Nebula Graph 版本号:2.0-rc1 rpm
部署方式:集群部署
创建点、点索引、然后重建,任务失败,如图

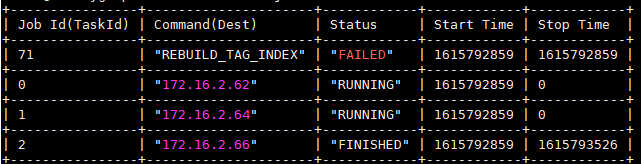
日志也没有显示问题
mated 错误日志
![]()
storaged 错误日志为空
RECOVER JOB 结果也是0
停止job报错
STOP JOB 71
[ERROR (-8)]: Save job failure!
其他说明,服务都正常,show hosts 也正常
这个数据集比较大,1kw点,1亿边
Nebula Graph 版本号:2.0-rc1 rpm
部署方式:集群部署
创建点、点索引、然后重建,任务失败,如图
日志也没有显示问题
mated 错误日志
![]()
storaged 错误日志为空
RECOVER JOB 结果也是0
停止job报错
STOP JOB 71
[ERROR (-8)]: Save job failure!
其他说明,服务都正常,show hosts 也正常
这个数据集比较大,1kw点,1亿边
请执行show hosts meta并截图
可能当时正在发生meta leader change,所以stop job失败
如果show hosts meta显示meta各节点正常,就可以再次执行rebuild index了
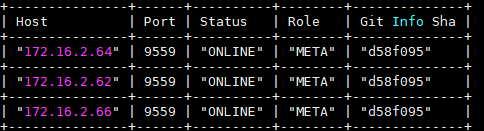
这是正常吧,重新rebuild 任务73 还是失败

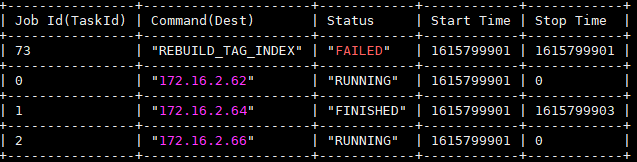
能否将目前环境升级至最新的nightly版本?
不排除是task manager的bug
想问一下task 0、1、2这三个任务是怎么执行的呢?
通常情况不会出现这种job
0.1.2是执行show job 85的结果
这是不是集群部署后,发送到每个节点的任务
正常情况下show job 85会显示85-0 85-1 85-2和三个节点的IP,而不是给每个节点显示独立job编号
所以看起来task manager的结果和预期有点偏差,请问已经升级到nightly了吗? 应该会对这个问题有帮助的
我升级了ga,问题还是没有解决啊
还有个线索是,vid我用了int64,导入数据时vid用了hash函数
创建索引的时候,storaged有报错
NebulaKeyUtils.h:262] rawKey.size() != expect size, rawKey.size() = 24, expect = 16, vIdLen = 8, rawkey hex format:
RC1和GA的数据是不兼容的
从 rc 升级到 ga 需要用升级工具重写数据,看这链接说明,按照上面操作下。
https://docs.nebula-graph.io/2.0/4.deployment-and-installation/3.upgrade-nebula-graph/
按照教程可以建索引了
查询的时候有报错,graphd.Error
lookup on test
E0326 15:30:35.380105 23534 StorageClientBase.inl:209] Request to "172.16.2.66":9779 failed: N6apache6thrift9transport19TTransportExceptionE: Timed Out
E0326 15:30:35.380072 23535 StorageClientBase.inl:209] Request to "172.16.2.62":9779 failed: N6apache6thrift9transport19TTransportExceptionE: Timed Out
E0326 15:30:35.382225 23599 StorageAccessExecutor.h:112] Storage Error: part: 30, error: E_RPC_FAILURE(-3).
E0326 15:30:35.382351 23599 QueryInstance.cpp:103] Storage Error: part: 30, error: E_RPC_FAILURE(-3).
首先,你确认storage服务是在的。
这个可能是你要拿的数据量比较大,storage处理时间超过graph的超时时间了,你可以在graphd的配置文件里面增加,这个参数默认是60秒
-- storage_client_timeout_ms = 120000
storage_client_timeout_ms 这个配置在文档中没有说明,默认配置中也没有吧
嗯,应该是超时了,我加了limit 1 还是全部遍历吗,也超时
storage_client_timeout_ms 这个配置在文档中没有说明,默认配置中也没有吧
你的graphd配置文件有没有把 enable_optimizer 这个开关打开,有的话,limit才会下推给storage,不然会把数据捞到graphd再做limit。
我开启了 enable_optimizer 重启后,好像没有生效,limit 1 还是超时了,
– storage_client_timeout_ms = 120000 也设置了
数据量 3kw点,1.4亿边
用 lookup test这个标签是没有下推的,你不会3kw个点都是这个标签吧,这样肯定超时的。
是啊,3kw的人也不多吧,
每个tag最大实体数是多少,这个测试过吗,有没有推荐值
这样的场景你们有没有实战经验,怎么解决呢
你为啥要把这个标签所有点拿出来,没有过滤条件吗?
lookup 下推的我们内部会建这个需求,后续实现上。
