- nebula 版本:v1
- 部署方式(分布式 / 单机 / Docker / DBaaS):分布式,docker swarm
- 硬件信息
- 磁盘:1T
- CPU、内存信息 40 core, 64G mem
- 问题的具体描述
三个节点,每个节点上的数据大概是25个g左右。需要下线一个节点,缩容。
执行balance data remove后18分钟查看进度发现达到92%,过了一个多小时后再查看发现进度卡在了92%,也没有fail,请问这个怎么解决?
三个节点,每个节点上的数据大概是25个g左右。需要下线一个节点,缩容。
执行balance data remove后18分钟查看进度发现达到92%,过了一个多小时后再查看发现进度卡在了92%,也没有fail,请问这个怎么解决?
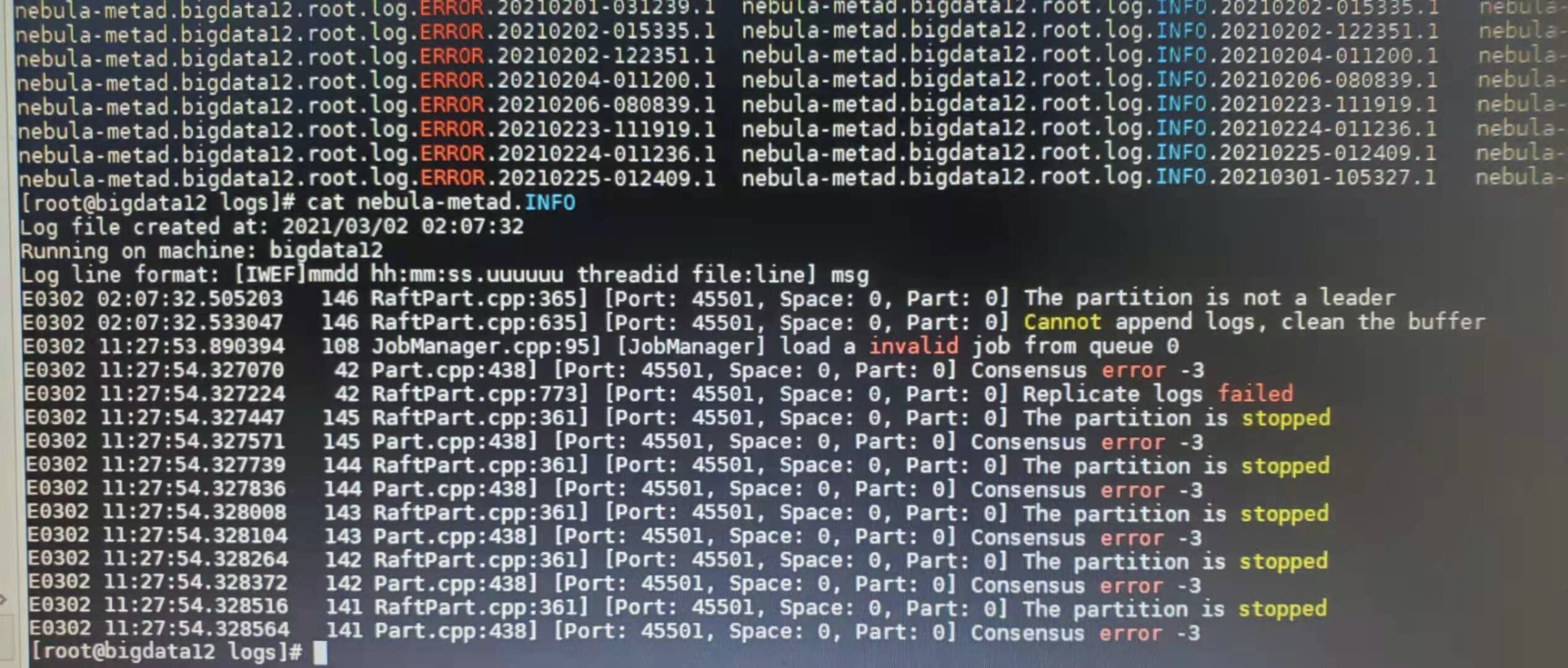
能贴一下 meta 的 日志吗? meta.INFO
由于状态显示的是in progress,根据文档里的描述我执行balance data stop应该也没用。
由于每个 balance 计划对应若干个 balance task,BALANCE DATA STOP 不会停止已经开始执行的 balance task,只会取消后续的 task。
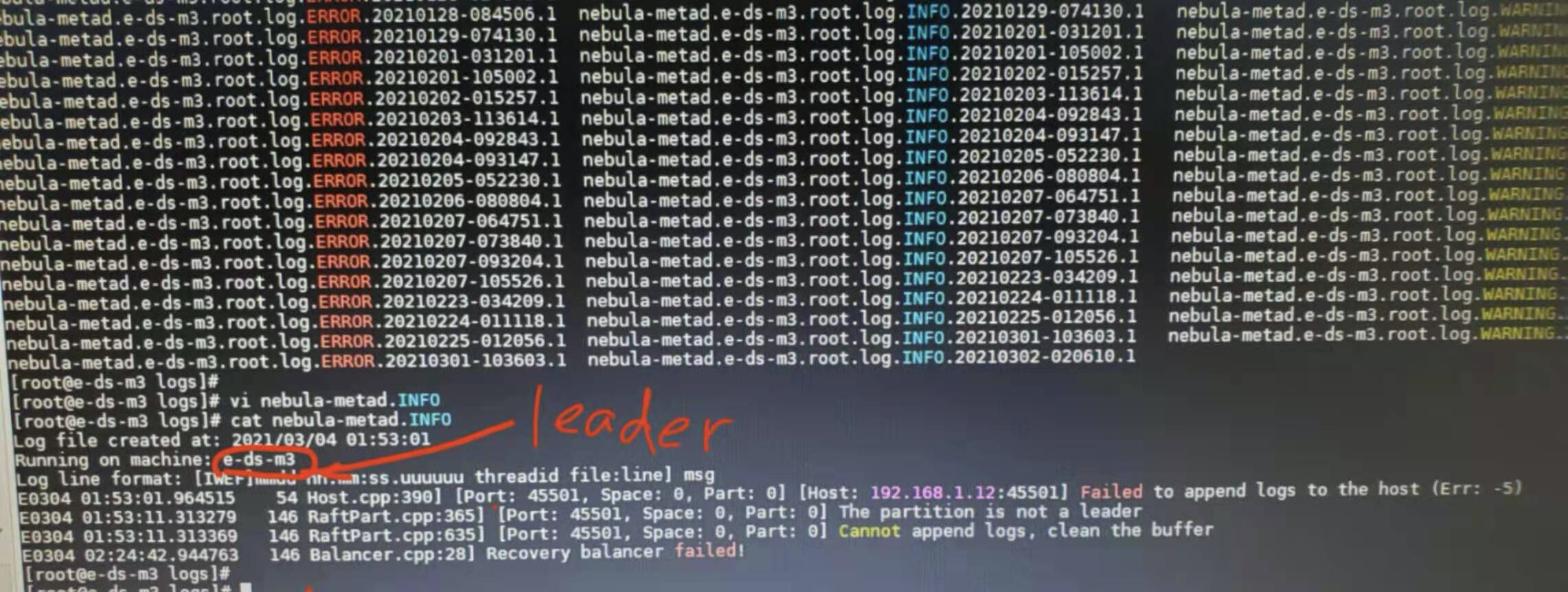
需要贴meta leader的日志 三个meta里面有一个INFO日志会比其他的大很多 那个是leader
这是leader node上的日志
[Host:192.168.1.12:45501] Failed to append logs to the host…
192.168.1.12这个IP是要下线的那个节点
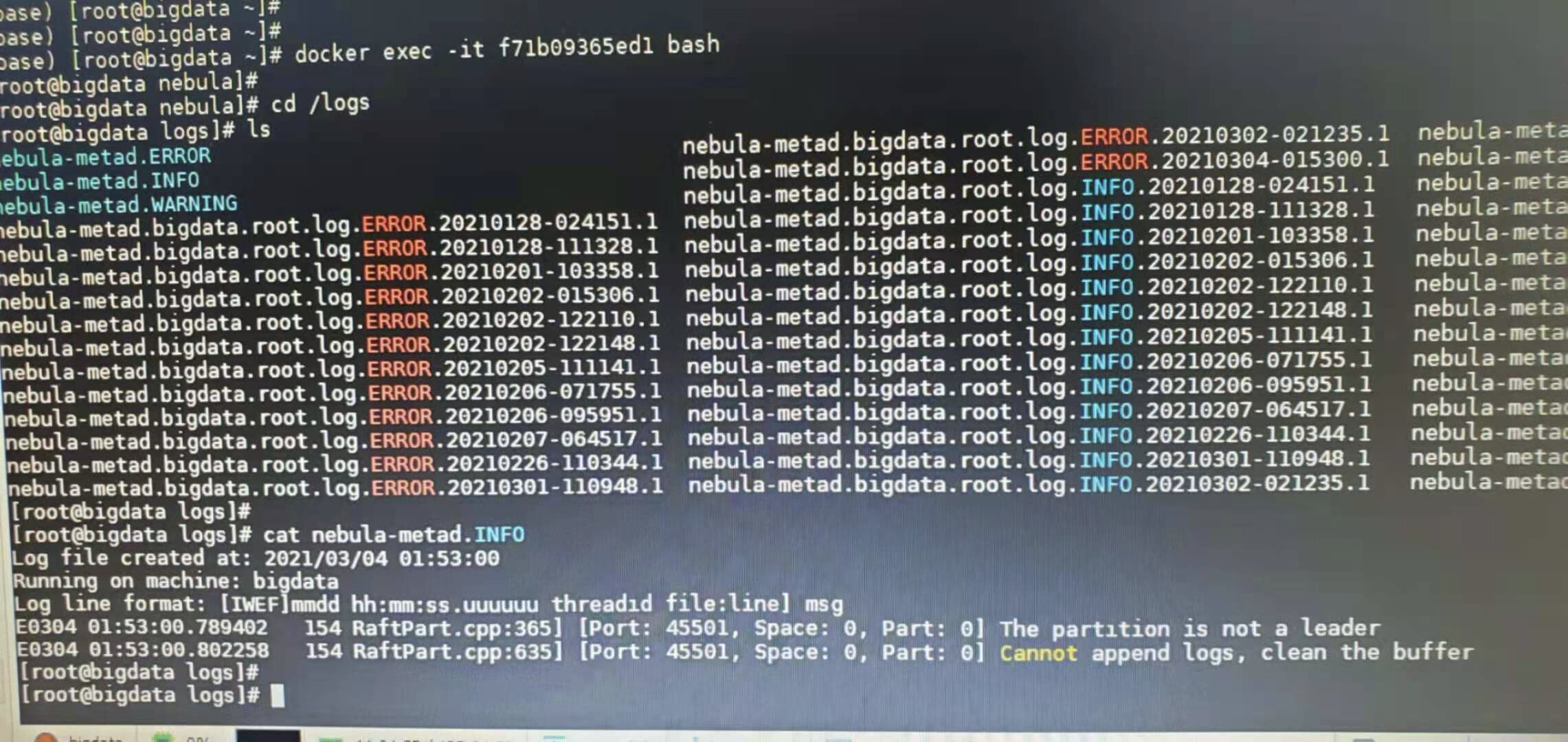
这是另一个worker node上的日志
minloglevel日志等级是多少?怎么看着什么日志都没有
没有改过应该是默认值,貌似是0?
leader的日志里第一行中有提到failed to append logs to the host
show configs能看,还有可能是日志太多 被切分了,需要看对应时间的那个
minloglevel=2.
应该不是日志太多被切分,今天只有一个日志0304对应的内容和上图里的一摸一样。
leader的日志里第一行中有提到failed to append logs to the host
改成0然后重启再开始一次 需要看日志
重启再开始一次
请问这个指的是重启要下线的那个节点,在开始一次balance data remove这个任务吗?
重启后就从in progress变成了fail,然后再执行一次balance data就成功了。
不过还是不知道是什么原因导致的 一路正常运行到了最后三个就卡住了
@critical27 @liuyu85cn
请问invalid是个什么状态?我可能有一系列不当操作导致在扩容的时候卡在了invalid和in grogress。
在成功缩容后,再次扩容(上线的节点=之前被下线的节点)。出现了invalid,并且卡在in progress。
第一次:查看日志后发现是already exist导致了invalid
处理方式:把上线的节点的volume直接删了重新deploy
尝试了重启在开始一次,依然是同样的问题。
第二次:查看日志发现是超不到对应的partition wal导致了invalid。查看storage/目录下的文件,能找到报错的part
求助
贴下日志吧 我现在说不好。我猜可能是“在成功缩容后,再次扩容”之后生成的plan有问题或者执行了一个错误的plan。
应该有一个 Task invalid, status 日志吧