docker部署的访问需为docker子网划分出的ip才能访问scan接口。
如目前我主机ip 192.168.1.1, 容器ip为172.28.1.1
就算加了端口映射也只能通过172.28.1.1:45500来访问storage服务
192.168.1.1:45500便会超时。
目前我这边的处理方式在storage镜像里自行加了一层frp内网穿透,才能通过192.168.1.1:45500访问
docker部署的访问需为docker子网划分出的ip才能访问scan接口。
如目前我主机ip 192.168.1.1, 容器ip为172.28.1.1
就算加了端口映射也只能通过172.28.1.1:45500来访问storage服务
192.168.1.1:45500便会超时。
目前我这边的处理方式在storage镜像里自行加了一层frp内网穿透,才能通过192.168.1.1:45500访问
能贴一下启动的文件么?是docker-compose.yml?
对的,docker-compose,swarm也一样
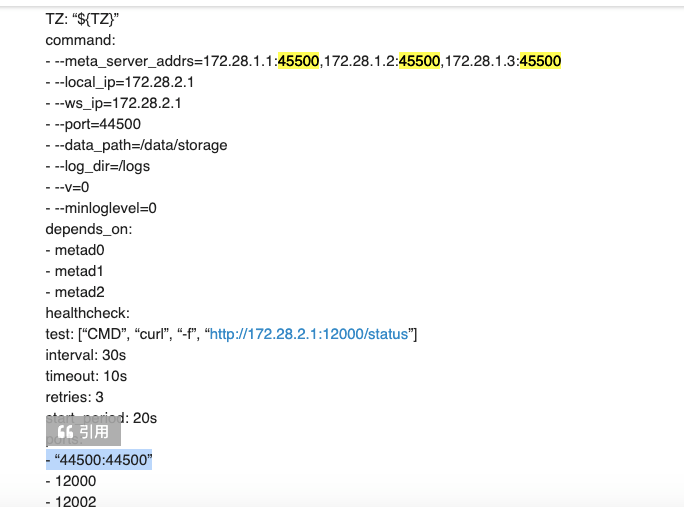
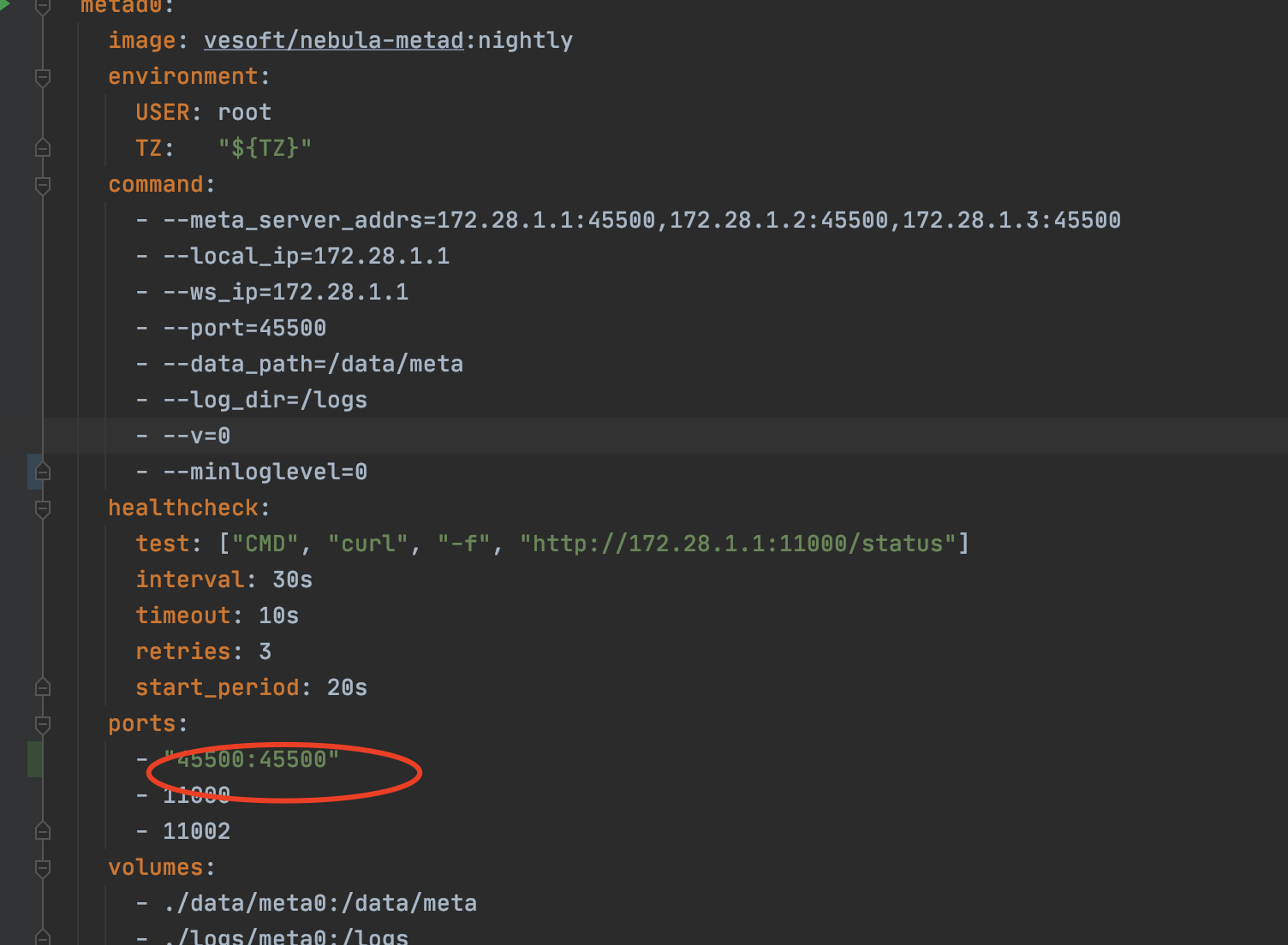
compose文件如下
version: '3.5'
services:
metad0:
image: vesoft/nebula-metad:nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=172.28.1.1:45500,172.28.1.2:45500,172.28.1.3:45500
- --local_ip=172.28.1.1
- --ws_ip=172.28.1.1
- --port=45500
- --data_path=/data/meta
- --log_dir=/logs
- --v=0
- --minloglevel=0
healthcheck:
test: ["CMD", "curl", "-f", "http://172.28.1.1:11000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "45500:45500"
- 11000
- 11002
volumes:
- ./data/meta0:/data/meta
- ./logs/meta0:/logs
networks:
nebula-net:
ipv4_address: 172.28.1.1
restart: on-failure
cap_add:
- SYS_PTRACE
metad1:
image: vesoft/nebula-metad:nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=172.28.1.1:45500,172.28.1.2:45500,172.28.1.3:45500
- --local_ip=172.28.1.2
- --ws_ip=172.28.1.2
- --port=45500
- --data_path=/data/meta
- --log_dir=/logs
- --v=0
- --minloglevel=0
healthcheck:
test: ["CMD", "curl", "-f", "http://172.28.1.2:11000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "45501:45500"
- 11000
- 11002
volumes:
- ./data/meta1:/data/meta
- ./logs/meta1:/logs
networks:
nebula-net:
ipv4_address: 172.28.1.2
restart: on-failure
cap_add:
- SYS_PTRACE
metad2:
image: vesoft/nebula-metad:nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=172.28.1.1:45500,172.28.1.2:45500,172.28.1.3:45500
- --local_ip=172.28.1.3
- --ws_ip=172.28.1.3
- --port=45500
- --data_path=/data/meta
- --log_dir=/logs
- --v=0
- --minloglevel=0
healthcheck:
test: ["CMD", "curl", "-f", "http://172.28.1.3:11000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "45502:45500"
- 11000
- 11002
volumes:
- ./data/meta2:/data/meta
- ./logs/meta2:/logs
networks:
nebula-net:
ipv4_address: 172.28.1.3
restart: on-failure
cap_add:
- SYS_PTRACE
storaged0:
image: vesoft/nebula-storaged:nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=172.28.1.1:45500,172.28.1.2:45500,172.28.1.3:45500
- --local_ip=172.28.2.1
- --ws_ip=172.28.2.1
- --port=44500
- --data_path=/data/storage
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-f", "http://172.28.2.1:12000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "44500:44500"
- 12000
- 12002
volumes:
- ./data/storage0:/data/storage
- ./logs/storage0:/logs
networks:
nebula-net:
ipv4_address: 172.28.2.1
restart: on-failure
cap_add:
- SYS_PTRACE
storaged1:
image: vesoft/nebula-storaged:nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=172.28.1.1:45500,172.28.1.2:45500,172.28.1.3:45500
- --local_ip=172.28.2.2
- --ws_ip=172.28.2.2
- --port=44500
- --data_path=/data/storage
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-f", "http://172.28.2.2:12000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "44501:44500"
- 12000
- 12002
volumes:
- ./data/storage1:/data/storage
- ./logs/storage1:/logs
networks:
nebula-net:
ipv4_address: 172.28.2.2
restart: on-failure
cap_add:
- SYS_PTRACE
storaged2:
image: vesoft/nebula-storaged:nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=172.28.1.1:45500,172.28.1.2:45500,172.28.1.3:45500
- --local_ip=172.28.2.3
- --ws_ip=172.28.2.3
- --port=44500
- --data_path=/data/storage
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-f", "http://172.28.2.3:12000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "44502:44500"
- 12000
- 12002
volumes:
- ./data/storage2:/data/storage
- ./logs/storage2:/logs
networks:
nebula-net:
ipv4_address: 172.28.2.3
restart: on-failure
cap_add:
- SYS_PTRACE
graphd0:
image: vesoft/nebula-graphd:nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=172.28.1.1:45500,172.28.1.2:45500,172.28.1.3:45500
- --port=3699
- --ws_ip=172.28.3.1
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-f", "http://172.28.3.1:13000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "3699:3699"
- 13000
- 13002
volumes:
- ./logs/graph0:/logs
networks:
nebula-net:
ipv4_address: 172.28.3.1
restart: on-failure
cap_add:
- SYS_PTRACE
graphd1:
image: vesoft/nebula-graphd:nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=172.28.1.1:45500,172.28.1.2:45500,172.28.1.3:45500
- --port=3699
- --ws_ip=172.28.3.2
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-f", "http://172.28.3.2:13000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "3700:3699"
- 13000
- 13002
volumes:
- ./logs/graph1:/logs
networks:
nebula-net:
ipv4_address: 172.28.3.2
restart: on-failure
cap_add:
- SYS_PTRACE
graphd2:
image: vesoft/nebula-graphd:nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=172.28.1.1:45500,172.28.1.2:45500,172.28.1.3:45500
- --port=3699
- --ws_ip=172.28.3.3
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-f", "http://172.28.3.3:13000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "3701:3699"
- 13000
- 13002
volumes:
- ./logs/graph2:/logs
networks:
nebula-net:
ipv4_address: 172.28.3.3
restart: on-failure
cap_add:
- SYS_PTRACE
networks:
nebula-net:
name: nebula-net
ipam:
driver: default
config:
- subnet: 172.28.0.0/16
spark reader及python scan 都可以测试
用 FRP 做 docker 的内网穿透,脑洞够大 ~ 
目前是这样处理的,而且可以通了
希望能提供一个更好的方式
只想像访问graphd一样通过docker端口映射使用宿主机ip+3699能够直接访问
Amber rocks!
 帮我解决问题啊
帮我解决问题啊
我发现这样操作目前我本地部署的集群只有我自己能测,别人用我得ip和映射出的端口还是不能用。
详细描述下:
我用frp把metad节点ip穿透出去,其他机器可以通过我得ip和映射出端口访问metad节点,但client连接metad接收到的返回信息中,storage的节点ip还是172.xxx.xxx.xxx,这下穿不出去了,求支招
这应该是个很通用的问题啊,比如想在docker部署的nebula集群下,在已有的spark集群上测试spark reader,或者在其他机器上测试scan接口。
这种使用的方式是会遇到这个问题,这里本质上是让 docker 子网跟 host 主机共享网络的问题,目前一个折中的方案是用 docker 部署一个 spark,在容器内部共享一个 network,后期我们再调研一下其他的解决方案。
你看看这个问题能否给你提供些思路,后面我们有时间了会专门来验证这块 
感觉有点悬,我先试试