提问参考模版:
-
nebula 版本:1.2.0
-
Exchange 版本:v1.1.0
-
部署方式(分布式 / 单机 / Docker / DBaaS):分布式
-
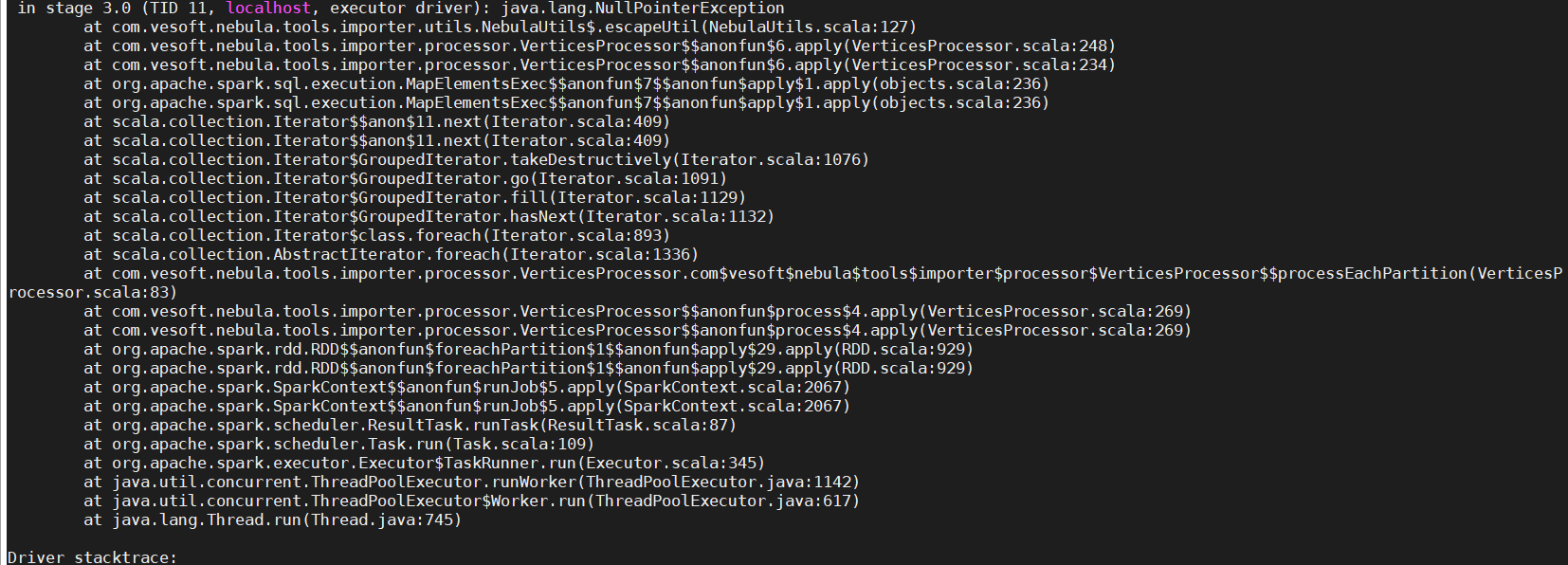
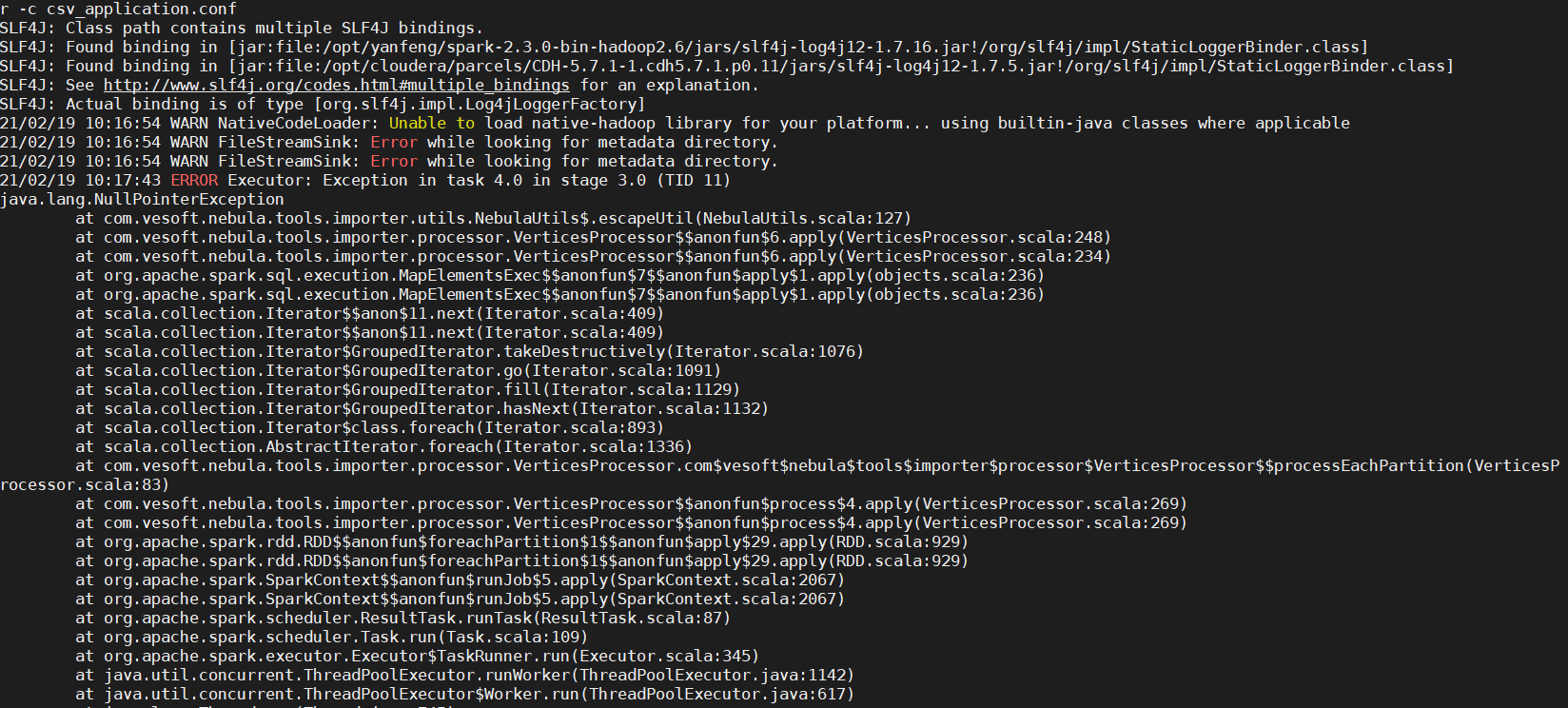
通过exchange导入的时候出现报错
spark版本 2.3
conf配置
{
# Spark relation config
spark: {
app: {
name: Spark Writer
}
driver: {
cores: 1
maxResultSize: 1G
}
cores {
max: 16
}
}
# Nebula Graph relation config
nebula: {
address:{
graph:["127.0.0.1:3699"]
meta:["127.0.0.1:45500"]
}
user: root
pswd: root
space: test
connection {
timeout: 3000
retry: 3
}
execution {
retry: 3
}
error: {
max: 32
output: /tmp/errors
}
rate: {
limit: 1024
timeout: 1000
}
}
# Processing tags
tags: [
{
name: family
type: {
source: csv
sink: client
}
path: "hdfs://ip:port/user/graph/data/graph_test.csv"
fields: [_c1,_c2]
nebula.fields: [familyId,name]
vertex: _c1
separator: ","
header: false
batch: 256
partition: 10
isImplicit: true
}
{
name: position
type: {
source: csv
sink: client
}
path: "hdfs://ip:port/user/graph/data/graph_test.csv"
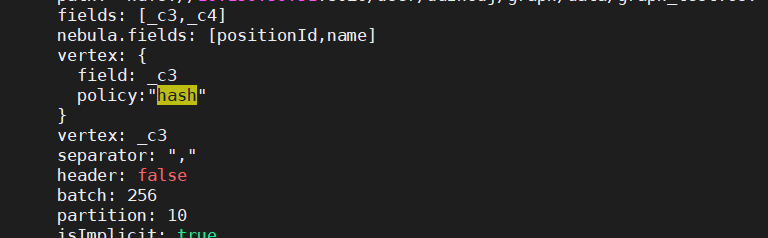
fields: [_c3,_c4]
nebula.fields: [positionId,name]
vertex: _c3
separator: ","
header: false
batch: 256
partition: 10
isImplicit: true
}
{
name: device
type: {
source: csv
sink: client
}
path: "hdfs://ip:port/user/graph/data/graph_test.csv"
fields: [_c5,_c6]
nebula.fields: [mac,name]
vertex: _c5
separator: ","
header: false
batch: 256
partition: 10
isImplicit: true
}
]
# Processing edges
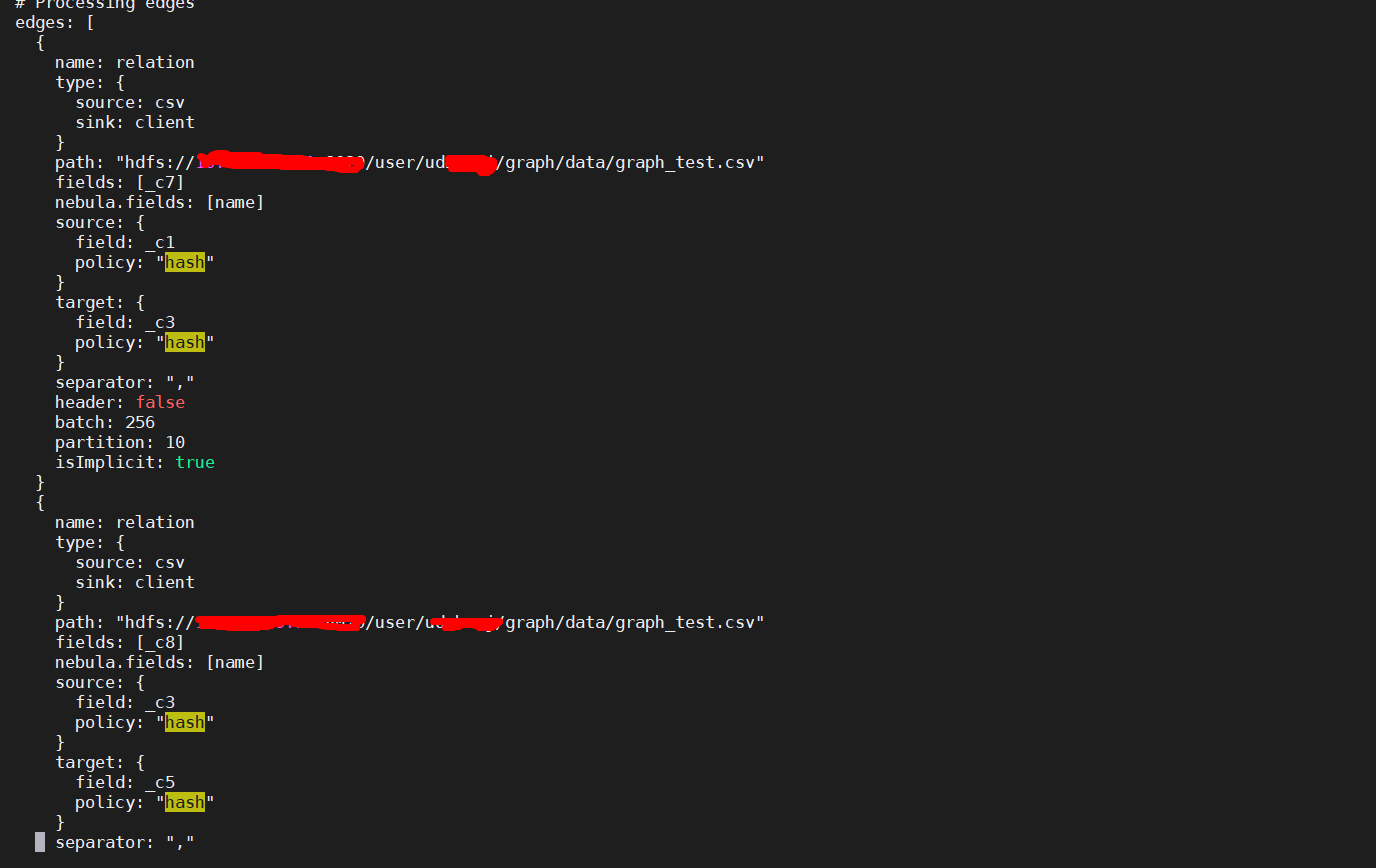
edges: [
{
name: relation
type: {
source: csv
sink: client
}
path: "hdfs://ip:port/user/graph/data/graph_test.csv"
fields: [_c7]
nebula.fields: [name]
source: _c1
target: _c3
separator: ","
header: false
batch: 256
partition: 10
isImplicit: true
}
{
name: relation
type: {
source: csv
sink: client
}
path: "hdfs://ip:port/user/graph/data/graph_test.csv"
fields: [_c8]
nebula.fields: [name]
source: _c3
target: _c5
separator: ","
header: false
batch: 256
partition: 10
isImplicit: true
}
]
}
csv数据格式
13,353343,我家,556,卧室,22,空调1,存在,放置
14,755444,我家,33432,客厅,11,空调2,存在,放置