提问参考模版:
-
nebula 版本:1.2
-
部署方式(分布式 / 单机 / Docker / DBaaS):分布式
-
硬件信息
- 磁盘( 推荐使用 SSD)
- CPU、内存信息:
-
出问题的 Space 的创建方式:
-
问题的具体描述
查询数据失败概率太高了,6次才成功一次:
提问参考模版:
nebula 版本:1.2
部署方式(分布式 / 单机 / Docker / DBaaS):分布式
硬件信息
出问题的 Space 的创建方式:
问题的具体描述
查询数据失败概率太高了,6次才成功一次:
你好,storage的log里是什么错误信息?
log在那个目录下?
你的安装目录, 一般是/usr/local/nebula里的 logs目录
把nebula-storaged.INFO贴出来
storaged日志没有报错,
graphd日志:
E0125 11:29:29.361738 84304 StorageClient.inl:123] Request to [10.196.97.10:44500] failed: N6apache6thrift9transport19TTransportExceptionE: Channel got EOF. Check for server hitting connection limit, server connection idle timeout, and server crashes.
E0125 11:29:29.361953 84392 ExecutionPlan.cpp:80] Execute failed: Get tag props failed
E0125 11:29:30.278616 84392 ExecutionPlan.cpp:80] Execute failed: Get tag props failed
E0125 11:29:32.706200 84308 StorageClient.inl:123] Request to [10.196.97.10:44500] failed: N6apache6thrift9transport19TTransportExceptionE: Channel got EOF. Check for server hitting connection limit, server connection idle timeout, and server crashes.
E0125 11:29:32.706426 84392 ExecutionPlan.cpp:80] Execute failed: Get tag props failed
E0125 11:29:34.429270 84394 ExecutionPlan.cpp:80] Execute failed: Get tag props failedserver已经crash掉了? 你执行scripts/nebula.service status all看下服务状态。
没有crash,集群20台集群,每台的storage和graph都是running:
[INFO] nebula-graphd: Running as 30621, Listening on 3699
[INFO] nebula-storaged: Running as 116208, Listening on 44500
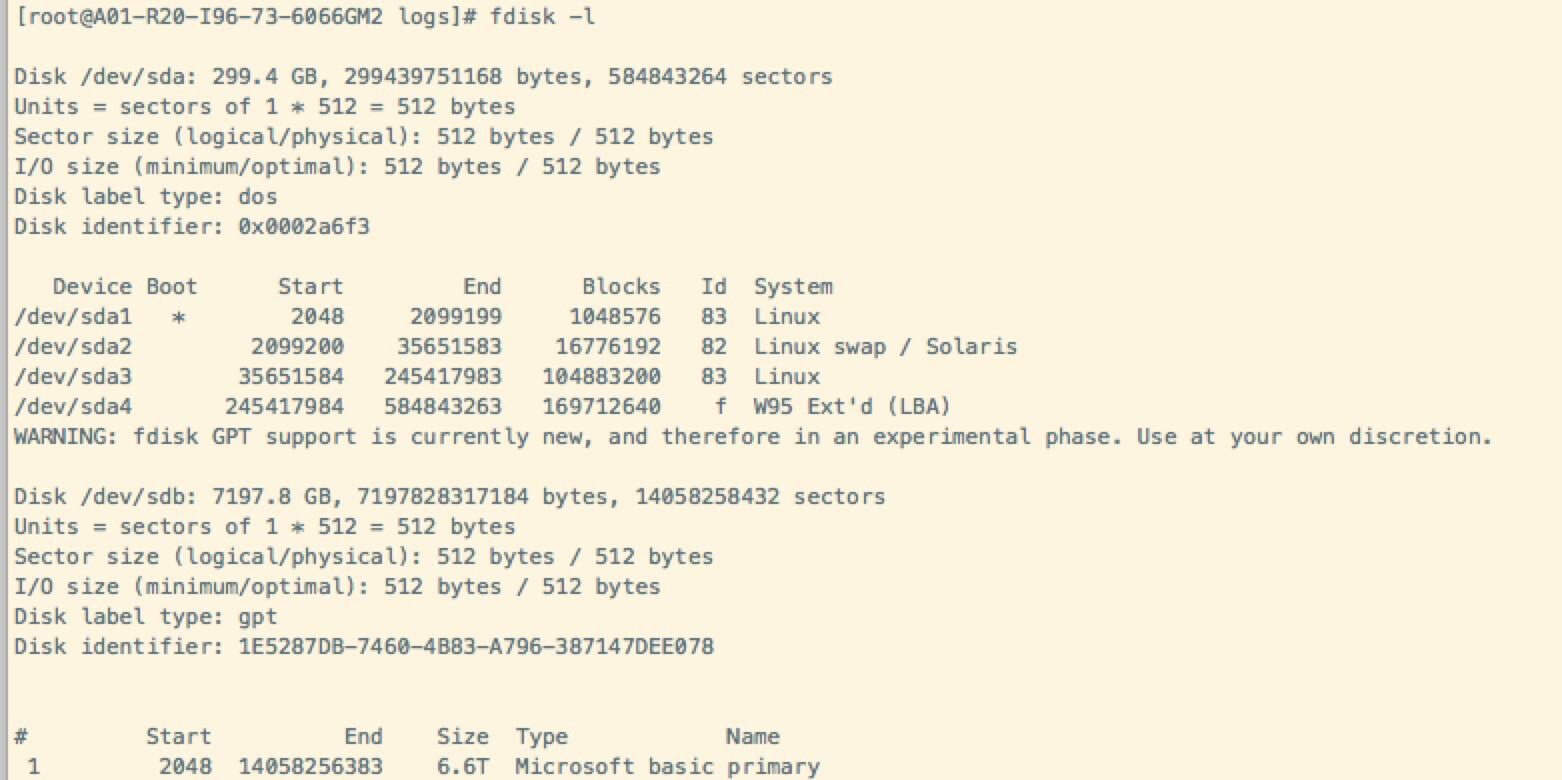
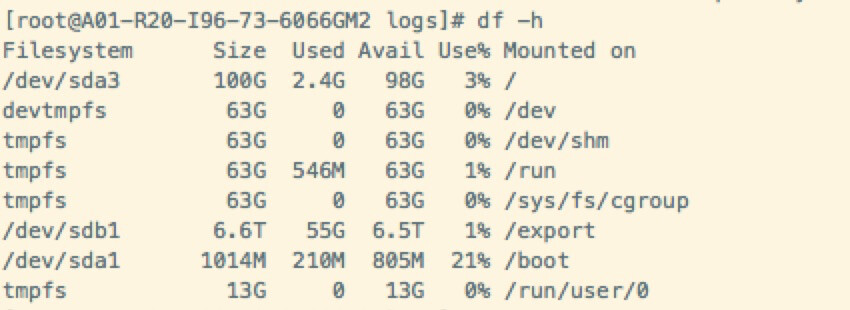
 我没法看出来是HDD还是SSD。
我没法看出来是HDD还是SSD。
lsblk -d看下。
你安装nebula在哪个硬盘上?/ 下面?
HDD
HDD关键词你可以在论坛搜索下。
好的,我们准备换成ssd的试一下
行。
一般常见的debug 前置 流程:
0. 检查硬件是否满足要求;检查配置是否正常
1.2 跑过的厂商已经相当多了,大规模场景也都在用。性能和使用问题通常原因是前置流程不满足。低级问题不太会。