- nebula 版本:v1.2.0
- nebula studio 版本:v1.2.4-beta
- 部署方式:Docker
- 硬件信息
- 磁盘:SSD
- CPU、内存信息:24核心48线程 384GB
- 出问题的 Space 的创建方式:
ID Name Partition number Replica Factor Charset Collate
157 ograph_v1 15 3 utf8 utf8_bin - 问题的具体描述:
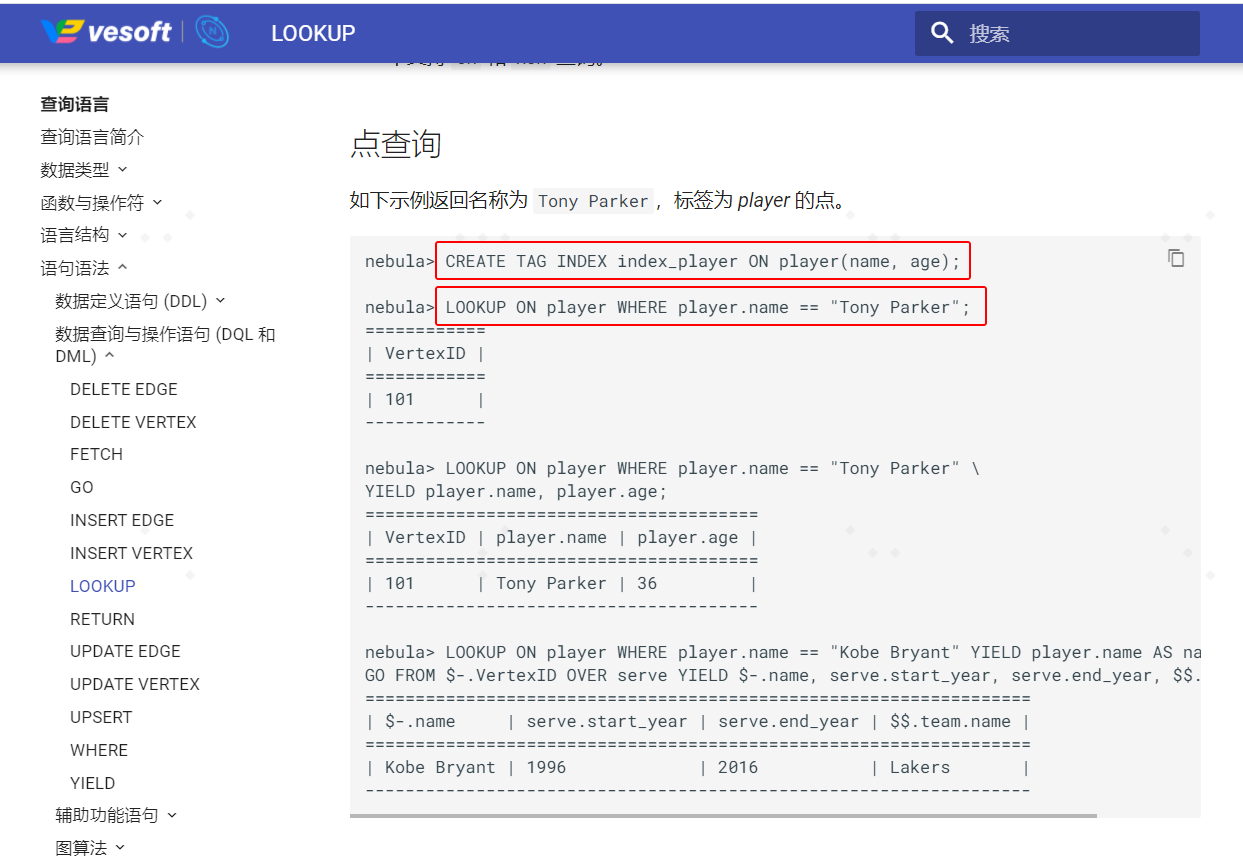
CREATE TAG INDEX idx_Thing_name_prior_source on Thing(Thing_name, Thing_prior);
其中Thing_name是string,Thing_prior是bool,rebuild 索引成功以后,
在studio的控制台运行:LOOKUP ON Thing WHERE Thing.Thing_name == "周杰伦" and Thing.Thing_prior == true;成功。
但是运行:LOOKUP ON Thing WHERE Thing.Thing_name == "周杰伦";报错.
报错信息为:
{ "code": -1, "data": null, "message": "Unknown error(411): " }
该问题必现,感觉索引要和条件完全匹配才行,不管是否为左匹配,多了和少了,LOOKUP都会报错。