pongw
1
- nebula 版本: nebula-graph-2.0.0-rc1
- 部署方式 分布式 / 单机 / Docker / DBaaS):分布式
- 硬件信息
- 问题的具体描述
- 相关的 meta / storage / graph info 日志信息
你好, 我现在面临的以下场景:
如图,我有一个person点, 他与另外三类点有相同类型的边(private_info)
我使用go from person查询时, 如果我只想要终点为phone类型的数据, 有什么方法可以满足我的需求吗

match (s:person) -[:private_info]->(e:phone)
return e.number
pongw
3
match (s:person) -[:private_info]->(e:phone)
where s.name == “test”
return e.number
若我像这样使用, 增加了where, 性能如何?
相对于go from 操作的性能是同一量级还是有所差距?
kyle
5
过滤终点 tag 类型的话用 go 和 match 都可以,具体如下:
go from "person_vid" over private_info yield $$.phone.number
match (v:person)-[:private_info]->(m:phone) where id(v)=="person_vid" return m.number
match 和 go 语句 执行计划不同,以下是我在小数据集上的测试结果,但测试数据集较大时 go 语句性能会好很多。
(czp@nebula) [nba]> match (v:player)-[:like]->(m:player) where id(v)=="Tim Duncan" return distinct m.name
+-----------------+
| m.name |
+-----------------+
| "Manu Ginobili" |
+-----------------+
| "Tony Parker" |
+-----------------+
Got 2 rows (time spent 6813/7739 us)
(czp@nebula) [nba]> go from "Tim Duncan" over like yield $$.player.name
+-----------------+
| $$.player.name |
+-----------------+
| "Manu Ginobili" |
+-----------------+
| "Tony Parker" |
+-----------------+
Got 2 rows (time spent 7725/8356 us)
计划和性能有明显差别才很奇怪,explain下?
最后应该都是一个key prefix seek。
实验了一下 go from “person_vid” over private_info yield $$.email.number
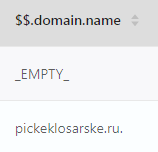
是能获取email的数据,但是返回结果里有很多phone.number “EMPTY”的数据,nebula是否应该在底层要过滤掉
kyle
10
已知问题。原因是通过 private_info 做拓展出来的其他 tag 取不到 number 属性就会返回 _EMPTY_, 我认为这样显示也是合理的。
后续会加入 IS NOT EMPTY 这样的算子用来过滤空行。
目前,你可以尝试这样做:
go from "person_vid" over private_info where $$.phone.number > -1 yield $$.phone.number
kyle
11
@steam 这里有一个 feature,增加 IS EMPTY 和 IS NOT EMPTY 算子
2 个赞
steam
15