- nebula 版本:2.0.0 rc
- 部署方式 Docker
采用下面的语句进行节点属性查询时:
```
FETCH PROP ON entity “1011385”, “1023238”, “125452” YIELD entity.name;
```
得到的结果为
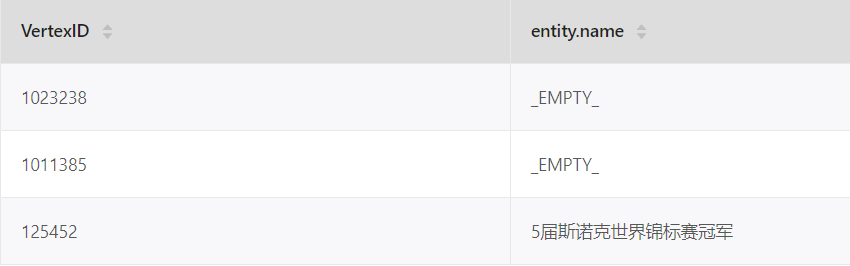
请问怎么能让输出顺序和输入顺序一致呢~谢谢!
采用下面的语句进行节点属性查询时:
```
FETCH PROP ON entity “1011385”, “1023238”, “125452” YIELD entity.name;
```
得到的结果为
请问怎么能让输出顺序和输入顺序一致呢~谢谢!
这个目前是没有控制顺序的,请问你是在什么场景下有这个需求呢?
后面使用 ORDER BY 就可以啊
他应该只是说在不使用排序的情况下,查询的时候列的字段顺序能否与输出结果保持一致吧?
那应该不可以,两个vertex的值不同,先执行那个不确定
嗯嗯,所以现在只能是用 ORDER BY 去按照 VertexID 从大到小或者从小到大排是吗?因为我看vertexID 是有节点的 ID 和 属性的 ID 两种不一样的, 我现在为了方便是都设置的一样的,不知道这样可不可以。
另外就是我现在直接是用自然数生成的索引,那我现在想往里再插入元素的时候,是需要自己再去找到数据库里最大的索引值,往上加一变成新的索引吗?
我是想要查找的节点属性名称和关系名称对应上,我全部都用从小到大去排列也可以的。
嗯,那你直接用order by吧,但从查询顺序是没有特意这样处理的
我看vertexID 是有节点的 ID 和 属性的 ID 两种不一样的, 我现在为了方便是都设置的一样的,不知道这样可不可以。
另外就是我现在直接是用自然数生成的索引 (用了字符串的形式,还没改成 64 位 int),那我现在想往里再插入元素的时候,是需要自己再去找到数据库里最大的索引值,往上加一变成新的索引吗?Nebula 可以直接设置自增 ID 吗?
您的意思是把VID用于prop value,然后通过这种方式对VID和prop value做一个对应,对吗?这样的话,你又不知道这个VID应该怎么自增,并保持唯一?我理解的对吗?
嗯嗯,对的,是这个意思。我现在在开发基于 nebula 的知识图谱 API, 所以在插入三元组的时候,需要 ID 能自动自增。
同时也要让输出 prop value 的时候,能查询到对应的 vertex 以及附近一圈的节点的属性和关系
需求大概了解了,我说下我的想法:
这个需求如果通过fetch查询的话,貌似走不通了,因为如果把vid和prop写成一样的话,fetch查询可能就有点多余了,因为fetch是查询已知的VIDs,如果这样写的话,那prop也是已知的了;另一个是关键的问题,nebula目前没有对vid做自增的功能,也没有查询最大VID的功能。
根据如上所说的需求,我想能不能用另一种办法解决?对这个tag的关键props创建一个index,通过lookup来查询出复合条件的vertices,然后通过pipe go 操作来计算出你所需要的节点属性和节点关系?
嗯嗯好的,我试一下~
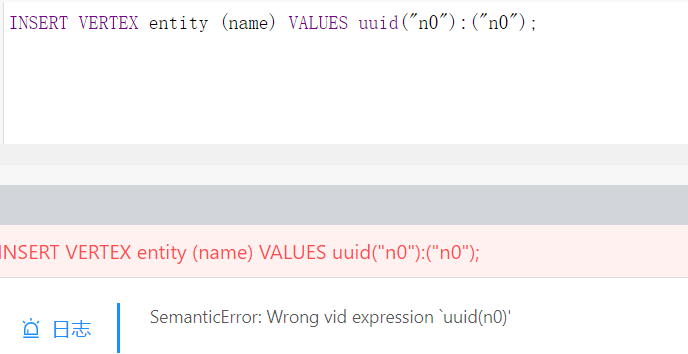
另外还想再问一下,生成 UUID 的时候,我按照网上的教程写的,但是一直会报 Wrong vid expression `uuid(n0)’ 的错,请问要怎么改呀~
已回复
