- nebula 版本:1.2
- Spark Reader 版本:1.1.0
- 部署方式(分布式 / 单机 / Docker / DBaaS):docker
- 问题的具体描述:
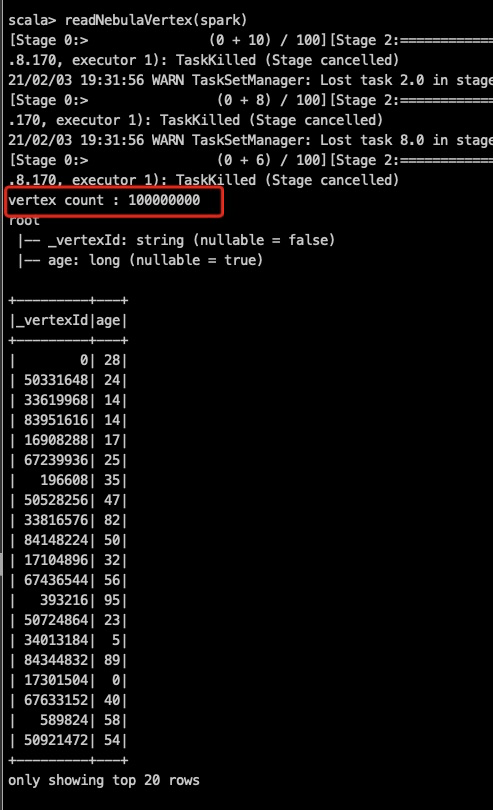
使用Spark reader进行读取图库,分别得到verticeRDD和edgeRDD,然后使用GraphX里的图构造方法构造成图。通过日志发现两次形成图的点和边的个数不一致,第一次vertice和edge分别是1.9亿、0.69亿,第二次vertice和edge的个数为1.4亿、0.77亿。而图库中vertice和edge的个数为3.2亿、1.3亿。
请检查一下 2次导入的点、边 是否在同一个space 下 ,点和边是否有重复
两次都是在同一个space下的,因为使用spark-submit提交的是同一个jar包,点和边应该没有重复
你确认下使用的Nebula版本,在1.2之前由于读取不同的part数据时拿不到leader信息是会有这个问题的。
是的,nebula版本就是1.2
好的,我们这边试试复现一下
好的。麻烦啦
这个版本包括1.2嘛?
你好,这边需要知道几项信息:
- 你读取的space副本数
- 通过show configs查看enable_multi_versions这个配置是否开启
ps:不包括1.2版本的,且只会在多副本情况下出现数据读取不全。

mark
你好,我这个时docker swarm部署的
可以直接 docker ps, 贴一下结果信息吧

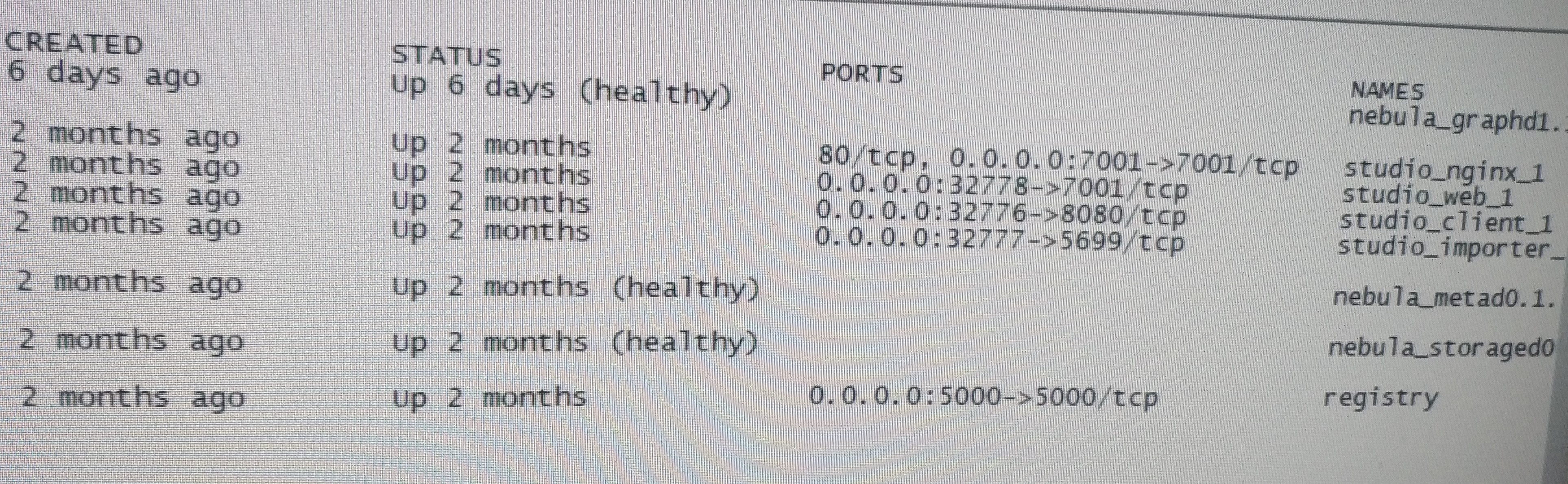
看你的 nebula 的镜像的 tag 都是打的 v1.1.0,这不是 1.2.0 的版本呀,你确认更新一下,再验证试试
很明确,你用的1.1.0的版本。1.2之前存在这个问题的。
镜像已经换为了1.2,只是打的tag还是1.1.0 
如果服务镜像是 1.2 并重启服务后,spark reader 依然会出现最早的问题吗?