语势科技
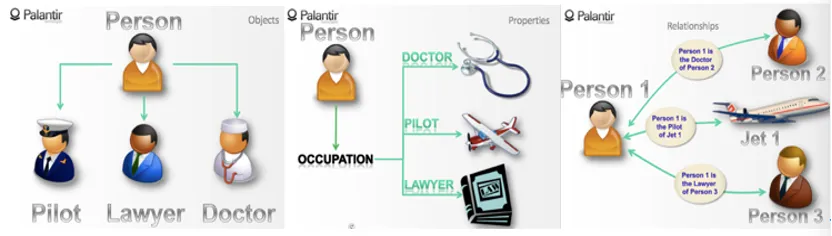
语势科技专注于结合大模型和知识图谱的能力,构建以主题投资理论为核心的 2B 智能投顾平台,核心产品为“主题蜂 https://themepica.com”。产品体系对标成立于 2003 年的美国 AI 巨头 Palantir。Palantir 初期服务于 FBI/CIA,于 2020 年纽交所上市。
前言
语势科技的产品核心围绕动态本体(Dynamic Ontology)构建,其区别于传统的概念建模方式,强调在事件驱动的背景下,如何快速发现对象之间的关系并动态构建本体并建立关系,以适应当前信息爆炸的背景下数据分析的需求。
在产品建设过程中,除了传统的数据处理和分析技术,我们也使用了大模型进行数据处理和分析,因此也难免遇到了使用大模型构建金融服务产品时的一些通用问题。
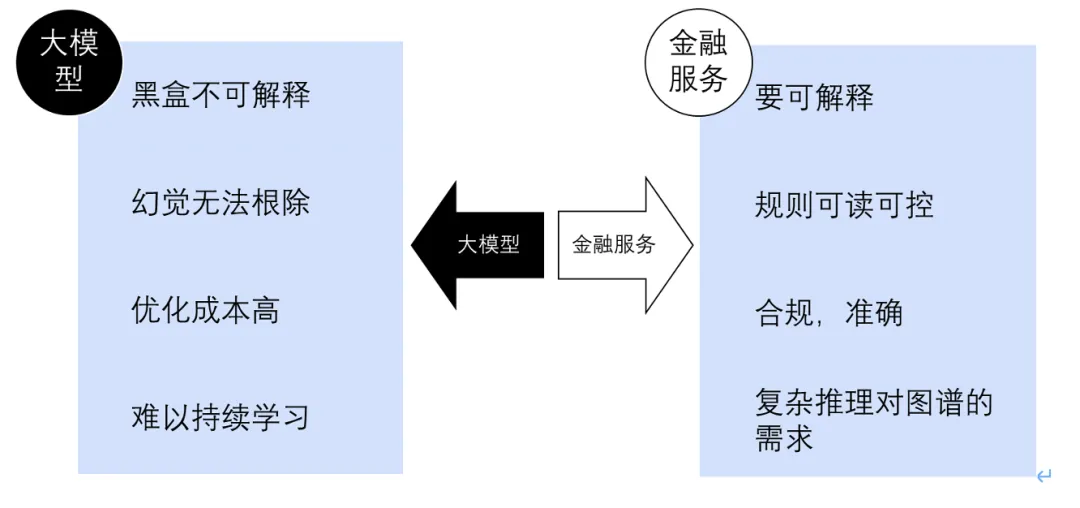
众所周知,大模型的黑盒和幻觉特性来自其原理设计,无法根除。但是,如果能基于现有信息,结合业务分析框架进行推理分析,那就可以从应用层面一定程度上解决可解释等合规问题,因此构建一个分析师可以参与,可结合场景定制的分析推理框架就成为了我们的首要任务。
从 Baseline RAG 到 GraphRAG
最初,基于我们在非结构化数据处理的已有框架上进行了改造,引入大模型的 Embedding 结果参与到向量匹配中。但是最终发现,基于大模型的向量检索相比传统方式小幅度提高正确概率,但同样无法提供确定性答案,且缺乏上下文和解释性。
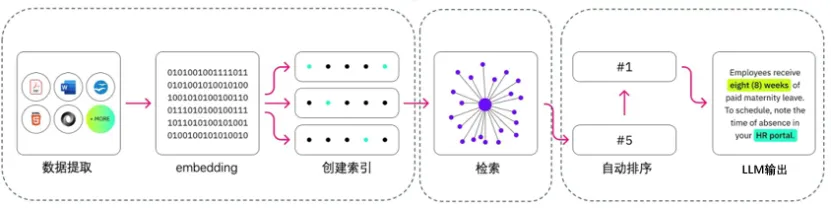
因此,我们考虑给大模型更多的上下文信息,直接通过大模型的推理来代替本地的向量匹配方式,即 Baseline RAG 的方式。但是效果仍然不够理想,且 RAG 方案成本高,响应速度不能满足需要。
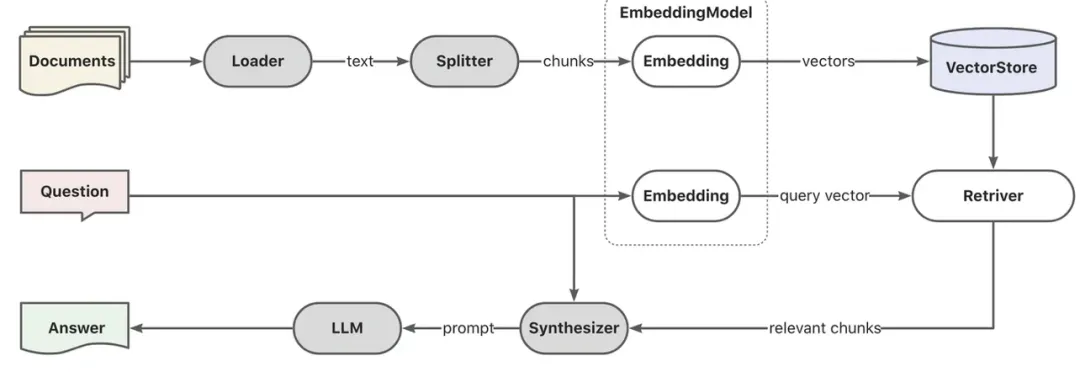
因为从理论上来讲,大模型是一个概率模型,对世界的表示就是向量。相比而言,知识图谱体现的是人对世界的结构性知识,在实现复杂的推理过程方面应该更具有优势。
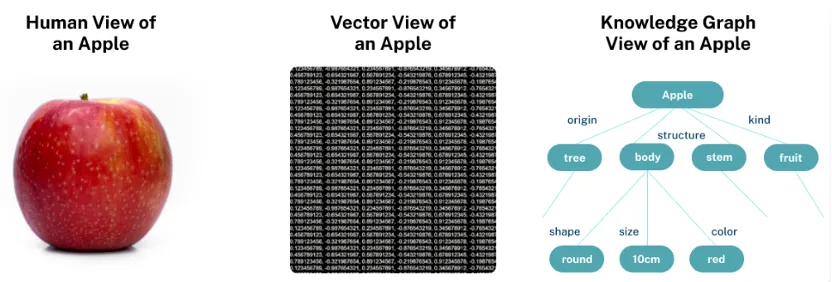
在 AI 领域,概率模型属于连接主义流派,利用计算机来模拟人类的生理结构,也就是神经网络的路线。包括神经网络在内的深度学习更多的是解决感知层面的问题,比如识别、判断等;
另外一个流派就是符号主义,利用计算机来模拟人类的认知思维,更多的是解决推理层面的问题。由此发展出知识工程、专家系统。知识图谱就是这一类学术思想的延续。
如下图所示,连接主义流派首先伴随 AI 概念诞生而产生,但是遇到瓶颈而推动了符号主义发展。两个流派此消彼长,也已将近几十年。
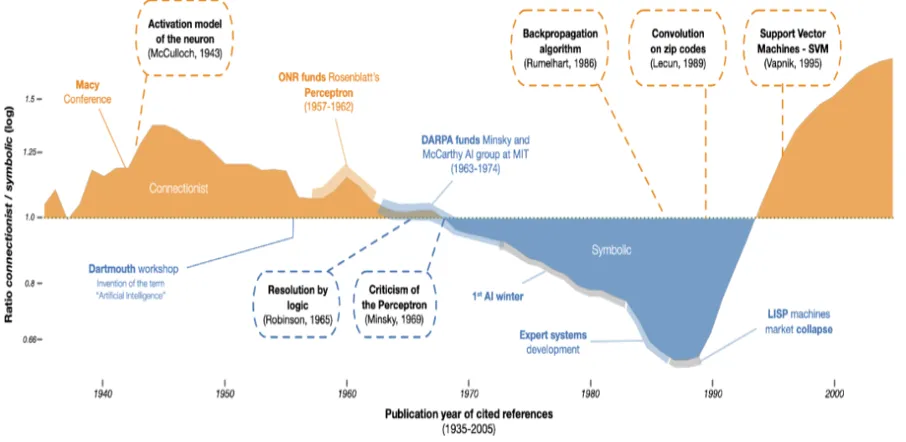
在当下,LLM 如日中天,但是如前边所分析,单纯使用 LLM 并不能很好的解决我们所面临的业务需求,需要将两个流派的技术结合使用。
“神经”与“符号”的结合有如下几种方案:
- 利用神经网络执行符号推理任务
包括目前流行的图神经网络、图卷积神经网络等。在这类方法中,神经网络基于统计建模从数据中抽象提取出符号,赋予符号对数据噪声的“弹性”并显著减少符号系统的搜索空间,从而加速学习过程。但本质上来说,该类方法中规则被弱化了,即更侧重统计上的推理,而不是逻辑上的演绎推理。
- 将符号知识注入神经网络
利用符号系统来支持神经网络学习过程,同时将符号知识纳入训练。其目的是从知识图谱中推导出一般的逻辑规则,例如损失函数设计、进行一些正则化约束等。
- 融合神经网络与符号系统
在该方法中神经系统和符号系统扮演着“平等”的角色,神经系统的输出作为符号系统的输入,符号系统的输出又作为神经系统的输入,在迭代中完成两个系统的信息交互,从而实现更深层次的神经符号系统集成。
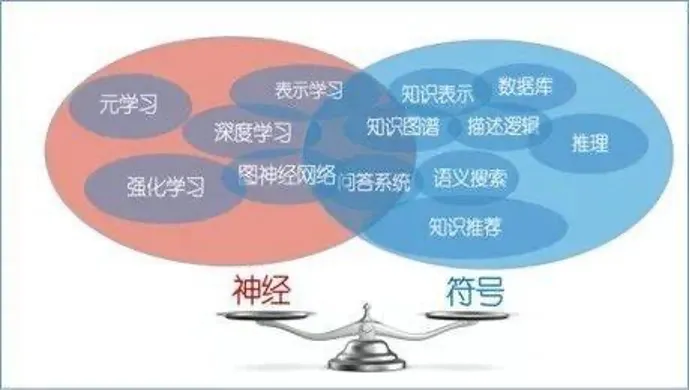
对于初创团队,前边两个方案都涉及到模型的 SFT,时间和开发成本过高,因此我们考虑选择第三种融合方案,引入知识图谱,使用 GraphRAG 来解决面临的业务问题。
选型过程
既然选择了 GraphRAG 路线,首先要解决的就是图数据库的选型。首先选择了 DB-Engines Ranking 的列表作为备选产品列表。
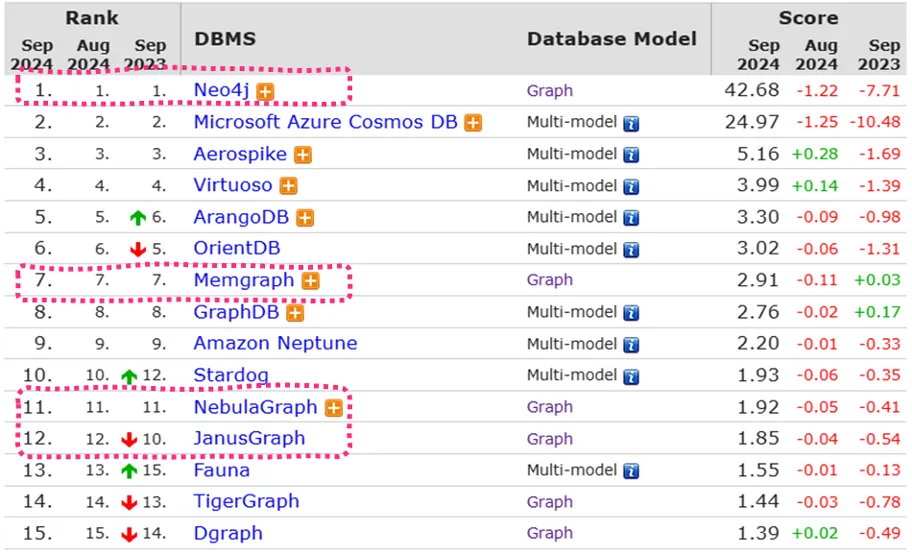
基于我们的实际情况,选择了其中红色圈出的产品进行考察。
同时,设定了一些需要考察的指标。
查询语言阵营选择
- 倾向于有商业机构支持的开放标准,因为笔者在多年前做云计算时在 OpenStack 领域的前车之鉴,这一点作为产品在生态圈可持续发展的重要因素,被放在了首位。
易上手
-
GUI
-
玩不死,玩不坏
易部署管理
-
开箱即用
-
具备一定 HA 能力
-
监控指标全,易集成
-
不需要太多第三方组件支持
易集成
-
模式设计灵活
-
多图支持
-
易于和常见开发框架集成
-
具备和 LLMs 集成能力和案例支撑
-
最好能内置常见文本相关算法库
性能
- 后边考察的除了性能,就是一个词,易用。这一点对于初创团队来讲太重要了。
我们最终选择了 NebulaGraph,原因如下:
-
功能完整度高,产品成熟度高:NebulaGraph 作为一个功能完整且成熟的图数据库,能够提供稳定和可靠的服务,这对接入 GraphRAG 这种需要高效数据处理和分析的技术尤为重要。
-
社区活跃,案例丰富:一个活跃的社区意味着有更多的资源和支持,丰富的案例也表明 NebulaGraph 在实际应用成绩中得到了成功的验证,可以减少我们的试错成本,加快项目进展。
-
易于集成:NebulaGraph 支持与 LLMs(Large Language Models)和 Spring 等技术的集成,这表明它具有良好的灵活性和扩展性。
初步成果
图数据库选型完成后,我们也参考了 NebulaGraph 社区的很多文章,围绕主题、投资标的数据设计了我们包括主题、商品、技术、机构等在内的根概念。另外对于事件类型数据的处理还在研究。
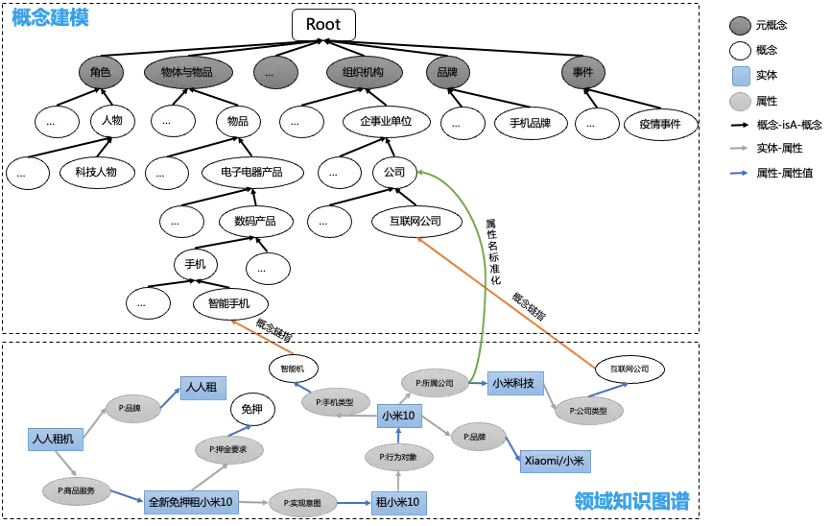
下图即为我们构建的某投资主题图谱。
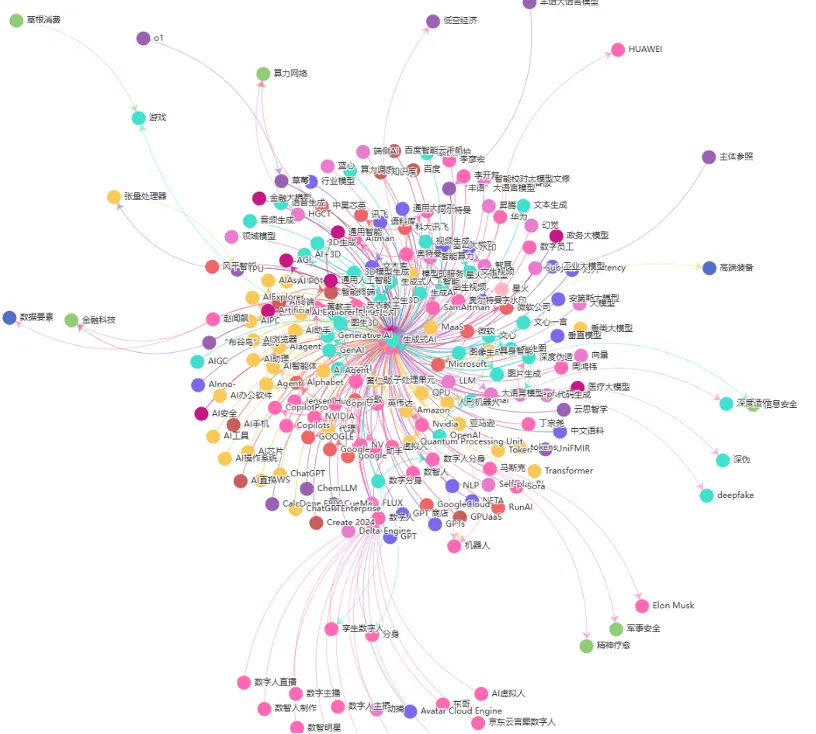
未来规划
下一步我们还需要继续丰富图谱的数据,这就需要脱离人工,使用 LLM 来帮助我们进行语料的分析,提高 NER 效率和准确性。进一步的,直接使用大模型构建本体及建立关系。
另外,最近 OpenAI o1 的推出,让大家更加重视 CoT,我们也考虑将 CoT 纳入到我们的数据处理流程中,以提高推理的准确性和可解释性。
如下是 Palantir 公司的产品的流程中 CoT 设计界面。
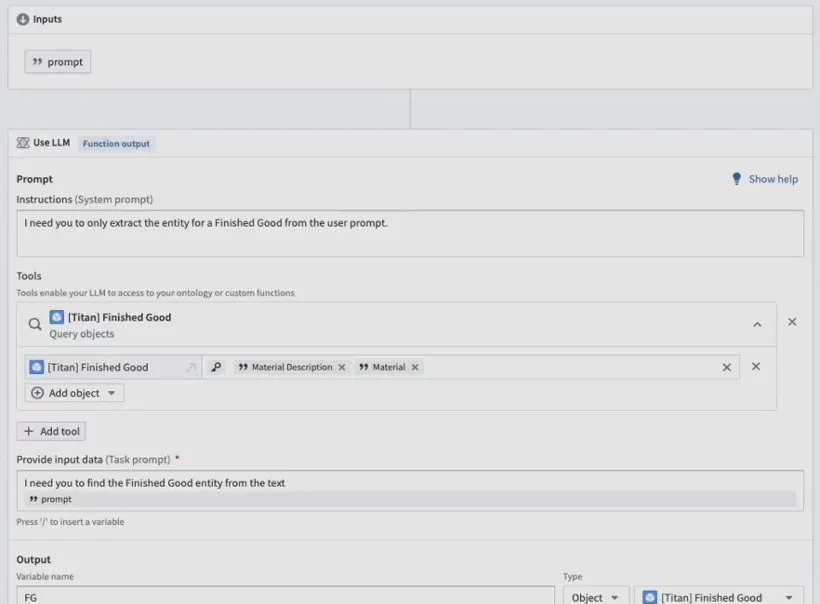
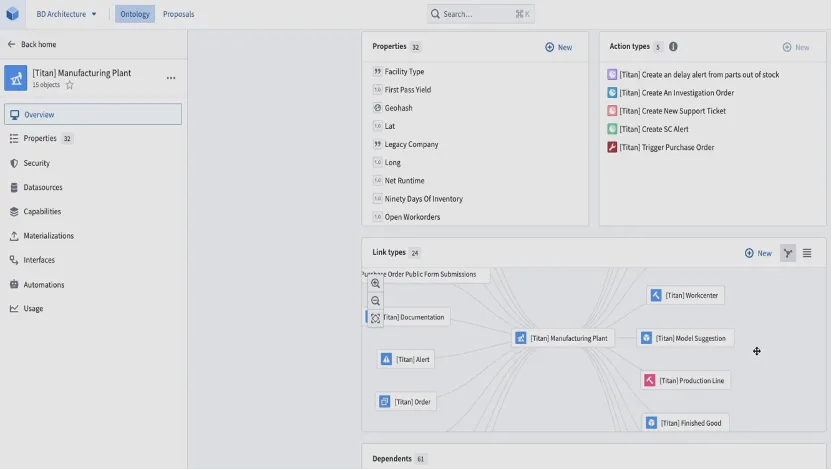
作为一个初创公司,我们在整个图谱建设过程中遇到了很多的具体问题,比如同义不同形,同形不同义的情景处理;事件图谱的构建和使用;自定义关系,新词热词识别等等。也期待业内专家能够给与我们帮助和指导。