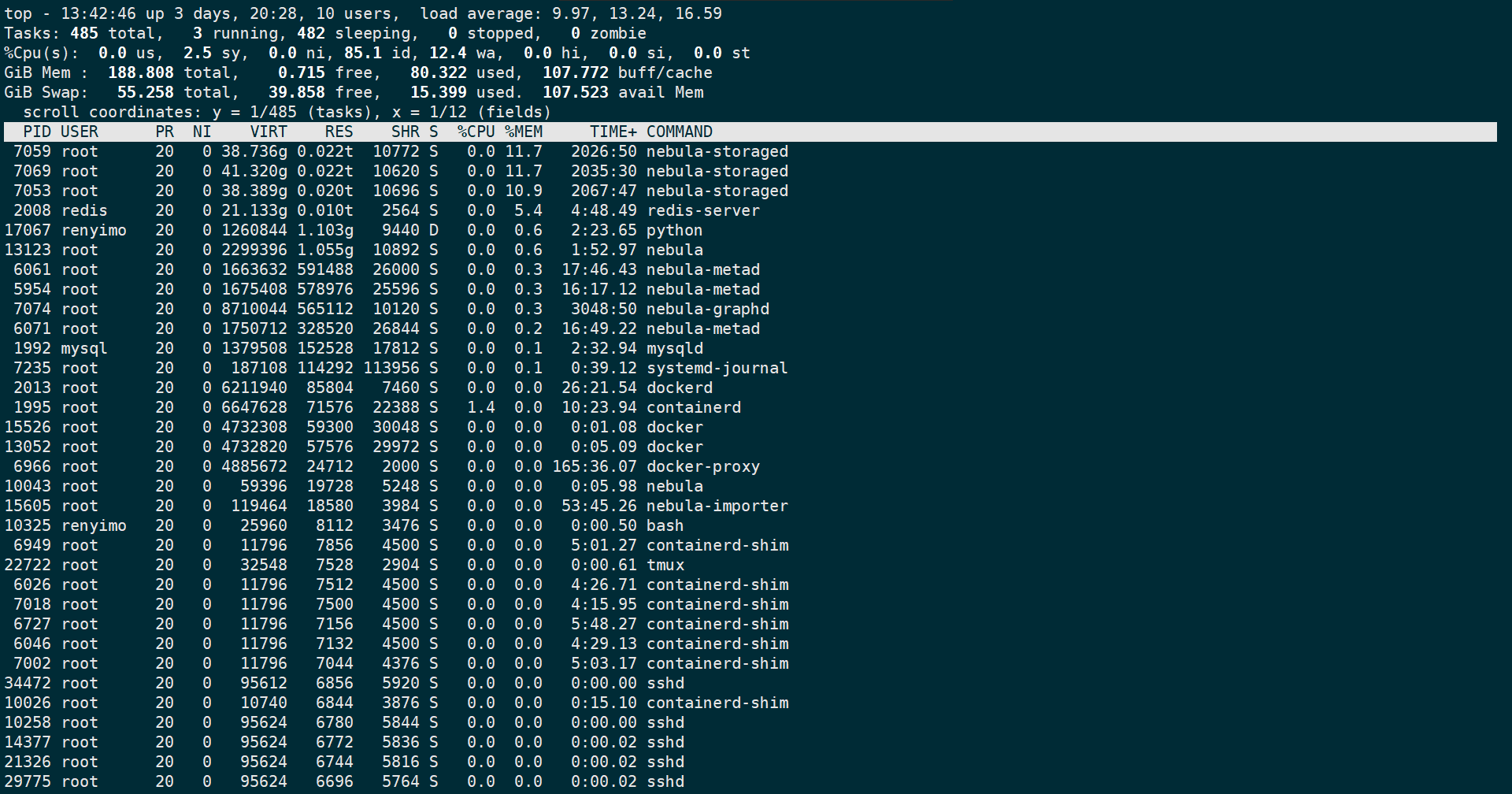
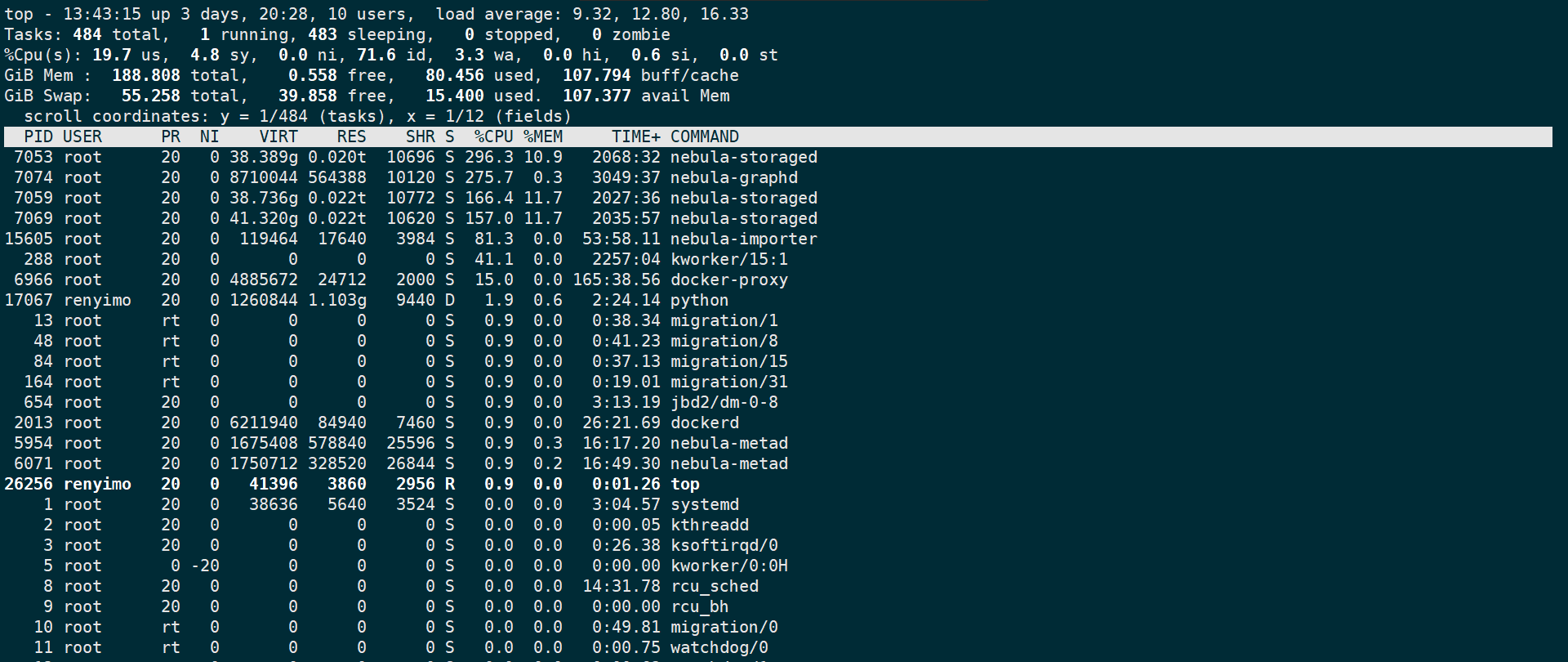
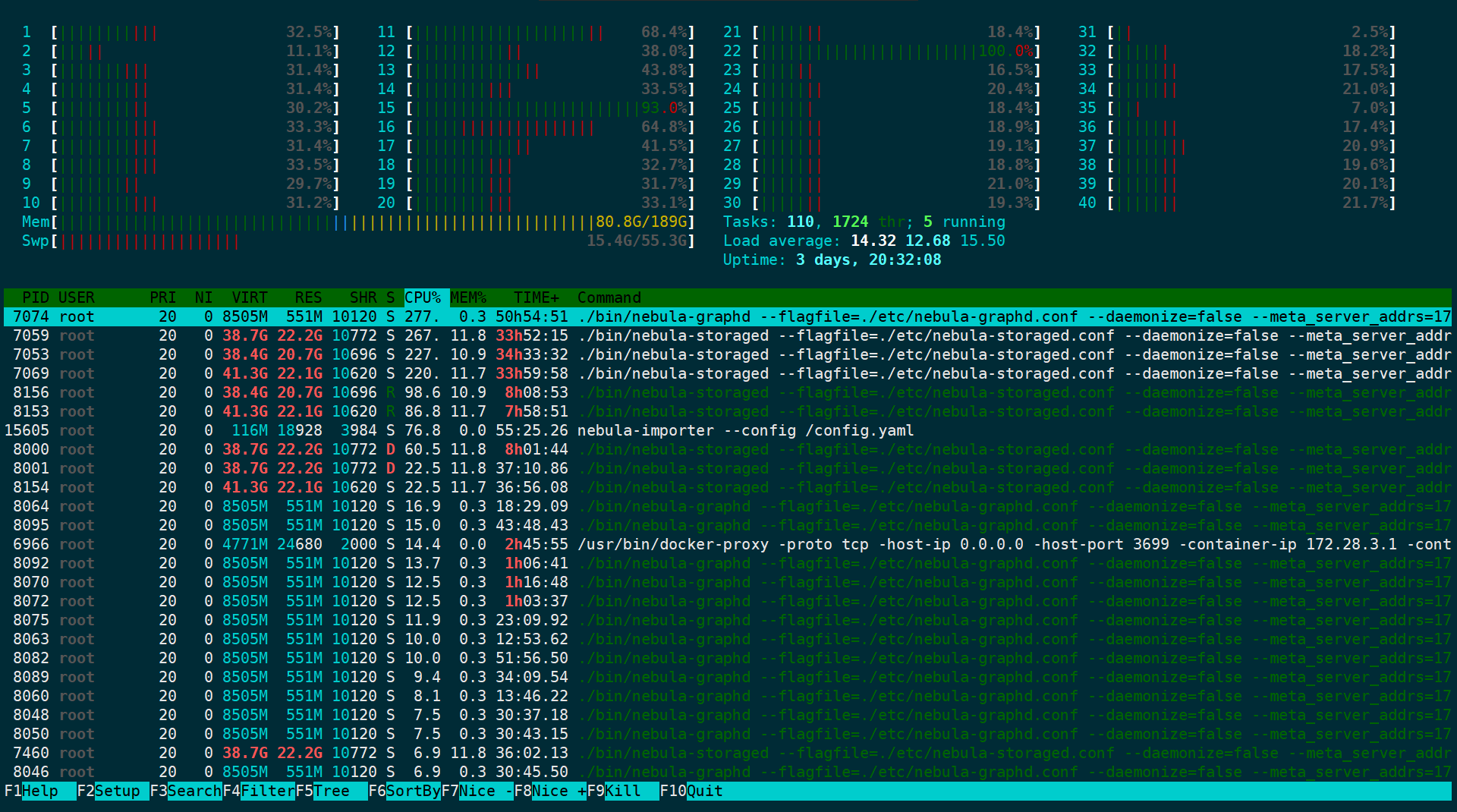
使用 nebula-python和数据库交互,python抛出 timeout
File "/usr/local/lib/python3.8/site-packages/nebula/Client.py", line 117, in execute_query
raise ExecutionException("Execute `{}' failed: {}".format(statement, x))
nebula.Common.ExecutionException: Execute `GO FROM 217 OVER someedge YIELD $$.sometag.name' failed: Socket read failed: timed out
Traceback (most recent call last):
File "/usr/local/lib/python3.8/site-packages/thrift/transport/TSocket.py", line 298, in read
buff = self.handle.recv(sz)
socket.timeout: timed out
查看日志可以看到里面有Timed Out的异常
graphd的日志
$ tail graph/nebula-graphd.INFO
I1027 03:27:28.835041 94 UseExecutor.cpp:48] Graph space switched to `TEST', space id: 34
I1027 03:27:49.888263 94 GraphService.cpp:50] Authenticating user user from 10.10.10.131:58192
I1027 03:27:52.192646 78 GraphService.cpp:50] Authenticating user user from 10.10.10.131:58196
I1027 03:27:52.194272 78 UseExecutor.cpp:48] Graph space switched to `TEST', space id: 34
E1027 03:28:29.368170 16 StorageClient.inl:123] Request to [172.28.2.2:44500] failed: N6apache6thrift9transport19TTransportExceptionE: Timed Out
E1027 03:28:29.368497 16 StorageClient.inl:123] Request to [172.28.2.3:44500] failed: N6apache6thrift9transport19TTransportExceptionE: Timed Out
E1027 03:28:29.368639 16 StorageClient.inl:123] Request to [172.28.2.1:44500] failed: N6apache6thrift9transport19TTransportExceptionE: Timed Out
E1027 03:28:29.368840 81 ExecutionPlan.cpp:80] Execute failed: Get dest props failed
E1027 03:28:52.204252 22 StorageClient.inl:123] Request to [172.28.2.1:44500] failed: N6apache6thrift9transport19TTransportExceptionE: Timed Out
E1027 03:28:52.204530 78 ExecutionPlan.cpp:80] Execute failed: Get neighbors failed
其中一个storage的日志
$ tail storage0/nebula-storaged.INFO -n 20
I1027 03:30:22.826171 70 CompactionFilter.h:67] Do default minor compaction!
I1027 03:30:45.781060 70 EventListner.h:33] Rocksdb compact column family: default because of 1, status: OK, compacted 15 files into 8, base level is 0, output level is 1
I1027 03:30:46.804128 70 EventListner.h:23] Rocksdb compact column family: default because of 2, status: OK, compacted 5 files into 0, base level is 1, output level is 2
I1027 03:30:46.804448 70 CompactionFilter.h:67] Do default minor compaction!
I1027 03:30:47.997128 26 InMemoryLogBuffer.h:27] [Port: 44501, Space: 63, Part: 84] InMemoryLogBuffer dtor, firstLogId 3639252
I1027 03:30:48.001283 26 InMemoryLogBuffer.h:23] [Port: 44501, Space: 63, Part: 84] InMemoryLogBuffer ctor, firstLogId 3661806
I1027 03:30:49.721815 64 SlowOpTracker.h:33] [Port: 44501, Space: 59, Part: 9] , total time:207ms, Write WAL, total 2
I1027 03:30:49.722144 66 SlowOpTracker.h:33] [Port: 44501, Space: 59, Part: 45] , total time:207ms, Write WAL, total 2
I1027 03:30:49.723392 67 SlowOpTracker.h:33] [Port: 44501, Space: 59, Part: 57] , total time:209ms, Write WAL, total 2
I1027 03:30:50.502573 14 SlowOpTracker.h:33] [Port: 44501, Space: 51, Part: 45] , total time:180ms, Total commit: 1
I1027 03:30:52.897030 42 SlowOpTracker.h:33] [Port: 44501, Space: 63, Part: 60] , total time:203ms, Write WAL, total 2
I1027 03:30:53.362690 42 SlowOpTracker.h:33] [Port: 44501, Space: 63, Part: 24] , total time:431ms, Write WAL, total 2
I1027 03:30:53.804636 41 SlowOpTracker.h:33] [Port: 44501, Space: 63, Part: 63] , total time:69ms, Write WAL, total 2
I1027 03:30:53.804633 24 SlowOpTracker.h:33] [Port: 44501, Space: 63, Part: 57] , total time:70ms, Write WAL, total 2
I1027 03:30:53.804641 21 SlowOpTracker.h:33] [Port: 44501, Space: 63, Part: 72] , total time:69ms, Write WAL, total 2
I1027 03:30:53.804642 22 SlowOpTracker.h:33] [Port: 44501, Space: 63, Part: 51] , total time:70ms, Write WAL, total 2
I1027 03:30:53.804649 26 SlowOpTracker.h:33] [Port: 44501, Space: 63, Part: 66] , total time:71ms, Write WAL, total 2
I1027 03:30:53.804652 39 SlowOpTracker.h:33] [Port: 44501, Space: 63, Part: 48] , total time:71ms, Write WAL, total 2
I1027 03:30:53.804726 37 SlowOpTracker.h:33] [Port: 44501, Space: 63, Part: 69] , total time:70ms, Write WAL, total 2
I1027 03:30:53.804859 13 SlowOpTracker.h:33] [Port: 44501, Space: 63, Part: 45] , total time:71ms, Write WAL, total 2