环境信息
nebula 版本:2.0.0-rc1
部署方式:3 台物理机(24 cores, 47G mem, 534G 可用磁盘)集群部署(metad*3, graphd*3, storaged*3)
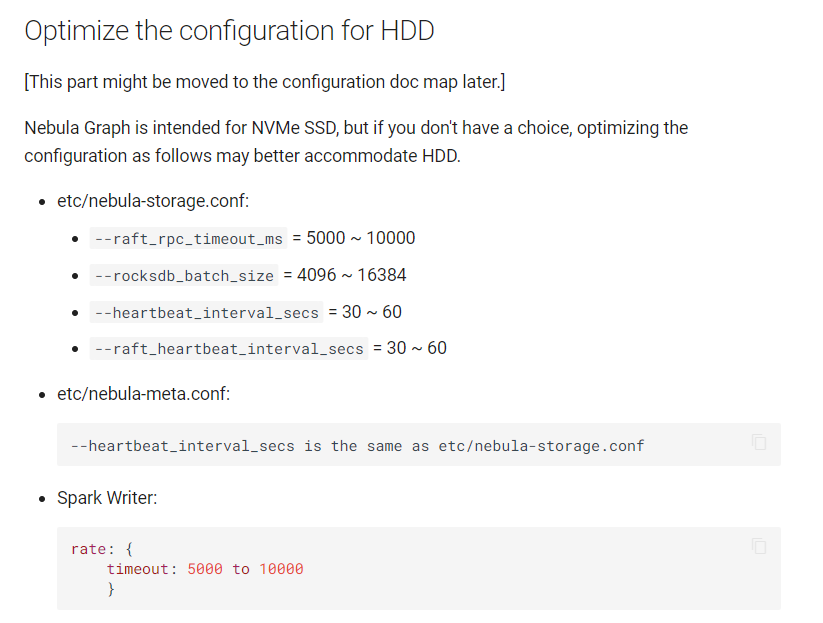
根据文档,使用 HDD 存储数据时的配置优化:
etc/nebula-storage.conf:
–raft_rpc_timeout_ms = 7000
–rocksdb_batch_size = 4096
–heartbeat_interval_secs = 30
–raft_heartbeat_interval_secs = 30
etc/nebula-meta.conf:
–heartbeat_interval_secs = 30
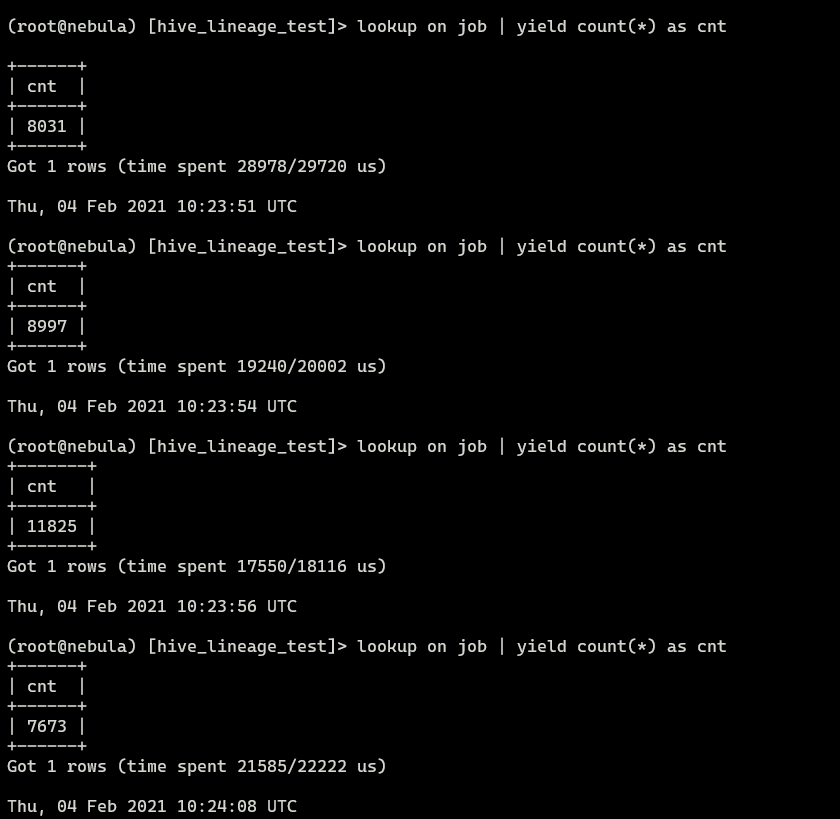
问题1:同一条语句执行多次,返回不同结果 ,集群似乎不稳定;
举例:连续执行 3 次同样的查询语句,第 3 次才出现正确的查询结果;
问题2:leader 分布不平衡,集群没有进行自动平衡 ;如下图,过了一段时间,集群 leader 分布没有发生过变化;
补充一个例子:count(*) 每次查询返回不一样的数,有点可怕
1 个赞
是的,可以通过 balance leader 来触发 leader 平衡,但集群是否能够做到自动地平衡?
@steam 这里记一下 count(*) 每次查询返回不一样的数@critical27 这里的leader 能否做到自动平衡吗?
yee
2021 年2 月 4 日 13:22
6
先说自动做 BALANCE 的问题,这个 nebula 在设计之初就不打算自动帮用户做 leader balance。缘由之一是 leader 的迁移是会影响用户的请求,更期望用户能在并发访问量较低的时段自己控制。
上面 fetch 语句报错,是否是因为 leader 选举还未就绪,也即集群还会完全 ready 就开始访问导致,在成功访问之后的请求是否还会经常出现上述现象?
再说最后的 LOOKUP,看你的使用是直接 LOOKUP 在一个 tag 上然后做 COUNT,看起来你是想针对该 TAG 做全量扫描。首先 LOOKUP 不是用来做这个事情,如果你想看 space 中点边数量和 TAG 上点的数量,在 nebula 2.0 中我们引入了 SHOW STATS 语句通过 JOB 的方式来完成,文档见这里 。
至于 LOOKUP 为什么会出现这种情况,麻烦 @bright-starry-sky 来给你详细的解答,针对这种没有条件的 LOOKUP 在语义层面就直接报错或许更好。
1 个赞
可能是个别part选举leader的问题,至于为什么要用LOOKUP查询tag,设计思想可以请教一下 @panda-sheep
balance leader 的问题,如果没有自动平衡的机制,那是否有出现不平衡时的监控告警机制?
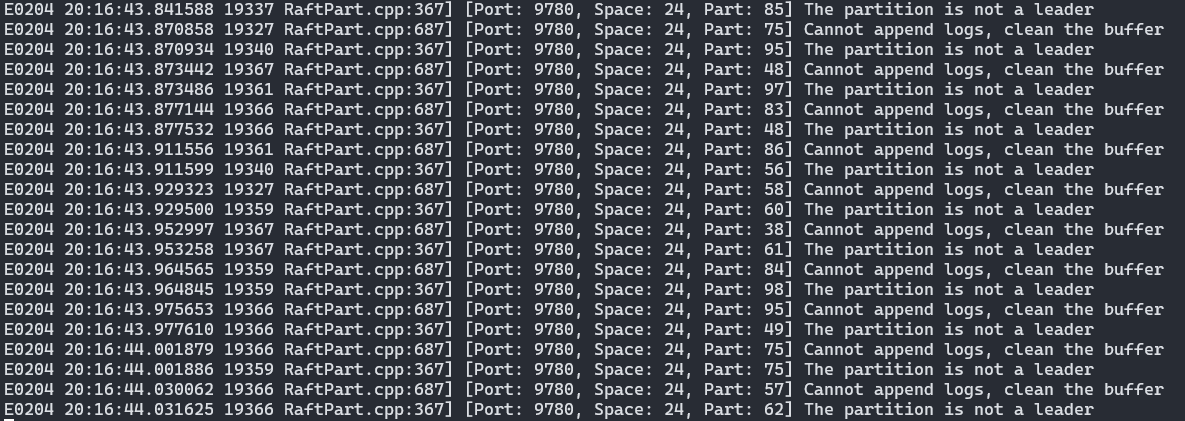
fetch 语句的错误,有可能是大佬说的 leader 选举未就绪 ,storaged 经常会出现下图的错误日志,是 raft leader 发生重选后没有及时更新到 metad 造成的吗?请问哪些相关参数可以调整?
尝试过 SHOW STATS,但是 submit 一次,要跑很久,通过 LOOKUP 看到的 Vertex 数约为 10w+,但 SUBMIT JOB STATS 跑了 12 个小时+;
关于 partition leader 选举的稳定性及其与 metad 的元数据同步,还请大佬指教如何调整集群参数,来保证集群的稳定
在批量导入数据时,出现这种 Cannot append logs, clean the buffer 的错误,是不是会造成数据丢失?没有重试去找 leader 再写入?
HDD现在比较容易出现你说的这种情况,数据丢失是一般来说是插入成功但数据没了。重试暂时先不做,内部测试效果很差。
啊这,还请大佬测试过后,贴上 2.0 针对 HDD 的参数优化配置,期待正式 release
1 个赞
两个问题: