呃,抱歉我没有注意到版本,2.0 有没有一个预估的写入性能基准?
另外我去做go-importer测试的一个原因是,我自己用JavaClient去做insert的性能也并不高,同样的数据大约只有1-2w ops/sec(远低于goimporter),方式大约是单线程batch写入,每次1000条,这个有点低于我的预期,但不知道该如何优化
importer也有batchSize参数, 默认是128, 你要不调大点试试?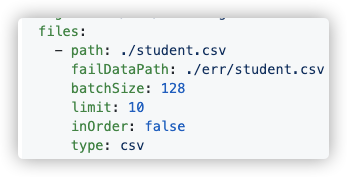
多谢回复,由于业务限制,我其实只能通过JavaClient去做写入,无论是goimporter或者exchange都只能是提供一个nebula storage的写入性能基准
但基于你上面的回复,我是否可以通过以下途径来优化JavaClient的写入性能:
- 增加batchSize
- 多线程执行,增加concurrency
- 写入时自动调整rocksdb参数(例如auto compaction),防止rocksdb成为瓶颈
另外我理解虽然我可以增加concurrency,但是这个concurrency要适配graphd的threads数量,而这个值在默认情况下是等于CPU核数的
不知道我的理解对不对?
min.wu
12
show hosts
show partitions
手册有写
我只有一个storage,所以partition全部是在同一台机器上的…
min.wu
14
那。。。。benchmark 我记得是 3-5台 server吧。。。
你把memfile调大点,就100万数据。
好的,多谢,我用OwnThink的那个数据集和go-importer做了个测试,一开始的写入性能大概在17w ops/sec(但是会逐渐下降,最终大概在9-10w ops/sec),理论上如果采用多storage,写入的压力会被平均分配到多个节点,性能确实应该会有成倍的增长,这么算起来如果我用3台storage就能达到benchmark中的性能
exchange 是一个基于Spark的分布式程序 如果数据量不是特别大 importer 更方便




