环境信息
- nebula 版本:2.0.0-rc1
- nebula-exchange:2.0 编译 master 分支
- nebula-java:2.0 编译 v2.0.0-rc 分支
- 部署方式(分布式 / 单机 / Docker / DBaaS):物理集群部署(1*metad, 1*graphd, 3*storaged)
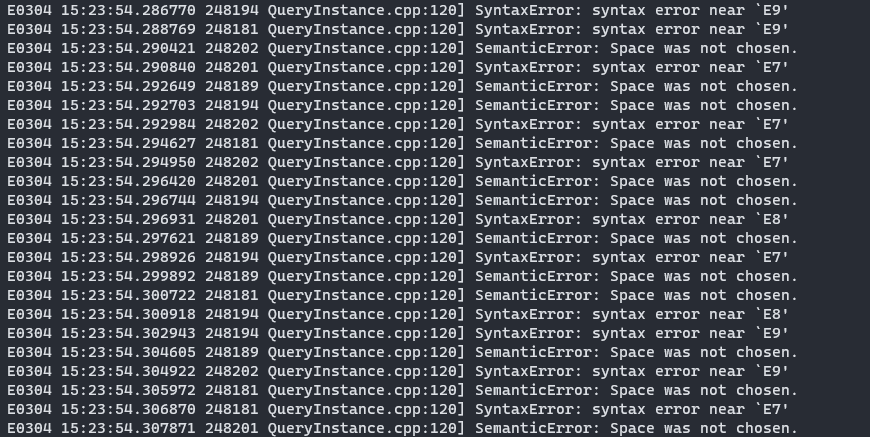
问题的具体描述:执行 Exchange 2.0 批量导入 Hive 数据,每次导入时,graphd 刷很多错误日志,类似下图
同时,发现 Exchange 配置文件中指向的错误日志 HDFS 路径下,产生了很多 reload.* 文件,文件内容有很多与该 space 无关的 insert 语句
@nicole
Exchange 配置文件
{
# Spark relation config
spark: {
app: {
name: Spark Writer
}
driver: {
cores: 2
maxResultSize: 2G
}
cores {
max: 16
}
}
# Nebula Graph relation config
nebula: {
address:{
graph: {{graph_addr}}
meta: {{meta_addr}}
}
user: root
pswd: nebula
space: {{space}}
connection {
timeout: 10000
retry: 3
}
execution {
retry: 3
}
error: {
max: 32
output: /tmp/nebula/errors
}
rate: {
limit: 1024
timeout: 5000
}
}
# Processing tags
tags: [
{
name: job
type: {
source: hive
sink: client
}
exec: "select split(job.`oid`, '\\.')[0] AS `job_id`, job.`oid` as `task_id`, job.`exec_time` as `exec_time`, cast(resource.`cputime` as decimal(30,4)) as `cputime`, cast(resource.`memory` as decimal(30,4)) as `memory` from (select `oid`, `exec_time` from table_job where dt = {{dt}} and exec_time >= {{week_ago}}) as job left join (select `oid`, sum(querycputime) as `cputime`, sum(querymemory) as `memory` from table_resource where dt= {{dt}} and oid!='null' group by oid) as resource on job.oid=resource.oid"
fields: [job_id, task_id, exec_time, cputime, memory]
nebula.fields: [job_id, task_id, exec_time, cpu_time, memory]
vertex: task_id
batch: 1024
partition: 32
isImplicit: true
}
]
}
上述配置文件对地址和字段做了一些脱敏处理
Nebula Graph tag 如下

同时,Exchange 中配置的 Hive 语句无法正常执行 split 函数,比如
示例数据:
oid
--------
aaa.bb
hql 语句:
select split(job.`oid`, '\\.')[0] AS `job_id`, job.`oid` as `task_id` from ...
job_id 无法成功获取,在 nebula 中为 __EMPTY__,但在 Hive 中直接执行 hql 是可以获得
job_id, task_id
---------------------
aaa, aaa.bb
syntax error near 'E9’这一类数据时tag中的属性值么
可以贴几条reload文件中的insert语句
E9 不是 tag 中的属性,像是 nebula 的错误码?
reload 文件中为批量 insert 语句,内容敏感打码了,如:
也有该 space 的 tag,如上述的 job,其中 job_id 为空,但直接执行 Hive 语句能够查出
table这个tag是哪里配的,exchange的配置文件中只配了job这一个id啊
job_id的值是spark从hive中读出的,读到的应该就是空字符串
ps 可以确认下配置文件中填写的space是不是要进行导入的那个图
1 个赞