- nebula 版本:v2.0.0-rc1
- 部署方式:单机
- 硬件信息
- 磁盘: SSD, fio seq write 546MB/s, seq read 502MB/s
- CPU、内存信息:32C/128G
- 出问题的 Space 的创建方式:
- 问题的具体描述
测试match查询性能时发现结果不如预期
match (v:intranet_ip{ip:"172.16.100.10"}) -[access]- (v2) return v2.name
结果用时30+s
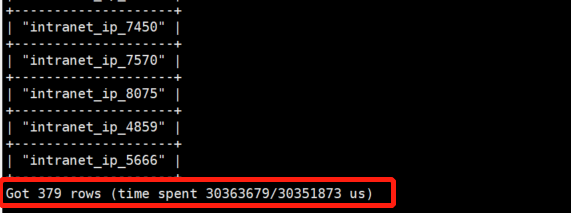
觉得这个慢的不太合理,但不知道原因
相关schema如下
create tag intranet_ip(ip string, name string)
create tag index intranet_ip_index_0 on intranet_ip(ip(10), name(5))
create edge access(name string)
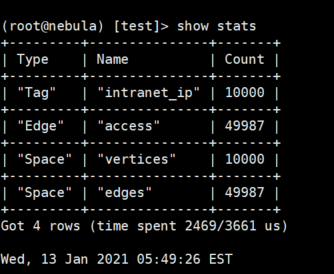
数据量如下,平均每个节点有5个边
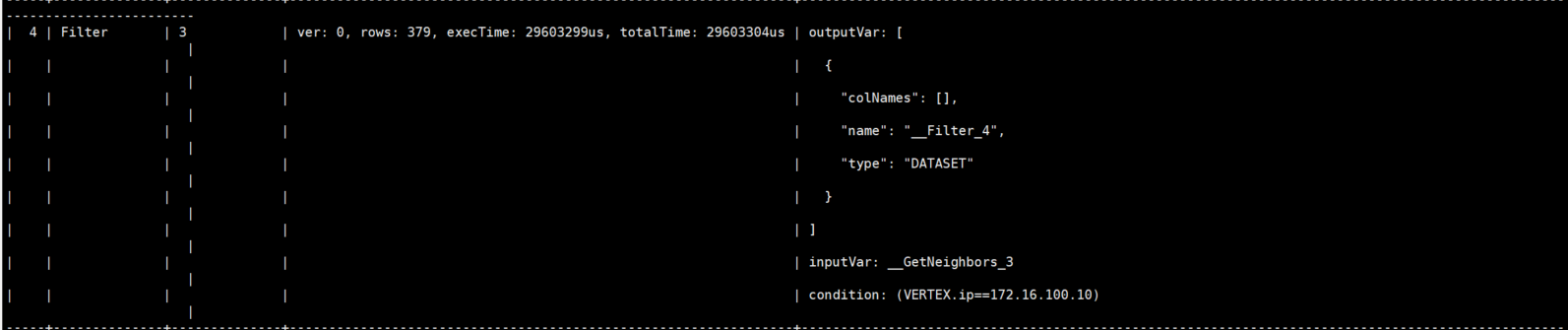
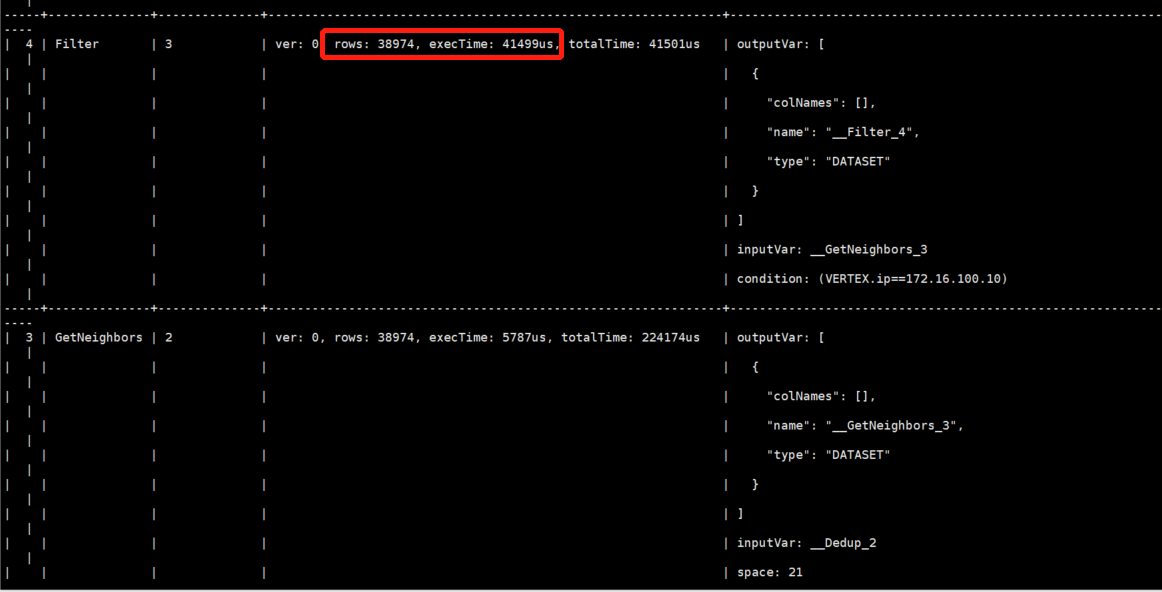
profile 发现时间主要消耗在这个环节:
是index的配置有问题么
yee
2
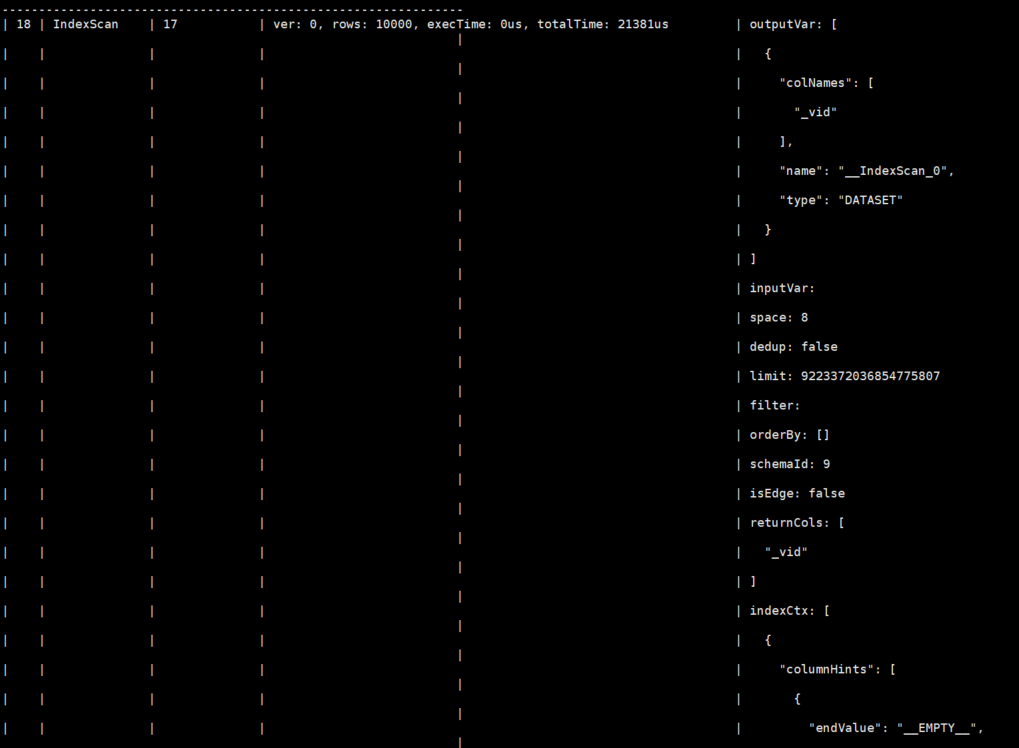
把 PROFILE 中 IndexScan 的时间和 rows 也截图贴一下!怀疑是不是没有能够选到合适的索引?
但即使是没有选到合适的索引,毕竟一共才10000条记录,全表扫描能用30s也有点奇怪
是不是对GetNeighbors的结果做Filter时没有利用到索引?这一批数据大概有10w条
yee
6
由描述可知几个问题陈述如下:
- 为什么没有选到合适的索引?
看创建的 intranet_ip_index_0 是一个多列的联合索引 ip 和 name ,但是在 match 中只指定了 ip,估计是这里的原因导致没有选中索引,而是全表扫描。
这种情况如何更好的处理,还需要请 @bright-starry-sky 来具体分析一下。
- Filter 为什么这么慢?
此处又引申出来两个问题,一个是 Filter 算子没有下推到 GetNeighbors,第二个是 Filter 算子本身执行速度慢。
第一个问题,需要添加合适的优化规则来做过滤下推,这块我们会尽快将上述的规则添加到优化器中;下推之后过滤会在 storage 层面做,会加速整个 Query 的执行效率;目前没有下推,全是在 Query 层做 string 表达式的过滤。这里需要确定 nebula 的优化器选项是否开启,在 etc/nebula-graphd.conf 中的 enable_optimizer=true 设置。
第二个问题,我们最近一直再做性能调优的工作,目前可能会有部分地方实现不合理,后续会在 GA 之前将热点函数都排查一遍。
感谢你的反馈,我们会将你提供的场景加入到我们的测试环境中来监控 nebula 相关的性能。
我看你的创建的ip索引长度只有10,你的ip长度都13了,也就是假如,你的IP全部是"172.16.100."开头的都会被匹配到。你这种情况建的索引就命中很低了。
1 个赞
从profile的结果来看,确实存在你所说的问题,应该是索引长度不合适导致的索引未生效,因为IndexScan之后的rows是10000,就是全表扫描的结果,也就是说索引没有过滤出我指定的"172.16.100.10"的子集,我尝试重建索引后,match的耗时就很正常了
create tag index intranet_ip_index_0 on intranet_ip(ip(20), name(10))
另外问一句,如果我通过将index length设置的尽量长来规避上述问题,会带来哪些负面影响(比如写入速度变慢 or 更多的内存/磁盘消耗?)
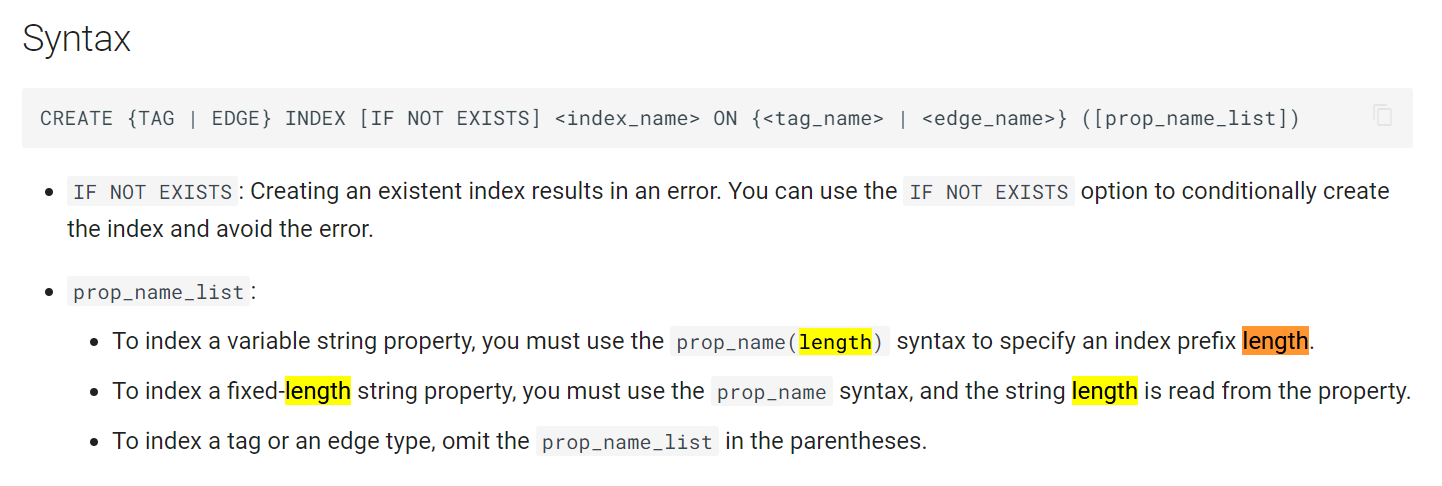
我又翻了下手册,发现手册中创建索引一节中没有提到索引长度对搜索性能的影响
虽然后面有提到
但对于初学者而言,过于隐晦了,建议将索引长度的影响加入手册中CREATE INDEX这一节中,帮助用户合理创建索引
检查了一下,etc/nebula-graphd.conf中的enable_optimizer=false,这是默认配置没有调整过
我尝试将enable_optimizer=true打开,发现对整体结果影响并不是很大
因为我整体的测试数据集并不是很大,在生产环境中,即使索引正常工作,初筛出来的neighbors数量也可能超过10w,这种情况filter还是会导致慢查询
期待GA版本能够修复该性能问题~
感谢您的反馈,关于索引中fixed_string的长度问题我们将会在手册手说明一下。
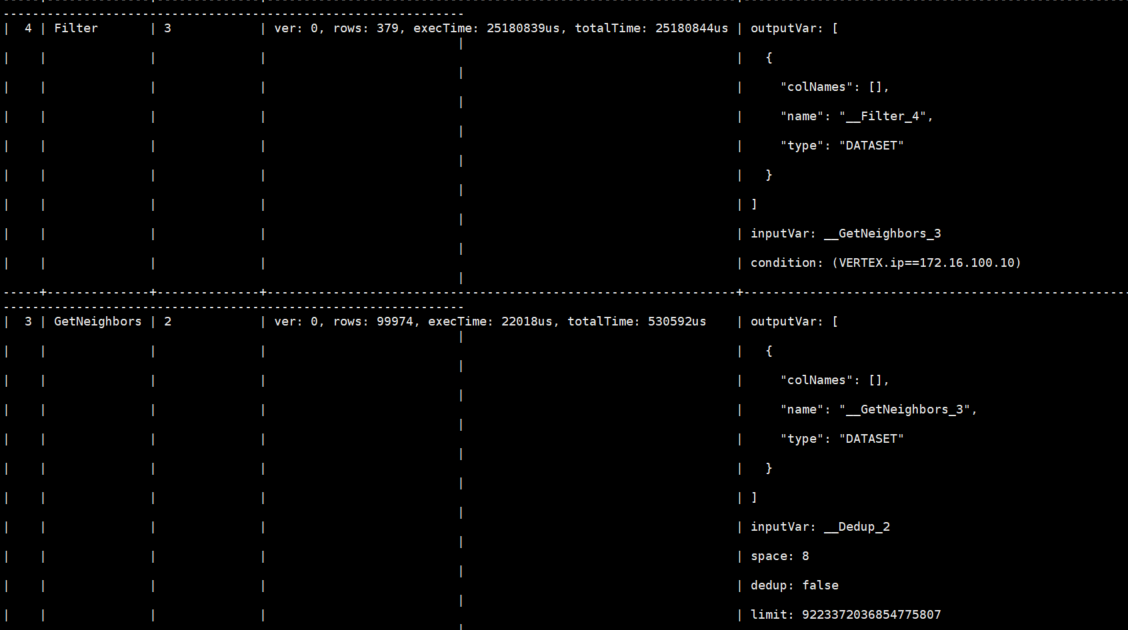
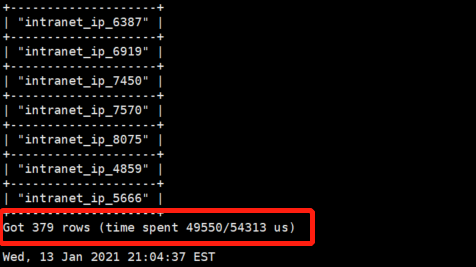
补充一下后续测试结果,我将原测试用例的数据量放大了100倍(10000->1m),修复index长度的情况下对相同的查询做了一次profiler
这次的数据量和之前基本在一个量级(38974 vs 99974),但是filter的耗时比较正常,从这个结果来看,感觉不单纯是filter性能的问题?
以下是原查询的profile
yee
14
从上面的 profiling 看出来,虽然是同一个量级的 rows,但是上面的那个其实是没有执行任何一行数据的过滤的,但是下面的是实实在在进行了过滤的,在 filter 中如果做了过滤就会牵涉到数据的移动,这块我们后续会做相应的调优。目前怀疑的一个地方是内存的搬运,不过这个要等热点代码出来以后才能定论。