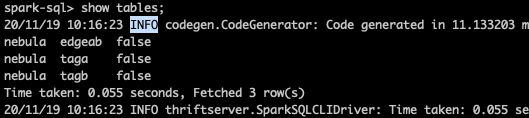
- nebula 版本:1.1.0
- 部署方式(分布式 / 单机 / Docker / DBaaS):Mac下单机 docker部署
- 硬件信息
- 磁盘(SSD / HDD):Mac电脑SSD
- CPU、内存信息:16G
- 问题的具体描述
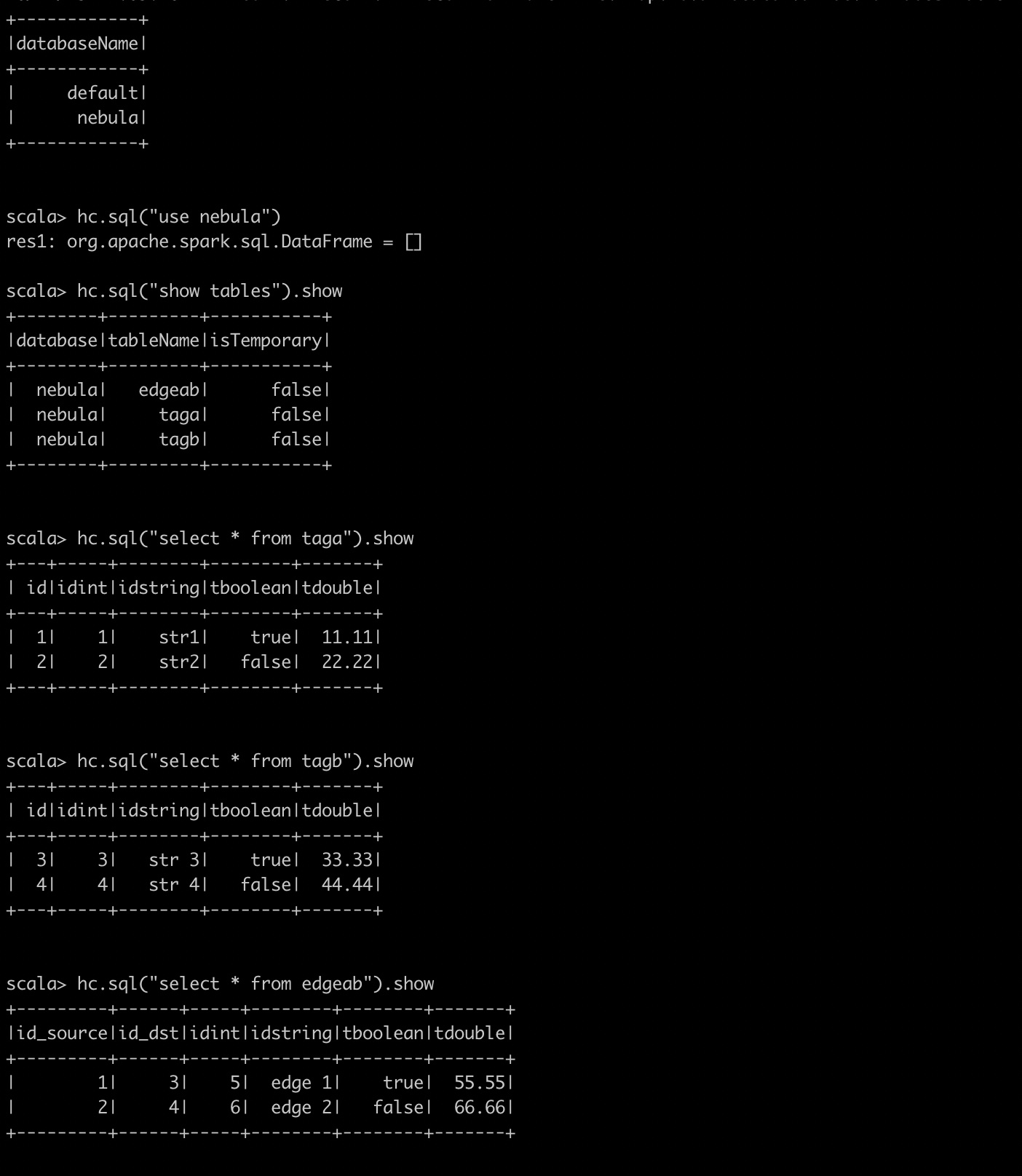
我现在想把hive里面的数据导入到nebula数据库里面。
nebula DDL
CREATE SPACE test_hive(partition_num=10, replica_factor=1); --创建图空间,本示例中假设只需要一个副本
USE test_hive; --选择图空间 test
CREATE TAG tagA(idInt int, idString string, tboolean bool, tdouble double); -- 创建标签 tagA
CREATE TAG tagB(idInt int, idString string, tboolean bool, tdouble double); -- 创建标签 tagB
CREATE EDGE edgeAB(idInt int, idString string, tboolean bool, tdouble double); -- 创建边类型 edgeAB
hive DDL:
CREATE TABLE `tagA`(
`id` bigint,
`idInt` int,
`idString` string,
`tboolean` boolean,
`tdouble` double) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' LINES TERMINATED BY '\n';
insert into tagA select 1,1,'str1',true,11.11;
insert into tagA select 2,2,"str2",false,22.22;
CREATE TABLE `tagB`(
`id` bigint,
`idInt` int,
`idString` string,
`tboolean` boolean,
`tdouble` double) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' LINES TERMINATED BY '\n';
insert into tagB select 3,3,"str 3",true,33.33;
insert into tagB select 4,4,"str 4",false,44.44;
CREATE TABLE `edgeAB`(
`id_source` bigint,
`id_dst` bigint,
`idInt` int,
`idString` string,
`tboolean` boolean,
`tdouble` double) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' LINES TERMINATED BY '\n';
insert into edgeAB select 1,3,5,"edge 1",true,55.55;
insert into edgeAB select 2,4,6,"edge 2",false,66.66;
完整的提交 错误日志
spark-submit --class com.vesoft.nebula.tools.importer.Exchange --master "local[4]" /Users/xurongfei/stonewise/java/nebula-java/tools/exchange/target/exchange-1.0.1.jar -c /Users/xurongfei/stonewise/java/nebula-java/tools/exchange/target/classes/nebula_application.conf
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/Users/xurongfei/stonewise/dataWareHouse/spark-2.4.7-bin-hadoop2.7/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/Users/xurongfei/stonewise/dataWareHouse/hadoop-2.9.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/Users/xurongfei/stonewise/dataWareHouse/apache-hive-2.3.7-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
20/11/18 20:00:52 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
20/11/18 20:00:52 INFO config.Configs$: DataBase Config com.vesoft.nebula.tools.importer.config.DataBaseConfigEntry@68b9c1bd
20/11/18 20:00:52 INFO config.Configs$: User Config com.vesoft.nebula.tools.importer.config.UserConfigEntry@b7df0731
20/11/18 20:00:52 INFO config.Configs$: Connection Config Some(Config(SimpleConfigObject({"retry":3,"timeout":3000})))
20/11/18 20:00:52 INFO config.Configs$: Execution Config com.vesoft.nebula.tools.importer.config.ExecutionConfigEntry@7f9c3944
20/11/18 20:00:52 INFO config.Configs$: Source Config Hive source exec: select idInt,idString,tboolean,tdouble from nebula.taga
20/11/18 20:00:52 INFO config.Configs$: Sink Config Hive source exec: select idInt,idString,tboolean,tdouble from nebula.taga
20/11/18 20:00:52 INFO config.Configs$: name taga batch 256
20/11/18 20:00:52 INFO config.Configs$: Tag Config: Tag name taga source Hive source exec: select idInt,idString,tboolean,tdouble from nebula.taga sink Nebula sink addresses: [192.168.1.110:3699] vertex field idInt vertex policy None batch 256 partition 32
20/11/18 20:00:52 INFO config.Configs$: Source Config Hive source exec: select idInt,idString,tboolean,tdouble from nebula.tagb
20/11/18 20:00:52 INFO config.Configs$: Sink Config Hive source exec: select idInt,idString,tboolean,tdouble from nebula.tagb
20/11/18 20:00:52 INFO config.Configs$: name tagb batch 256
20/11/18 20:00:52 INFO config.Configs$: Tag Config: Tag name tagb source Hive source exec: select idInt,idString,tboolean,tdouble from nebula.tagb sink Nebula sink addresses: [192.168.1.110:3699] vertex field idInt vertex policy None batch 256 partition 32
20/11/18 20:00:52 INFO config.Configs$: Source Config Hive source exec: select id_source,id_dst,idInt,idString,tboolean,tdouble from nebula.edgeab
20/11/18 20:00:52 INFO config.Configs$: Sink Config Hive source exec: select id_source,id_dst,idInt,idString,tboolean,tdouble from nebula.edgeab
20/11/18 20:00:52 INFO config.Configs$: Edge Config: Edge name edgeAB source Hive source exec: select id_source,id_dst,idInt,idString,tboolean,tdouble from nebula.edgeab sink Nebula sink addresses: [192.168.1.110:3699] source field id_source source policy None ranking None target field id_dst target policy None batch 256 partition 10
20/11/18 20:00:52 INFO importer.Exchange$: Config Configs(com.vesoft.nebula.tools.importer.config.DataBaseConfigEntry@68b9c1bd,com.vesoft.nebula.tools.importer.config.UserConfigEntry@b7df0731,com.vesoft.nebula.tools.importer.config.ConnectionConfigEntry@c419f174,com.vesoft.nebula.tools.importer.config.ExecutionConfigEntry@7f9c3944,com.vesoft.nebula.tools.importer.config.ErrorConfigEntry@57104648,com.vesoft.nebula.tools.importer.config.RateConfigEntry@fc4543af,,List(Tag name taga source Hive source exec: select idInt,idString,tboolean,tdouble from nebula.taga sink Nebula sink addresses: [192.168.1.110:3699] vertex field idInt vertex policy None batch 256 partition 32, Tag name tagb source Hive source exec: select idInt,idString,tboolean,tdouble from nebula.tagb sink Nebula sink addresses: [192.168.1.110:3699] vertex field idInt vertex policy None batch 256 partition 32),List(Edge name edgeAB source Hive source exec: select id_source,id_dst,idInt,idString,tboolean,tdouble from nebula.edgeab sink Nebula sink addresses: [192.168.1.110:3699] source field id_source source policy None ranking None target field id_dst target policy None batch 256 partition 10))
20/11/18 20:00:52 INFO spark.SparkContext: Running Spark version 2.4.7
20/11/18 20:00:52 INFO spark.SparkContext: Submitted application: com.vesoft.nebula.tools.importer.Exchange
20/11/18 20:00:52 INFO spark.SecurityManager: Changing view acls to: xurongfei
20/11/18 20:00:52 INFO spark.SecurityManager: Changing modify acls to: xurongfei
20/11/18 20:00:52 INFO spark.SecurityManager: Changing view acls groups to:
20/11/18 20:00:52 INFO spark.SecurityManager: Changing modify acls groups to:
20/11/18 20:00:52 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(xurongfei); groups with view permissions: Set(); users with modify permissions: Set(xurongfei); groups with modify permissions: Set()
20/11/18 20:00:53 INFO util.Utils: Successfully started service 'sparkDriver' on port 54940.
20/11/18 20:00:53 INFO spark.SparkEnv: Registering MapOutputTracker
20/11/18 20:00:53 INFO spark.SparkEnv: Registering BlockManagerMaster
20/11/18 20:00:53 INFO storage.BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
20/11/18 20:00:53 INFO storage.BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
20/11/18 20:00:53 INFO storage.DiskBlockManager: Created local directory at /private/var/folders/ln/bt8f9tr1057dcd04qyrhj4qh0000gn/T/blockmgr-c9eac0e8-5b99-4cc3-89e6-be81245358d0
20/11/18 20:00:53 INFO memory.MemoryStore: MemoryStore started with capacity 366.3 MB
20/11/18 20:00:53 INFO spark.SparkEnv: Registering OutputCommitCoordinator
20/11/18 20:00:53 INFO util.log: Logging initialized @2397ms
20/11/18 20:00:53 INFO server.Server: jetty-9.3.z-SNAPSHOT, build timestamp: unknown, git hash: unknown
20/11/18 20:00:53 INFO server.Server: Started @2475ms
20/11/18 20:00:53 WARN util.Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
20/11/18 20:00:53 WARN util.Utils: Service 'SparkUI' could not bind on port 4041. Attempting port 4042.
20/11/18 20:00:53 INFO server.AbstractConnector: Started ServerConnector@1d12b024{HTTP/1.1,[http/1.1]}{0.0.0.0:4042}
20/11/18 20:00:53 INFO util.Utils: Successfully started service 'SparkUI' on port 4042.
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@78de58ea{/jobs,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4e25147a{/jobs/json,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6b68cb27{/jobs/job,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@56303475{/jobs/job/json,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@30506c0d{/stages,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1dcca8d3{/stages/json,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5631962{/stages/stage,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@19569ebd{/stages/stage/json,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4632cfc{/stages/pool,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6e1f8469{/stages/pool/json,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2e380628{/storage,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3b6c624{/storage/json,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1eaf1e62{/storage/rdd,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@c81fd12{/storage/rdd/json,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@62e6a3ec{/environment,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5754de72{/environment/json,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@31ee96f4{/executors,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@320494b6{/executors/json,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@652ab8d9{/executors/threadDump,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@14fc5d40{/executors/threadDump/json,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@51e0301d{/static,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6bd16207{/,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@298d9a05{/api,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3c0036b{/jobs/job/kill,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@17814b1c{/stages/stage/kill,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO ui.SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.1.110:4042
20/11/18 20:00:53 INFO spark.SparkContext: Added JAR file:/Users/xurongfei/stonewise/java/nebula-java/tools/exchange/target/exchange-1.0.1.jar at spark://192.168.1.110:54940/jars/exchange-1.0.1.jar with timestamp 1605700853377
20/11/18 20:00:53 INFO executor.Executor: Starting executor ID driver on host localhost
20/11/18 20:00:53 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 54941.
20/11/18 20:00:53 INFO netty.NettyBlockTransferService: Server created on 192.168.1.110:54941
20/11/18 20:00:53 INFO storage.BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
20/11/18 20:00:53 INFO storage.BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.1.110, 54941, None)
20/11/18 20:00:53 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.1.110:54941 with 366.3 MB RAM, BlockManagerId(driver, 192.168.1.110, 54941, None)
20/11/18 20:00:53 INFO storage.BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.1.110, 54941, None)
20/11/18 20:00:53 INFO storage.BlockManager: Initialized BlockManager: BlockManagerId(driver, 192.168.1.110, 54941, None)
20/11/18 20:00:53 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3bd3d05e{/metrics/json,null,AVAILABLE,@Spark}
20/11/18 20:00:53 INFO importer.Exchange$: Processing Tag taga
20/11/18 20:00:53 INFO importer.Exchange$: idInt, idString, tboolean, tdouble
20/11/18 20:00:53 INFO importer.Exchange$: Loading from Hive and exec select idInt,idString,tboolean,tdouble from nebula.taga
20/11/18 20:00:54 INFO internal.SharedState: loading hive config file: file:/Users/xurongfei/stonewise/dataWareHouse/spark-2.4.7-bin-hadoop2.7/conf/hive-site.xml
20/11/18 20:00:54 INFO internal.SharedState: spark.sql.warehouse.dir is not set, but hive.metastore.warehouse.dir is set. Setting spark.sql.warehouse.dir to the value of hive.metastore.warehouse.dir ('/Users/xurongfei/stonewise/dataWareHouse/apache-hive-2.3.7-bin/data').
20/11/18 20:00:54 INFO internal.SharedState: Warehouse path is '/Users/xurongfei/stonewise/dataWareHouse/apache-hive-2.3.7-bin/data'.
20/11/18 20:00:54 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4b6e1c0{/SQL,null,AVAILABLE,@Spark}
20/11/18 20:00:54 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@561b61ed{/SQL/json,null,AVAILABLE,@Spark}
20/11/18 20:00:54 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@18d910b3{/SQL/execution,null,AVAILABLE,@Spark}
20/11/18 20:00:54 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1e7ab390{/SQL/execution/json,null,AVAILABLE,@Spark}
20/11/18 20:00:54 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@620c8641{/static/sql,null,AVAILABLE,@Spark}
20/11/18 20:00:54 INFO state.StateStoreCoordinatorRef: Registered StateStoreCoordinator endpoint
Exception in thread "main" org.apache.spark.sql.AnalysisException: Table or view not found: `nebula`.`taga`; line 1 pos 44;
'Project ['idInt, 'idString, 'tboolean, 'tdouble]
+- 'UnresolvedRelation `nebula`.`taga`
at org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt.failAnalysis(package.scala:42)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$$anonfun$checkAnalysis$1.apply(CheckAnalysis.scala:91)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$$anonfun$checkAnalysis$1.apply(CheckAnalysis.scala:86)
at org.apache.spark.sql.catalyst.trees.TreeNode.foreachUp(TreeNode.scala:126)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$foreachUp$1.apply(TreeNode.scala:125)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$foreachUp$1.apply(TreeNode.scala:125)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.apache.spark.sql.catalyst.trees.TreeNode.foreachUp(TreeNode.scala:125)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$class.checkAnalysis(CheckAnalysis.scala:86)
at org.apache.spark.sql.catalyst.analysis.Analyzer.checkAnalysis(Analyzer.scala:95)
at org.apache.spark.sql.catalyst.analysis.Analyzer$$anonfun$executeAndCheck$1.apply(Analyzer.scala:108)
at org.apache.spark.sql.catalyst.analysis.Analyzer$$anonfun$executeAndCheck$1.apply(Analyzer.scala:105)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.markInAnalyzer(AnalysisHelper.scala:201)
at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:105)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:58)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:56)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:48)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:78)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:643)
at com.vesoft.nebula.tools.importer.reader.HiveReader.read(ServerBaseReader.scala:61)
at com.vesoft.nebula.tools.importer.Exchange$.com$vesoft$nebula$tools$importer$Exchange$$createDataSource(Exchange.scala:250)
at com.vesoft.nebula.tools.importer.Exchange$$anonfun$main$2.apply(Exchange.scala:159)
at com.vesoft.nebula.tools.importer.Exchange$$anonfun$main$2.apply(Exchange.scala:152)
at scala.collection.immutable.List.foreach(List.scala:392)
at com.vesoft.nebula.tools.importer.Exchange$.main(Exchange.scala:152)
at com.vesoft.nebula.tools.importer.Exchange.main(Exchange.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:845)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:161)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:184)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:920)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:929)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
20/11/18 20:00:55 INFO spark.SparkContext: Invoking stop() from shutdown hook
20/11/18 20:00:55 INFO server.AbstractConnector: Stopped Spark@1d12b024{HTTP/1.1,[http/1.1]}{0.0.0.0:4042}
20/11/18 20:00:55 INFO ui.SparkUI: Stopped Spark web UI at http://192.168.1.110:4042
20/11/18 20:00:55 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
20/11/18 20:00:55 INFO memory.MemoryStore: MemoryStore cleared
20/11/18 20:00:55 INFO storage.BlockManager: BlockManager stopped
20/11/18 20:00:55 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
20/11/18 20:00:55 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
20/11/18 20:00:55 INFO spark.SparkContext: Successfully stopped SparkContext
20/11/18 20:00:55 INFO util.ShutdownHookManager: Shutdown hook called
20/11/18 20:00:55 INFO util.ShutdownHookManager: Deleting directory /private/var/folders/ln/bt8f9tr1057dcd04qyrhj4qh0000gn/T/spark-58bdc172-700d-4c0f-a053-4e01c2da5162
20/11/18 20:00:55 INFO util.ShutdownHookManager: Deleting directory /private/var/folders/ln/bt8f9tr1057dcd04qyrhj4qh0000gn/T/spark-1630d880-1edf-4964-8f31-e603042aef56
nebula_application.conf文件:
{
# Spark relation config
spark: {
app: {
name: Spark Writer
}
driver: {
cores: 1
maxResultSize: 1G
}
cores {
max: 4
}
}
# Nebula Graph relation config
nebula: {
addresses: ["192.168.1.110:3699"]
user: user
pswd: password
space: test_hive
connection {
timeout: 3000
retry: 3
}
execution {
retry: 3
}
error: {
max: 32
output: /tmp/error
}
rate: {
limit: 1024
timeout: 1000
}
}
# Processing tags
tags: [
# Loading from Hive
{
name: taga
type: {
source: hive
sink: client
}
exec: "select idInt,idString,tboolean,tdouble from nebula.taga"
fields: [idInt,idString,tboolean,tdouble]
nebula.fields: [idInt,idString,tboolean,tdouble]
vertex: {
field: idInt
policy: "hash"
}
vertex: idInt
batch: 256
partition: 32
}
{
name: tagb
type: {
source: hive
sink: client
}
exec: "select idInt,idString,tboolean,tdouble from nebula.tagb"
fields: [idInt,idString,tboolean,tdouble]
nebula.fields: [idInt,idString,tboolean,tdouble]
vertex: {
field: idInt
policy: "hash"
}
vertex: idInt
batch: 256
partition: 32
}
]
# Processing edges
edges: [
# Loading from Hive
{
name: edgeAB
type: {
source: hive
sink: client
}
exec: "select id_source,id_dst,idInt,idString,tboolean,tdouble from nebula.edgeab"
fields: [ idInt,idString,tboolean,tdouble]
nebula.fields: [idInt,idString,tboolean,tdouble]
source: id_source
target: id_dst
batch: 256
partition: 10
}
]
}