有什么办法解决吗?
我感觉要看代码了
有什么办法解决吗?
我感觉要看代码了
你也可以在Exchange中本地debug的,把断点打在com.vesoft.nebula.tools.importer.processor.Processor#extraValue中。
我现在导入成功了 果然是hive的int和nebula的int不一致导致的
hive里面的bigint对应nebula的int
我的最新nebula_application.conf文件
{
# Spark relation config
spark: {
app: {
name: Spark Writer
}
driver: {
cores: 1
maxResultSize: 1G
}
cores {
max: 4
}
}
# Nebula Graph relation config
nebula: {
address:{
graph: ["192.168.1.110:3699"]
meta: ["192.168.1.110:45500"]
}
user: user
pswd: password
space: test_hive
connection {
timeout: 3000
retry: 3
}
execution {
retry: 3
}
error: {
max: 32
output: /tmp/error
}
rate: {
limit: 1024
timeout: 1000
}
}
# Processing tags
tags: [
# Loading from Hive
{
name: tagA
type: {
source: hive
sink: client
}
exec: "select id,idint,idstring,tboolean,tdouble from nebula.taga"
fields: [id,idstring,tboolean,tdouble]
nebula.fields: [idInt,idString,tboolean,tdouble]
vertex: id
batch: 256
partition: 32
}
{
name: tagB
type: {
source: hive
sink: client
}
exec: "select id,idint,idstring,tboolean,tdouble from nebula.tagb"
fields: [id,idstring,tboolean,tdouble]
nebula.fields: [idInt,idString,tboolean,tdouble]
vertex: id
batch: 256
partition: 32
}
]
# Processing edges
edges: [
# Loading from Hive
{
name: edgeAB
type: {
source: hive
sink: client
}
exec: "select id_source,id_dst,idint,idstring,tboolean,tdouble from nebula.edgeab"
fields: [id_source,idstring,tboolean,tdouble]
nebula.fields: [idInt,idString,tboolean,tdouble]
source: id_source
target: id_dst
batch: 256
partition: 10
}
]
}
我这个case 正好可以避免 类型转换的坑
暂时没有spark3的计划哦,但spark是向上兼容的,你可以试下在exchange的pom文件中把spark版本改成3.x尝试下
试过了 不行的,编译就报错了 spark-sql core 2.x 有个文件 在3.x 下去掉了
sad… 你可以尝试在exchange基础上二次开发用spark3进行数据导入,顺便给我们nebula-java 提一个pr  。
。
好建议 我这两天才开始 接触spark ![]()
v2在3.x下都去掉了
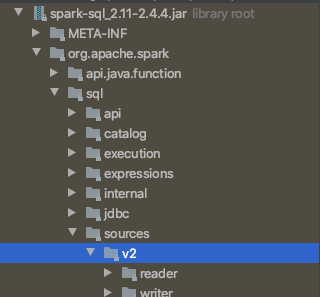
exchange使用spark3.0.0是可以编译过的
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>赞 试了一下 在spark2下导入没问题,我再去试试 在spark3环境下
exchange没有用到v2哈,spark-connector用到了v2
在spark3下 exchange编译没问题,spark-submit执行的时候报错,我怀疑是scala版本的问题导致的
默认是2.11切换到2.12编译就报错了
2020-11-19 18:14:00,457 INFO hive.metastore: Connected to metastore.
Exception in thread "main" java.lang.NoSuchMethodError: 'scala.collection.mutable.ArrayOps scala.Predef$.refArrayOps(java.lang.Object[])'
at com.vesoft.nebula.tools.importer.utils.NebulaUtils$.getDataSourceFieldType(NebulaUtils.scala:39)
at com.vesoft.nebula.tools.importer.processor.VerticesProcessor.process(VerticesProcessor.scala:137)
at com.vesoft.nebula.tools.importer.Exchange$$anonfun$main$2.apply(Exchange.scala:174)
at com.vesoft.nebula.tools.importer.Exchange$$anonfun$main$2.apply(Exchange.scala:152)
at scala.collection.immutable.List.foreach(List.scala:392)
at com.vesoft.nebula.tools.importer.Exchange$.main(Exchange.scala:152)
at com.vesoft.nebula.tools.importer.Exchange.main(Exchange.scala)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:928)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1007)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1016)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
2020-11-19 18:14:02,001 INFO spark.SparkContext: Invoking stop() from shutdown hook
你的环境的scala是啥版本的,2.11么
(base) ➜ ~ scala --version
Scala code runner version 2.13.3 – Copyright 2002-2020, LAMP/EPFL and Lightbend, Inc.
scala版本要保持一致的 