yee
2
nebula storage 可以支持多种压缩算法,现在默认使用的是 snappy,可以换成压缩率更高的算法,但是性能也会受到影响。
现在的磁盘占用太大了,我们的目标是在原始数据大小之下。
我觉得你的这个目标比较难达成,nebula 底层使用的 rocksdb,除却写入的原始数据,还会有很多的 WAL 日志文件。
另外看你的 VidType 设置的是 500,你的 vertex id 需要那么大吗?因为在底层存储的时候,不足 500 字节也会自动补空的,也是占用存储。建议你根据实际情况,调整小些
这个FIXED STRING的长度可以浮动吗,而不是固定长度不够补足这种模式,我们的vid一般是在50以下,少量的会过百,极少数的会到200以上,所以这个如果能够浮动,即FIXED STRING代表最大上限最好。
yee
4
FIXED_STRING 目前是不能浮动的,不是类似 VARCHAR 的类型,这里主要是涉及到底层的存储实现,少量的 vertex ID 比较长的情况下,看看前缀会不会重复,能不能考虑使用固定的前缀来做 vertex ID,或者应用层面处理一下?
5 个赞
压缩率比较高的还有哪些?麻烦能告诉下如何设置,然后我们这边结合测试的结果来综合考虑采用哪种压缩方法。如果采用压缩率比较高的算法,这里性能受影响指的是插入的性能还是指所有的比如插入,查询,更新等都受到影响,我们有做过这方面的测试吗?
1。 考虑应用层简单改造下?
比如 前缀 64位 AND/OR base64(全部)。
一般来说,类似数据库主键都不应该太长,这样不利于查询性能。
- 根据存储引擎的机制(LSM-tree),会有存储放大(已经用了压缩snappy)。经验值是1-2倍。
如果做硬盘容量评估,参考 https://docs.nebula-graph.com.cn/manual-CN/3.build-develop-and-administration/3.configurations/0.system-requirement/#3
yee
7
支持的压缩算法可以参见这个PR: vesoft-inc/nebula#2179
我们本地简单做过一些对比测试,还没有正式开展这块的工作,结论是:lz4跟snappy压缩ratio一样,压缩快50%,解压快一倍
请教下,既然lz4的压缩也快,解压也快,那我们默认没用lz4压缩的原因在哪?
yee
9
原来是因为 thirdparty 中的一些 lib 还没支持,后来升级之后,默认可以改成 lz4
你好,我重复入库一条数据150万次,这条数据会创建三个点和三条边,每次重复入库创建的点和边的vid都是一样的,也就是150万次入库后库中依然是只有三个点和三条边,但是查看内存占用情况,data目录居然占用了2.6G(测试前的data目录大小是71M),然后一段时间之后,data又变成了1.9G,请问这个和rocksdb的WAL日志有关吗,有没有办法降低磁盘占用,毕竟只有一条数据,却占用这么多,大大超过了我们业务的可承受范围。
磁盘占用情况:

space中点和边的数量:

重复数据也会占空间,这些数据会在compaction的时候释放
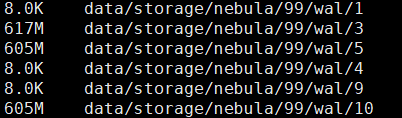
这里占有空间最大的WAL目录有没有优化的空间呢,怎么减少这些空间占用呢?
目前来看,单纯的数据占用空间还可以,主要是日志占用的空间太大了,看看这部分有没有优化的可能。
你好,我配置了rocksdb的这台配置,但是没有生效,这个是什么问题呢?
UPDATE CONFIGS storage:rocksdb_db_options = { max_total_wal_size = 10 };
这项配置我在/data/storage/nebula/199/data/LOG的rocksdb启动日志里查看是已经存在了,但是没生效,不知道什么原因:
storage有个参数叫wal_ttl 不是rocksdb的wal
这项wal_ttl代表什么意思呢,可以减少wal日志存储的磁盘占用吗,对入库性能有没有影响?
我配置了60,应该是60秒吧,但是感觉也没生效。
我重复入库同一条数据,wal的占用一直在上涨,涨到70多G时,wal的占用又立刻减少到7G左右,然后又这样循环往复。