- nebula 版本:v1
- 部署方式(分布式 / 单机 / Docker / DBaaS):分布式,docker swarm
- 问题的具体描述:
三个节点分别在三台物理机上,一共8个service。
e-ds-m3 (master):metad, storaged
bigdata12: metad,storaged,graphd
bigdata: metad,storaged,graphd
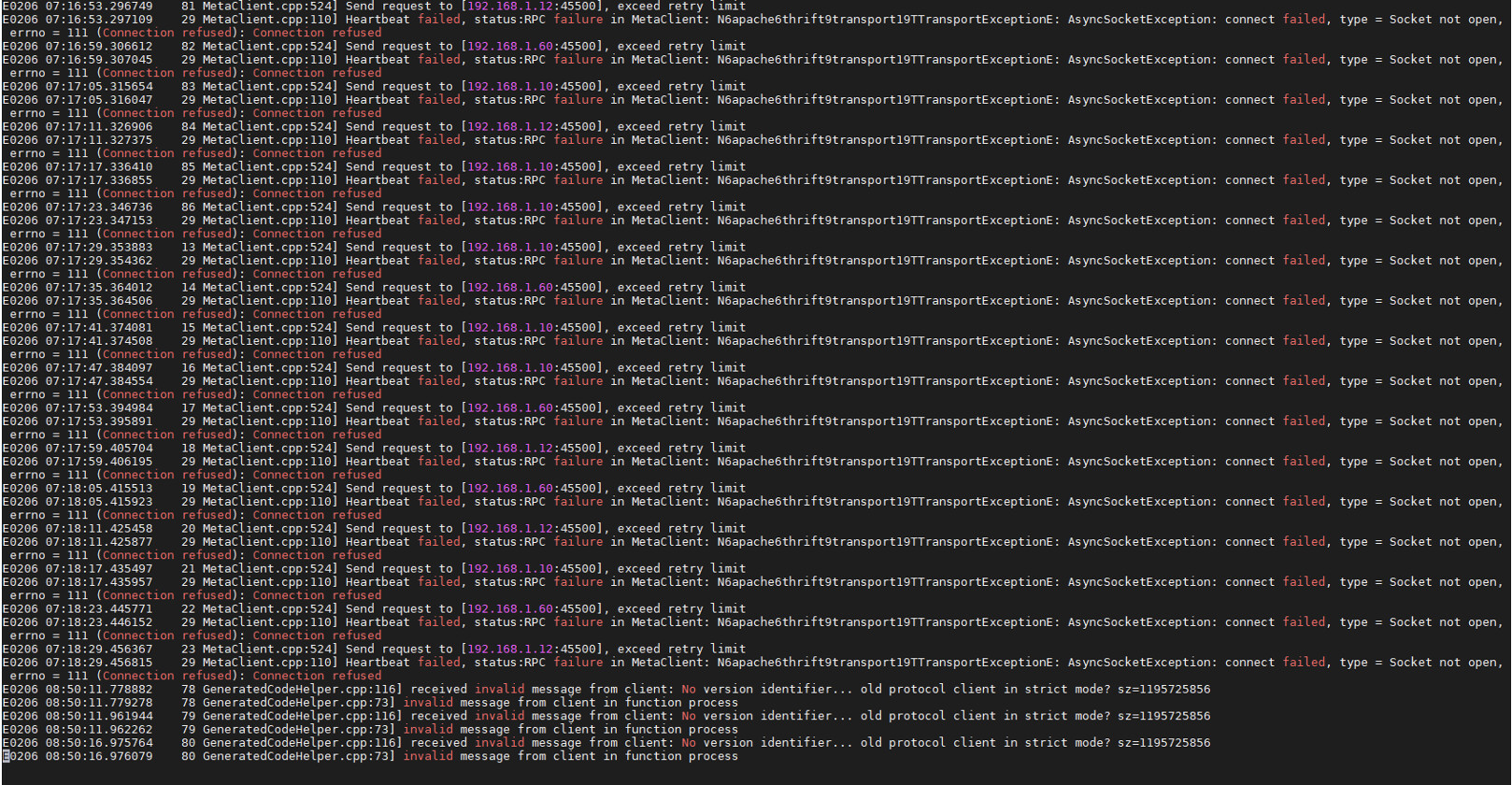
在一次物理机重启后多个service挂掉状态变为0/1。通过restart container和用docker stack重新创建service的方式恢复了所有服务。
此时查看host状态:
从上至下分别为e-ds-m3,bigdata12,bigdata三台物理机。
发现第一个节点状态为online但是leader count为0,执行balance leader等待了数十分钟再次查询依然是0。
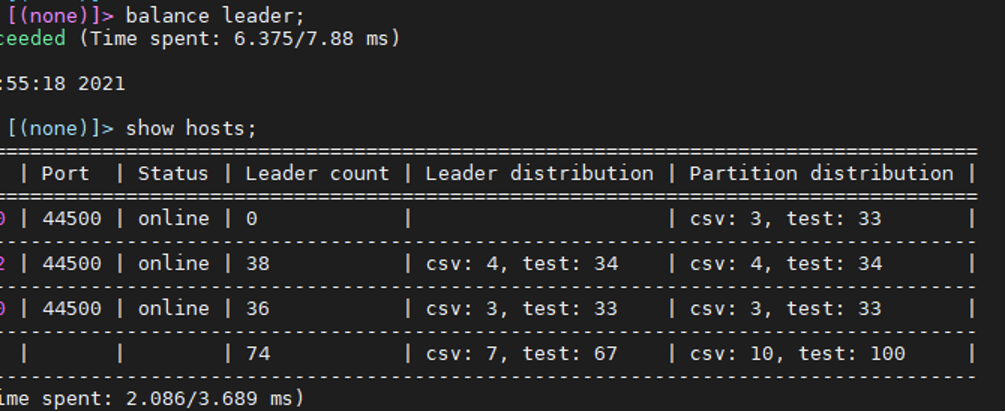
第一个节点(e-ds-m3)的meta和storage服务之前挂掉了,storage的容器还在直接restart容器恢复了service, 但是nebula-metad容器消失了,所以无法用restart container的方式重启容器,我就把挂掉的服务删除了,用docker stack deploy 创建/更新 了该节点上的meta服务。
进该节点metad容器查看log:

随后又看了其他两台节点上的meta容器里的log:


各节点上storage容器内的log: