为了更快地定位、解决问题,麻烦参考下面模版提问 ^ ^
提问参考模版:
nebula 版本:1.1.0
部署方式 分布式
硬件信息
磁盘 阿里云高效云盘
CPU、内存信息:阿里云ECS 8C/32GB
执行操作:
期望和问题:
数据量不大,40min有点异常。建议插入数据后做一下compact,然后再rebuild index .
还有如下问题:
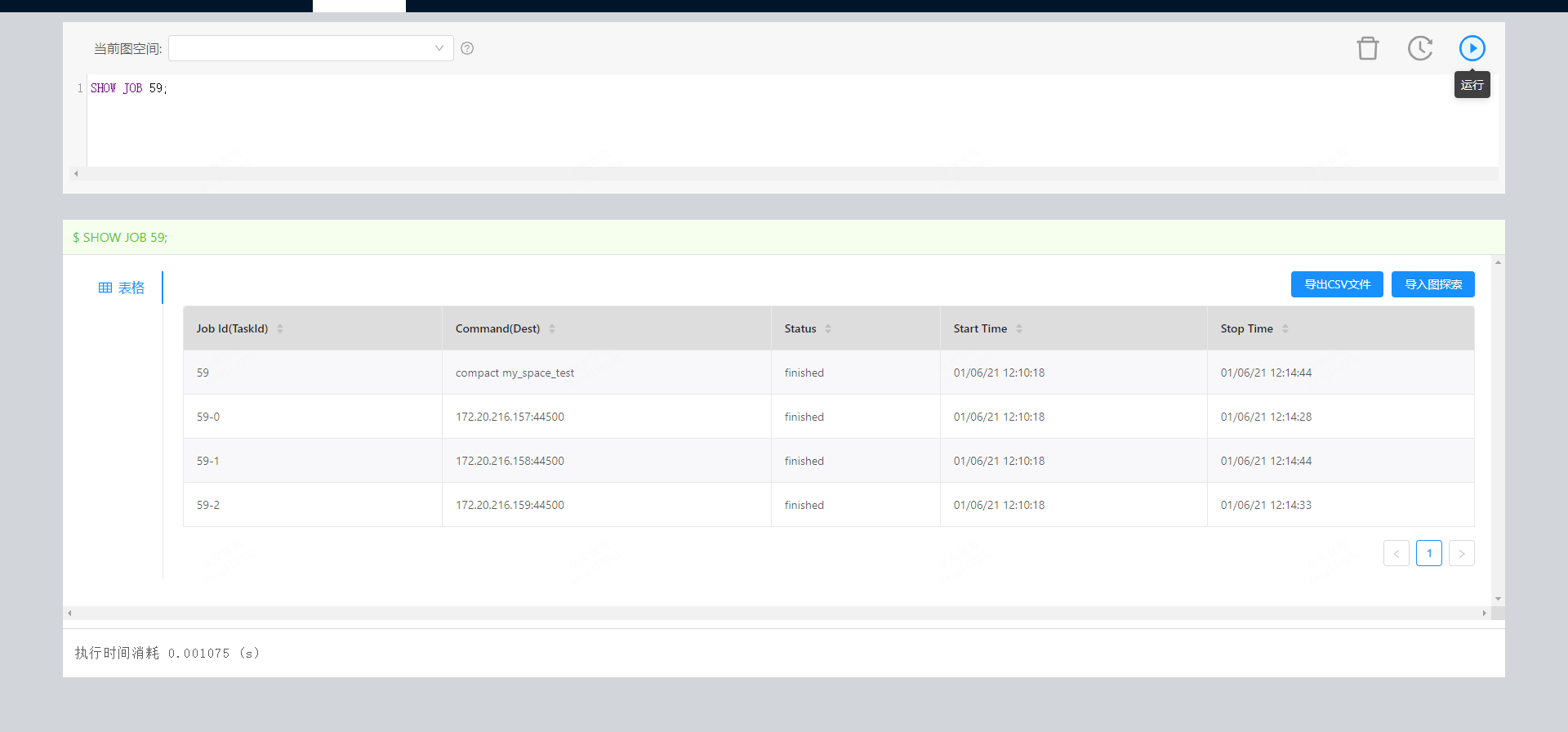
经排查,我们这边有一个storaged节点挂了,我随后拉了起来。
kevin
2021 年1 月 6 日 03:47
6
我在测试的时候rebuild,也出现过storaged挂掉的情况。后来直接把auto_compact打开了,index也提前建好
auto compact 是下面的参数么? 默认好像是开着的。
我测试环境配的内存比较少,找给了2gb给rockdb~~
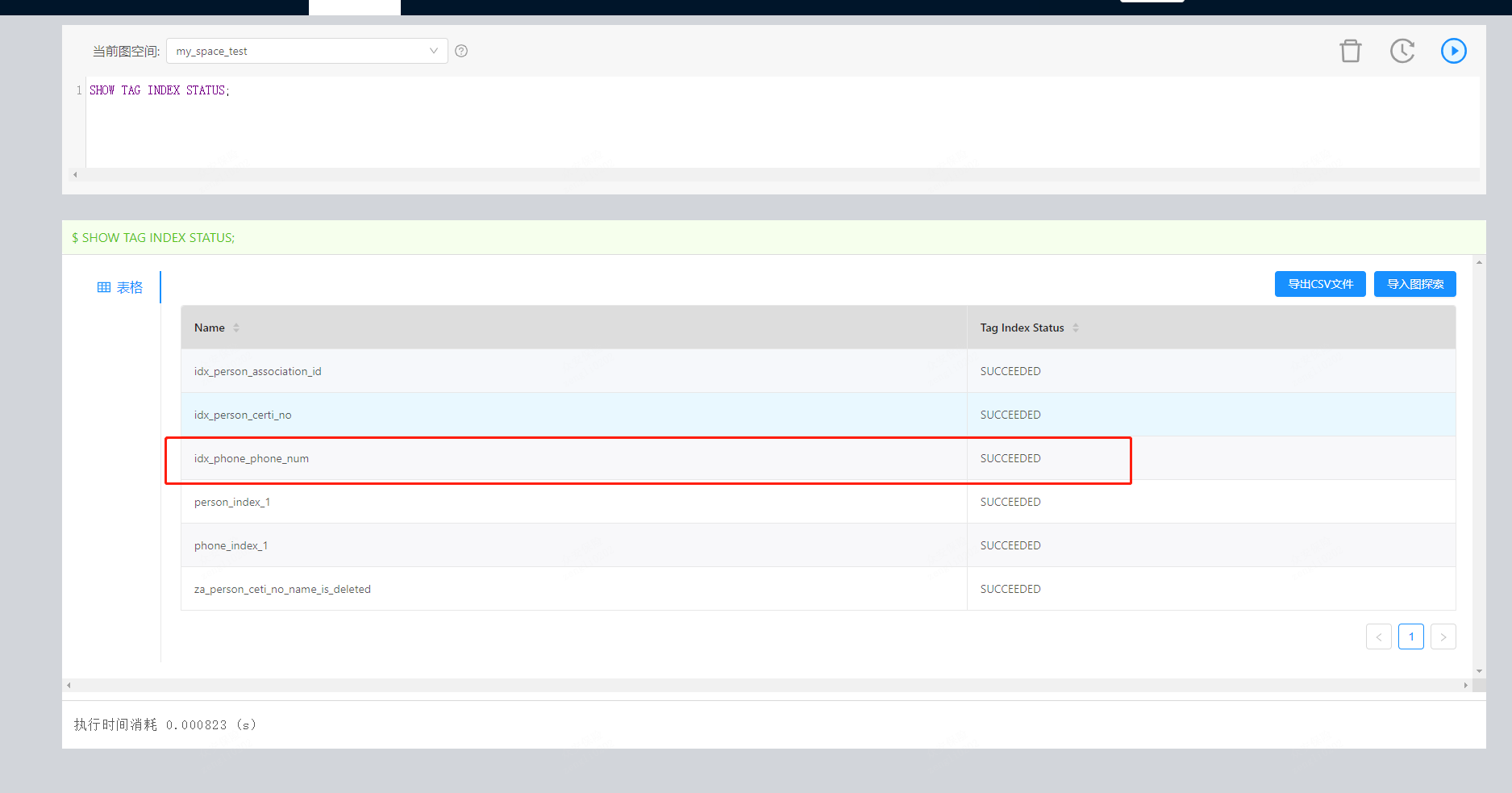
现在执行完compact之后,是不是只能等了,等compact完之后,tag index 的状态会更新么?
compact执行完了之后重新rebuild就可以了,不过看内存确实少了点,搞不好还会oom。
为了避免OOM,可以把这个参数改小点
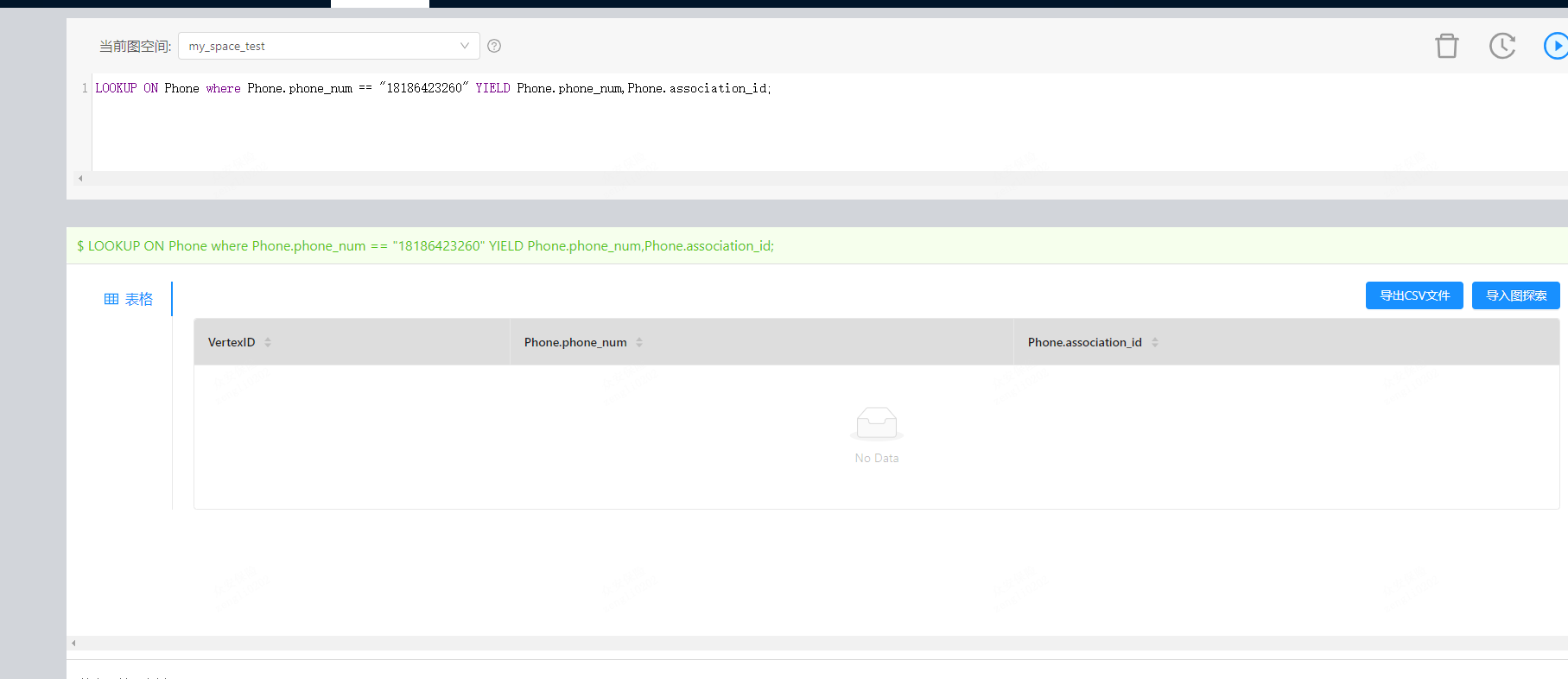
貌似出现了一点问题,我重建索引之后,发现数据是插入了,但是通过索引字段无法查询。
bright-starry-sky:
rebuild_index_batch_num
加了,后面问题发现了,rebuild之前,挂了一个storage节点,虽然成功了,但是部分数据不可见。再拉起storaged之后,删除原索引,并重建rebuild之后,数据查询正常。
1 个赞
那因该就是这个问题,vertex是根据part的hash值分布的,某个part挂了,会导致数据查不到。
1 个赞
part不是有副本的么,针对索引part副本不会有效么?
很好的问题,也是很好的建议。nebula的多副本是被分配到了多个节点上,但是这个问题往往出现在part的选举和被选举的阶段,这个阶段相当于没有leader存在,所以导致了这个问题。后续我们将考虑协议层的retry机制来解决这个问题。
1 个赞
jjgg
2022 年3 月 24 日 06:06
21
您好,rebuild_index_batch_num大小与数据量以及内存大小有述职参考吗?