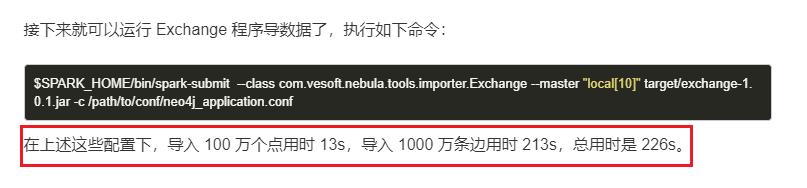
neo4j这边是线上的一个Follower节点拉数据。
nebula这边是在同一台服务器部署三副本,配置文件用的企业版推荐配置,space 10个partition。
导入命令和部分配置
# 导入命令
$ nohup spark-submit --class com.vesoft.nebula.tools.importer.Exchange --master "local" exchange-1.0.1.jar -c xxx.conf > xxxx.log &
# conf配置
# Spark relation config
spark: {
app: {
name: Spark Writer
}
driver: {
cores: 8
maxResultSize: 16G
}
cores {
max: 16
}
}
……
#向一个graphd写
addresses: ["xxxxx:3699"]
# 从一个neo4j Follower节点读
bolt://xxxx:7687
……
# vid 都用的uuid
policy: "uuid"
……
partition: 10
batch: 1000
点和边的数据也都比较简单
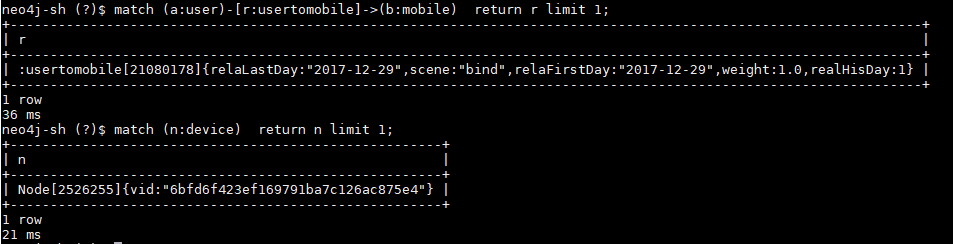
目前导入了几亿的数据,大概统计了一下使用Exchange的导入效率,感觉有点慢,可能是我的配置不是很优化。排除在同一台机器部署三副本nebula的限制,spark配置,spark命令参数或者nebula配置参数还有没有建议的可提速优化的配置?@nicole 辛苦帮忙看看~
点:1000+左右条/秒
边:800左右条/秒