场景如下:
有一个节点类型T,它有一个属性p是String类型;
p的值为"a,b,c,d,e";
我对p的过滤逻辑为:where size([e IN split(p, ‘,’) where e > ‘b’ | e]) > 0;
想问一下,这个处理逻辑会下推到storaged处理么?还是会在graphd处理?
explain能看出执行计划哪些在storaged执行,哪些在graphd执行吗?
场景如下:
有一个节点类型T,它有一个属性p是String类型;
p的值为"a,b,c,d,e";
我对p的过滤逻辑为:where size([e IN split(p, ‘,’) where e > ‘b’ | e]) > 0;
想问一下,这个处理逻辑会下推到storaged处理么?还是会在graphd处理?
explain能看出执行计划哪些在storaged执行,哪些在graphd执行吗?
如何 p 是起点 tag 上的属性,虽然 where 的过滤条件比较复杂,但是只是针对该属性的操作,是应该可以下推的。
现在有没有支持下推需要 @jievince 来确认一下,如果没有看看实现的复杂度。
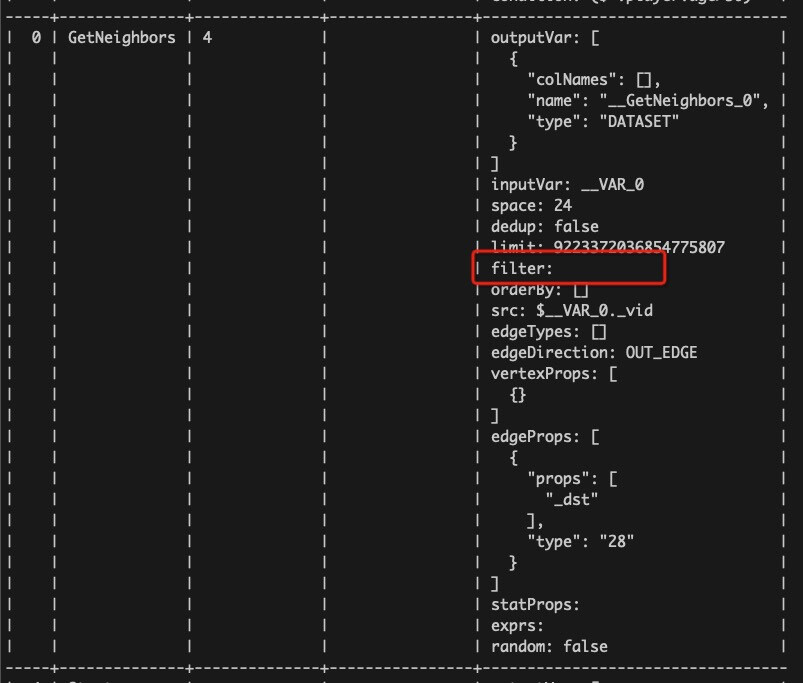
explain 可以打印执行计划的所有的结点,其中跟 storage 打交道的结点有 GetVertices 和 GetNeighbors 等结点,在这些结点上有 filter 字段来表示下推到 storage 的表达式。
profile了这个语句,对起点出发的边上属性进行带函数的过滤,逻辑也可以下推吧,但是profile的结果如下:
按照刚才你说的,GetNeighbors的filter是没有的,执行计划有专门一个filter阶段,这个是在graphd处理的吗?
你看一下 nebula-graphd.conf 中的 enable_optimizer=false 的 flag 有没有打开,现在默认优化器是关闭的,需要打开优化器才能做过滤下推。
修改配置后,需要重新启动 nebula-graphd 进程。
在实际生产环境这个开关打开与否需要有什么考虑吗?
在 GA 版本中我们考虑将其默认值改成 true,目前的优化器主要实现 RBO 的功能
[e IN split(p, ‘,’) where e > ‘b’ | e]这种表达式目前没有做下推, 但应该可以做。
可以的话建议排上日程吧,逻辑上这种过滤也适合下推,此外我们也确实有这方面的需求 
表达式下推目前在开发中哈,有新的进展我会更新帖子的哈。
从我个人角度看,点的下推意义不大,实际上也没做。无论是fetch还是go,只影响storage返回到graph的数据量。
我理解这需要看过滤率吧,如果过滤后的点或者边只有storaged获取的20%,那么相当于把80%无效的数据传到了graph,这部分传输开销其实是没有意义的
来更新下帖子,我们在这个 pr:https://github.com/vesoft-inc/nebula-graph/pull/810 里实现了 [e IN split(p, ‘,’) where e > ‘b’ | e]这种表达式的下推