- nebula 版本:2.0.0 rc
-
请问在用 k8s 部署 nebula database 的时候,为什么声明内网 IP 的时候是写死的呀,那如果主机崩溃就没办法调度了吧。
-
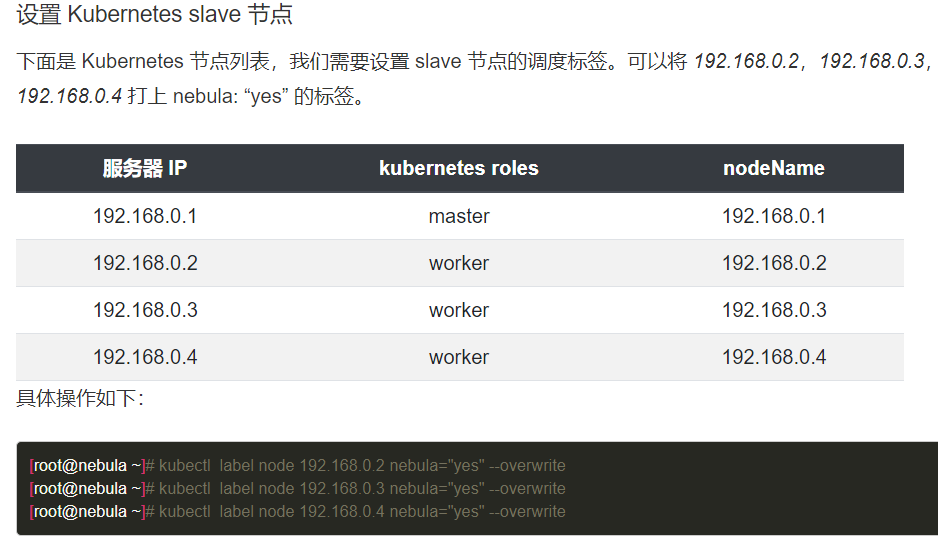
另外,用 “yes” 给打标签,似乎也和其他部署不太一样。想问一下为什么采用这样的方式呀?
请问在用 k8s 部署 nebula database 的时候,为什么声明内网 IP 的时候是写死的呀,那如果主机崩溃就没办法调度了吧。
另外,用 “yes” 给打标签,似乎也和其他部署不太一样。想问一下为什么采用这样的方式呀?
问题1:
只有metad地址是写死的,graphd跟storaged不需要这么配置,这么做是因为metad暂不支持动态扩缩容,一般建议3个服务副本保证高可用。如果担心主机崩溃无法调度,可以预留一个节点作为备份调度节点。
问题2:
nebula:yes是nodeSelector标签,这个配置会把graphd、storaged、metad调度到打了这个标签的节点上,当然你可以自定义,比如使用单独的标签来部署metad服务。
然后想再问一下,我们按照 Kubernetes 部署 Nebula 图数据库集群 这个部署的时候,会有一些问题,其中一个报错是:
Unable to attach or mount volumes: unmounted volumes=[config], unattached volumes=[timezone log default-token-2hrq2 config data]: timed out waiting for the condition
请问一下这个上面的 k8s 部署文件是最新的吗,因为我们看用 nebula-docker-compose/docker-compose.yaml at master · vesoft-inc/nebula-docker-compose · GitHub docker-compose 的文件跟它不太一样。
如果不是最新的话,请问你们这边现在有更新嘛~
你直接从github拉取下来就是最新的,报错得具体分析了,可以把错误详情贴出来看看
有一个报错是这样的
Unable to attach or mount volumes: unmounted volumes=[config], unattached volumes=[timezone log default-token-2hrq2 config data]: timed out waiting for the condition
跟你确认下k8s相关的信息:
Client Version: version.Info{Major:"1", Minor:"19", GitVersion:"v1.19.4+k3s1", GitCommit:"2532c10faad43e2b6e728fdcc01662dc13d37764", GitTreeState:"clean", BuildDate:"2020-11-18T22:11:18Z", GoVersion:"go1.15.2", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"19", GitVersion:"v1.19.4+k3s1", GitCommit:"2532c10faad43e2b6e728fdcc01662dc13d37764", GitTreeState:"clean", BuildDate:"2020-11-18T22:11:18Z", GoVersion:"go1.15.2", Compiler:"gc", Platform:"linux/amd64"}
我们是在部署 storaged 的时候产生的上面的错误,然后 pod 已经删掉了。我们之前是用的 longhorn
使用longhorn作为存储驱动的时候,storaged服务副本是全部启动失败还是个别的失败,metad服务有启动起来吗, 这个错误通常是挂载存储盘失败导致超时引起的。所以需要确认存储服务是否工作正常。
nebula graph 2.0 中所有的服务均支持了 DNS 域名解析,你可以将 1.0 的 k8s 部署文件按照最新的实现修改后提交到 nebula-graph 这个 repo 下面。
可以的@yee
我现在直接在尝试手动去按照这个 docker-compose.yaml nebula-docker-compose/docker-compose.yaml at master · vesoft-inc/nebula-docker-compose · GitHub 配置。请问一下 metad, storaged, graphd 是需要部署成三个服务,然后 metad0, meta1, meta2 是一个服务其中的三个 pod 吗?
另外,如果不使用 longhorn, 直接全部在一个数据盘上可以吗?
docker-compose会启动3个服务,metad0,metad1,metad2是metad的3个服务副本。logs跟data可以全部落在一个数据盘上,测试环境可以这么用,生产环境不建议。
你可以把这里的 metad0/metad1/metad2 理解为 statefulset 的三个副本,然后把这三个 statefulset 的域名和端口配置到 storaged 和 graphd 的 meta_server_addrs 的参数中.
嗯嗯,我现在 metad 和 storaged 的 container 都能跑,但是按照 docker-compose.yaml 配 graphd 的时候会显示:
主机上的错误日志为:
Failed to start web service: 99failed to bind to async server socket: 10.43.90.185:19669: Cannot assign requested address
这个看起来是 web service 的服务的端口 19669 被占用了,你不同的 metad 起在了同一个机器上?
嗯嗯,现在不同的 metad 是都在一个机器上。
但是我换了几个端口重新试,也都不行。
在同一台机器上,你就不能用同一个 statefulset 的不同副本了,估计要不同的 statefulset 并且分别配置各自的端口了。
那如果我现在把 metad1,meta2 换到不同的机器上,是可以按照之前的方法配置吗