-
nebula 版本:v1.1.0
-
部署方式:Docker部署
-
硬件信息
- 磁盘:SSD高性能云盘,500GB / storage pod
- CPU、内存信息:8核 + 32 GB / storage pod, 2核 + 8G / graphd pod
-
问题的具体描述
Docker集群部署,一共包含3meta + 3 graphd + 13 storaged,配置基本信息如上所示。
使用查询的时候,会有一定概率出现"Get neighbors failed" 错误提示
nebula 版本:v1.1.0
部署方式:Docker部署
硬件信息
问题的具体描述
Docker集群部署,一共包含3meta + 3 graphd + 13 storaged,配置基本信息如上所示。
使用查询的时候,会有一定概率出现"Get neighbors failed" 错误提示
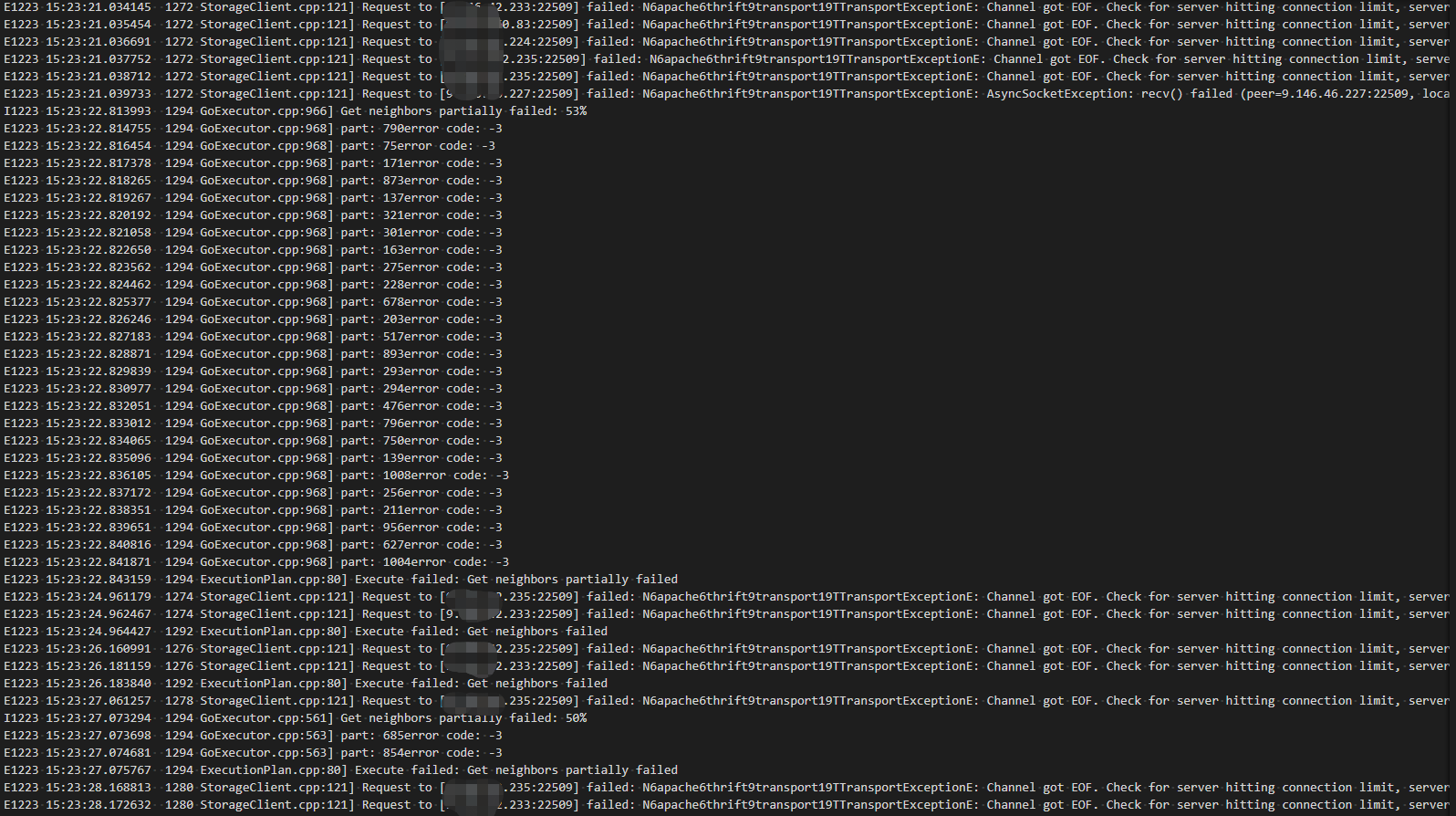
你好,帮忙把 graph的INFO和ERROR日志贴一下吗
报错信息里写的是 超过最大连接数了, 您这个 partition 数是多少? 看着都上 1000 了, 可以设小一点吗?
有没有重启过。
任何一个storaged的重启,都最好把全集群重启下(storaged client缓存的issue)。
最大连接数的是多少呢,是否可以调整呢??。。partition数确实是比较大,设置值为1024,能够在不drop space的前提下修改partition数量么?
这个我刚刚连带所有storage/graph/meta全部重启了。。依旧有这个问题……
能够在不drop space的前提下修改partition数量么?
不行… partition 默认应该是 100, 后来应该改成了 10.
最大连接数的是多少呢,是否可以调整呢?随手找了下帖子, 您可以参考下
https://blog.csdn.net/guowake/article/details/6615728
你还是把graphd的日志贴一下吧
我总共13个storaged,space有1024个partition,每个storage也就80个左右的partition,应该不会遇到你说的超过socket限制的问题吧。。。另外我看了容器,使用ulimt -n查看限制数,感觉应该不是这个问题。
![]()
你确定这些机器都在一个机房?
中间没发生什么断联啥的? 是不是几个docker在比较远的机房啊?
或者没有其他请求在竞争?
然后多执行几次(10次),把graphd和storaged日志发一下呢。
这个看上去就是断链或者leader切换过了。
ifconfig eth0 看一下网卡提供的信息呢? log 反映出来的就是网络不稳定.