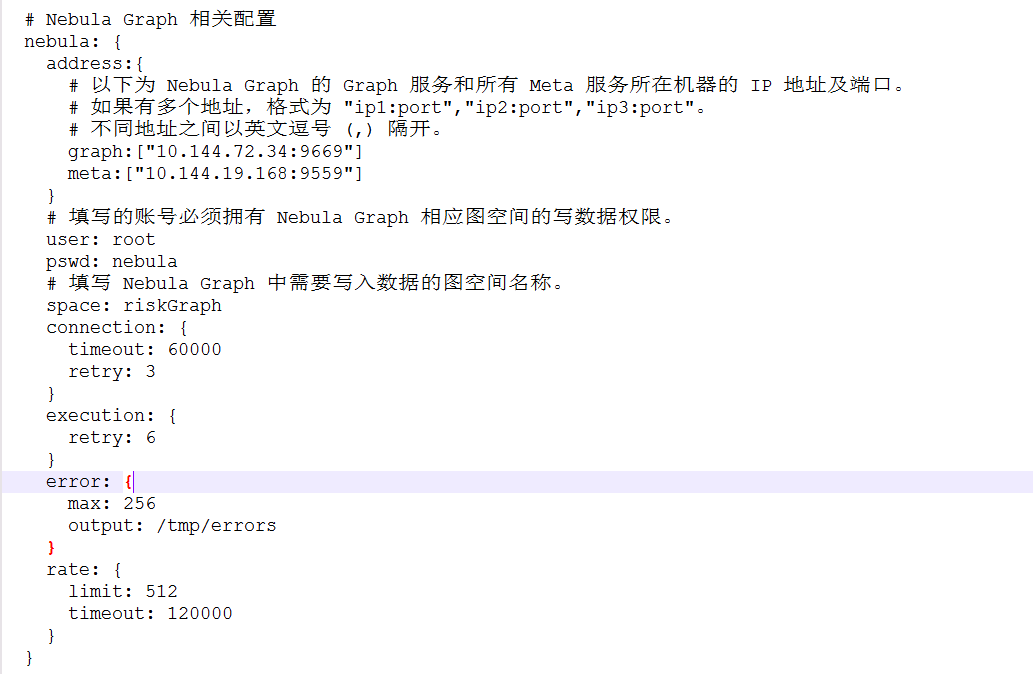
我目前把点都导进去了,边一直有问题,在不停的调batch和partition两个参数
目前感觉这个缓存占用很有问题,发现buffer/cache占用很多,而且停止所有写入后这个值仍然居高不下。。。
xjc
20
buff/cache不用管,是可以回收利用的。
那个rate_limit配置去掉啊,那个虽然限制了compaction的写入,但更限制了你的数据写入。