评估arangoml的能力时,第一部分:https://www.arangodb.com/2020/09/arangoml-part-1-where-graphs-and-machine-learning-meet/ 提到了Pregel,Pregel是2010 Google Grzegorz Malewicz等1提出的大规模图处理系统,旨在解决现实中复杂的大图,如社交网络等,见下图:

arangodb 实现了Pregel子系统2,能力上来说, 如果是online的小规模图分析, 直接使用属性图的能力就可以了,但是,对于复杂的案例, 例如社区检测/划分,arangodb通过实现Pregel,实现了Label Propagation (LP), Speaker-Listener Label Propagation (SLPA) 以及Disassortative Degree Mixing and Information Diffusion (DMID)等算法,使得ML的能力进一步突出。
我们也可以有替代的方案做大规模的图分析, 比如, 借助Spark GraphX生态, 通过转换Nebula数据结构到GraphX扩展的RDD, 然后借助GraphX的受限Pregel实现3, 见下图,
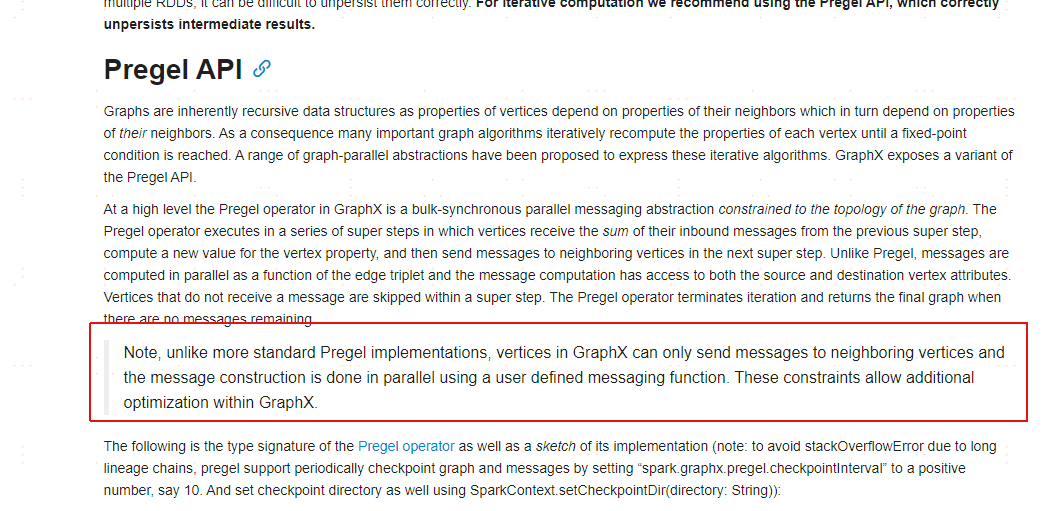
这里存在几个问题:
(1) Spark的GraphX Pregel实现并非标准
(2) 存在底层存储Nebula到Spark RDD的转换,性能有损失且Spark RDD的资源消耗不确定
(3) 引入了批流引擎Spark
所以,希望能够像Arangodb 一样原生得实现Pregel子系统,进一步释放ML或者图分析能力。