- nebula 版本:v1
- 部署方式(分布式 / 单机 / Docker / DBaaS):分布式 docker
- 问题的具体描述
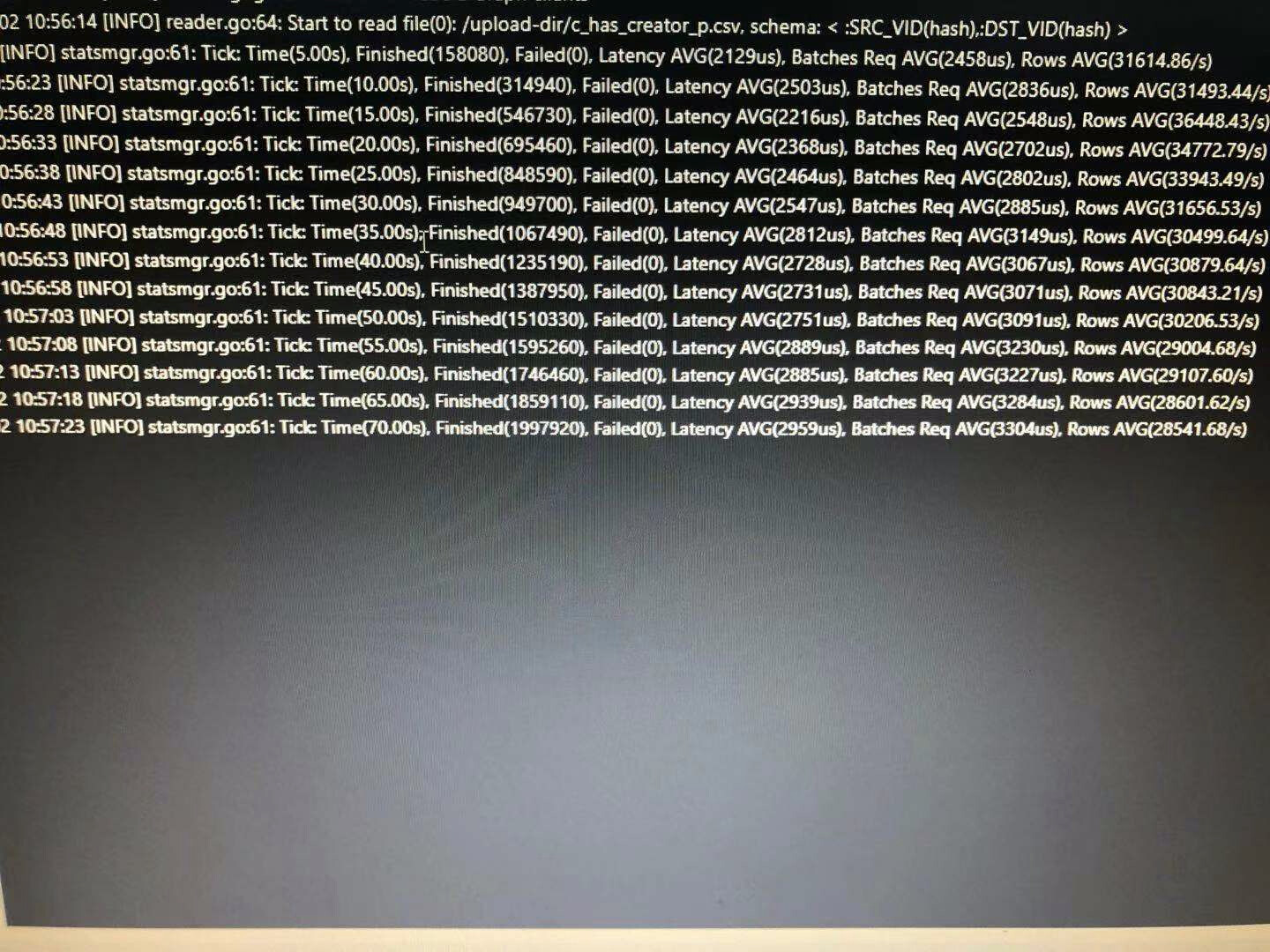
用docker的importer,导入一个edge文件时数据没有成功写入,console里start完就直接end了。但是studio里导入正常。(在此之前用importer成功导入了另一个edge文件)
用docker的importer,导入一个edge文件时数据没有成功写入,console里start完就直接end了。但是studio里导入正常。(在此之前用importer成功导入了另一个edge文件)
首先确认一下用 importer 的 docker 镜像导入的时候,有没有把本地的 csv 文件挂载到 importer 的容器内部?类似如下的操作:
$ docker run --rm -ti \
--network=host \
-v {your-config-file}:{your-config-file} \
-v {your-csv-data-dir}:{your-csv-data-dir} \
-w {your-config-file-path} \
vesoft/nebula-importer:v1 \
--config {your-config-file}
注意你的配置文件中的 csv 的路径,要在容器内部能够访问(对上),所以在 docker 容器启动的时候最好指定一下 work_dir。原则就是让容器内的路径跟 host 上的保持一致,基本就不会有问题。
我后来发现原因是:
配置文件里,我的edge没有属性就把props写成了"props":[]。改成props:[{}]后就没问题了。
我有一个问题:
作为worder node本地虽然有importer的镜像,但是docker container ls并未看到importer容器。
在部署有studio的master节点上有importer容器
nebula-importer 完成导入之后是直接退出的,所以导完之后不会再看到对应的容器。
studio 使用 importer 的方式不同,是把 importer 作为一个 web server 常驻进程来用。所以你能在容器中看到它,不过这块我们以后也打算改掉,也不希望这种 importer 的使用方式,想改成直接把 importer 作为一个 library 调用的方式,架构上更简洁。
所以importer以后会被弱化甚至不再单独被使用是么?
我在导入ldbc数据时没有用你们的benchmark工具而是自己做了预处理然后再一个个csv文件导入。
我用spark做完预处理后数据在hdfs所以一开始直接用的exchange,发现很容易出error或者timeout(我自己搭的hadoop集群也不够稳定数据处理能力上限大概是20g左右),以及如果有某一行不符合schema会导致整个job失败。(请问exchange是不存在部分数据导入成功的情况吗?)exchange是不是更适合用于hive/mysql之类的数据库中已经清洗干净的数据迁移至nebula这种场景?
转用importer之后发现不仅导入过程相对稳定,即使因为client的问题存在没有成功导入的数据也会存在fail.csv里只需要再重新导入。
nebula-importer 在设计之初就是希望提供一个单机的命令行工具。后来因为 studio 使用的开发语言的原因提供了 web 的模式,但是这块也只是简单的提供了一个 restful 接口,没做复杂实现。其实这也有点背离初衷。
exchange 和 importer 的设计目标不同,exchange 是一个面向分布式的离线导入工具,就是借助大数据的生态对接 nebula,你可以简单的类比其中的 ETL,当然不完全一样。这个对物联网的客户而言是必须的。其中导入失败的处理细节还要 @darionyaphet @nicole 来帮忙回答一下。
importer 面向的场景是单机上的 csv 文件,对于失败的数据会重定向到另外的 csv 文件中,方便下次直接从失败的数据启动。原因也主要是 importer 没有记录导入的状态,只好将数据落盘写出。
可以认为 importer 是一个单机程序 而 exchange 是一个分布式程序 这是两者根本区别