- nebula 版本:Nebula Graph 1.0
- 部署方式(分布式 / 单机 / Docker / DBaaS):Docker
- 问题的具体描述

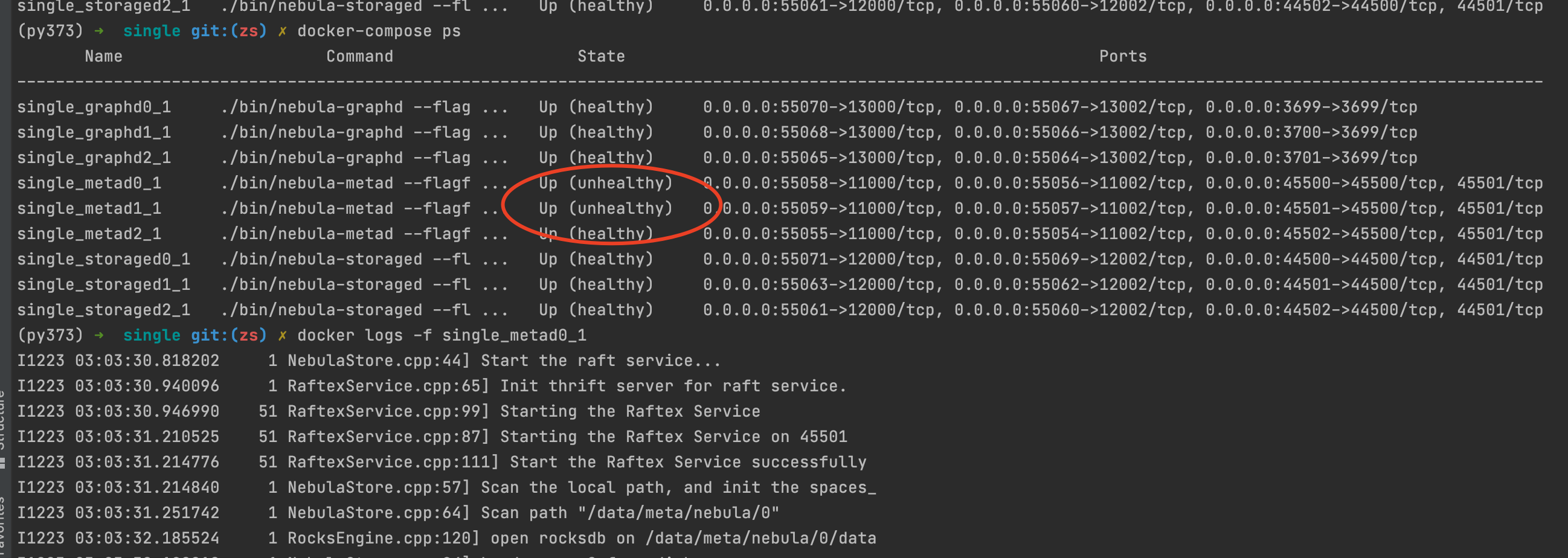
meta日志:
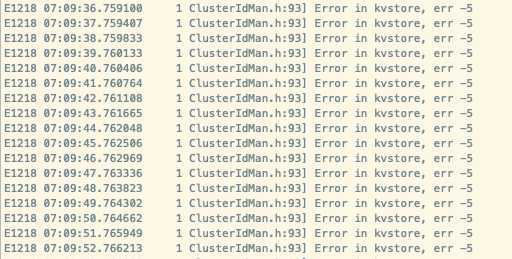
storage日志:

studio错误:
![]()
meta日志:
storage日志:
studio错误:
![]()
吧 meta 0 跟 meta 1 停了试试?
一样timed out
yaml文件发来看下
一样的问题+1
我的 yaml 应该是GitHub那个,好像没改
version: '3.4'
services:
metad0:
image: vesoft/nebula-metad:nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=172.28.1.1:45500,172.28.1.2:45500,172.28.1.3:45500
- --local_ip=172.28.1.1
- --ws_ip=172.28.1.1
- --port=45500
- --data_path=/data/meta
- --log_dir=/logs
- --v=0
- --minloglevel=0
healthcheck:
test: ["CMD", "curl", "-f", "http://172.28.1.1:11000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "45500:45500"
- 11000
- 11002
volumes:
- ./data/meta0:/data/meta
- ./logs/meta0:/logs
networks:
nebula-net:
ipv4_address: 172.28.1.1
restart: on-failure
cap_add:
- SYS_PTRACE
metad1:
image: vesoft/nebula-metad:nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=172.28.1.1:45500,172.28.1.2:45500,172.28.1.3:45500
- --local_ip=172.28.1.2
- --ws_ip=172.28.1.2
- --port=45500
- --data_path=/data/meta
- --log_dir=/logs
- --v=0
- --minloglevel=0
healthcheck:
test: ["CMD", "curl", "-f", "http://172.28.1.2:11000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "45501:45500"
- 11000
- 11002
volumes:
- ./data/meta1:/data/meta
- ./logs/meta1:/logs
networks:
nebula-net:
ipv4_address: 172.28.1.2
restart: on-failure
cap_add:
- SYS_PTRACE
metad2:
image: vesoft/nebula-metad:nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=172.28.1.1:45500,172.28.1.2:45500,172.28.1.3:45500
- --local_ip=172.28.1.3
- --ws_ip=172.28.1.3
- --port=45500
- --data_path=/data/meta
- --log_dir=/logs
- --v=0
- --minloglevel=0
healthcheck:
test: ["CMD", "curl", "-f", "http://172.28.1.3:11000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "45502:45500"
- 11000
- 11002
volumes:
- ./data/meta2:/data/meta
- ./logs/meta2:/logs
networks:
nebula-net:
ipv4_address: 172.28.1.3
restart: on-failure
cap_add:
- SYS_PTRACE
storaged0:
image: vesoft/nebula-storaged:nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=172.28.1.1:45500,172.28.1.2:45500,172.28.1.3:45500
- --local_ip=172.28.2.1
- --ws_ip=172.28.2.1
- --port=44500
- --data_path=/data/storage
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-f", "http://172.28.2.1:12000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "44500:44500"
- 12000
- 12002
volumes:
- ./data/storage0:/data/storage
- ./logs/storage0:/logs
networks:
nebula-net:
ipv4_address: 172.28.2.1
restart: on-failure
cap_add:
- SYS_PTRACE
storaged1:
image: vesoft/nebula-storaged:nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=172.28.1.1:45500,172.28.1.2:45500,172.28.1.3:45500
- --local_ip=172.28.2.2
- --ws_ip=172.28.2.2
- --port=44500
- --data_path=/data/storage
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-f", "http://172.28.2.2:12000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "44501:44500"
- 12000
- 12002
volumes:
- ./data/storage1:/data/storage
- ./logs/storage1:/logs
networks:
nebula-net:
ipv4_address: 172.28.2.2
restart: on-failure
cap_add:
- SYS_PTRACE
storaged2:
image: vesoft/nebula-storaged:nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=172.28.1.1:45500,172.28.1.2:45500,172.28.1.3:45500
- --local_ip=172.28.2.3
- --ws_ip=172.28.2.3
- --port=44500
- --data_path=/data/storage
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-f", "http://172.28.2.3:12000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "44502:44500"
- 12000
- 12002
volumes:
- ./data/storage2:/data/storage
- ./logs/storage2:/logs
networks:
nebula-net:
ipv4_address: 172.28.2.3
restart: on-failure
cap_add:
- SYS_PTRACE
graphd0:
image: vesoft/nebula-graphd:nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=172.28.1.1:45500,172.28.1.2:45500,172.28.1.3:45500
- --port=3699
- --ws_ip=172.28.3.1
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-f", "http://172.28.3.1:13000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "3699:3699"
- 13000
- 13002
volumes:
- ./logs/graph0:/logs
networks:
nebula-net:
ipv4_address: 172.28.3.1
restart: on-failure
cap_add:
- SYS_PTRACE
graphd1:
image: vesoft/nebula-graphd:nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=172.28.1.1:45500,172.28.1.2:45500,172.28.1.3:45500
- --port=3699
- --ws_ip=172.28.3.2
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-f", "http://172.28.3.2:13000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "3700:3699"
- 13000
- 13002
volumes:
- ./logs/graph1:/logs
networks:
nebula-net:
ipv4_address: 172.28.3.2
restart: on-failure
cap_add:
- SYS_PTRACE
graphd2:
image: vesoft/nebula-graphd:nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=172.28.1.1:45500,172.28.1.2:45500,172.28.1.3:45500
- --port=3699
- --ws_ip=172.28.3.3
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-f", "http://172.28.3.3:13000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "3701:3699"
- 13000
- 13002
volumes:
- ./logs/graph2:/logs
networks:
nebula-net:
ipv4_address: 172.28.3.3
restart: on-failure
cap_add:
- SYS_PTRACE
networks:
nebula-net:
ipam:
driver: default
config:
- subnet: 172.28.0.0/16
docker部署,全都是默认配置
看眼unhealthy的docker里面进程还在不在 如果在截个日志的图我看下
知道问题了,今天修。

问题修复了吗?
问题修复了吗?
fixed
Studio链接还是报一样的错
服务正常么
服务状态显示正常
studio和nebula 是部署在同一台本机上吗?