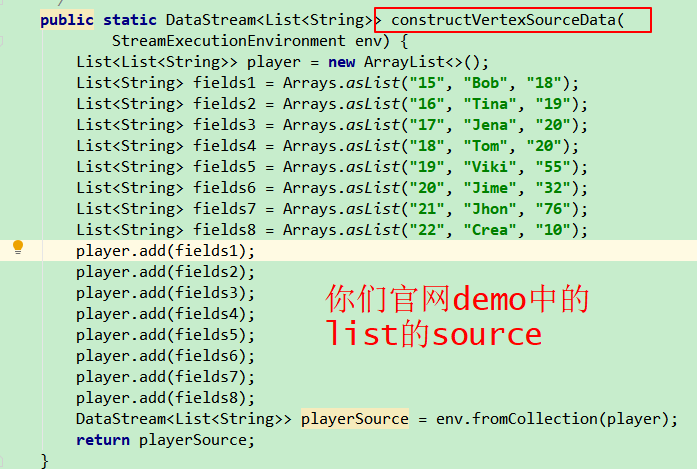
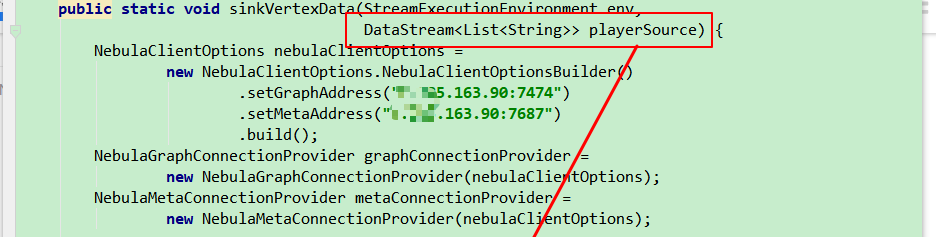
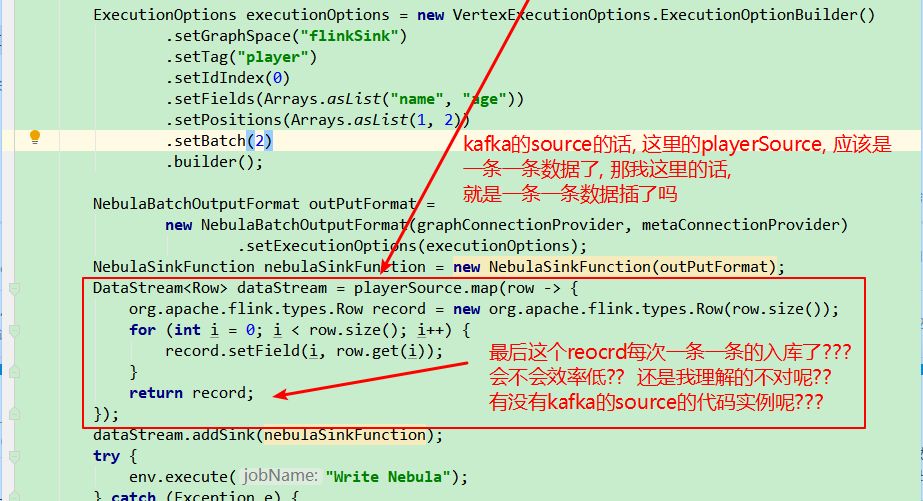
nebula 1.2.0
exchange 1.1.0
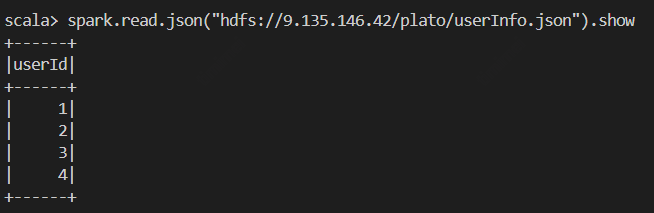
userInfo.json:
[{"userId": 1}, {"userId": 2}, {"userId": 3}, {"userId": 4}]
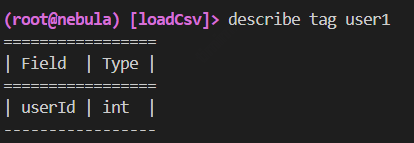
user表:
>>>describe user
>>>
===================
| Field | Type |
===================
| userId | string |
-------------------
报错:
Exception in thread "main" java.util.NoSuchElementException: key not found: userId
at scala.collection.MapLike$class.default(MapLike.scala:228)
at scala.collection.AbstractMap.default(Map.scala:59)
at scala.collection.MapLike$class.apply(MapLike.scala:141)
at scala.collection.AbstractMap.apply(Map.scala:59)
at com.vesoft.nebula.tools.importer.utils.NebulaUtils$$anonfun$getDataSourceFieldType$1.apply(NebulaUtils.scala:65)
at com.vesoft.nebula.tools.importer.utils.NebulaUtils$$anonfun$getDataSourceFieldType$1.apply(NebulaUtils.scala:64)
at scala.collection.immutable.Range.foreach(Range.scala:160)
at com.vesoft.nebula.tools.importer.utils.NebulaUtils$.getDataSourceFieldType(NebulaUtils.scala:64)
at com.vesoft.nebula.tools.importer.processor.VerticesProcessor.process(VerticesProcessor.scala:137)
at com.vesoft.nebula.tools.importer.Exchange$$anonfun$main$2.apply(Exchange.scala:174)
at com.vesoft.nebula.tools.importer.Exchange$$anonfun$main$2.apply(Exchange.scala:152)
at scala.collection.immutable.List.foreach(List.scala:392)
at com.vesoft.nebula.tools.importer.Exchange$.main(Exchange.scala:152)
at com.vesoft.nebula.tools.importer.Exchange.main(Exchange.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:845)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:161)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:184)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:920)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:929)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
这是application.conf:
{
# Spark relation config
spark: {
app: {
name: Spark Writer
}
driver: {
cores: 1
maxResultSize: 1G
}
cores {
max: 16
}
}
# Nebula Graph relation config
nebula: {
address:{
graph:["9.135.95.249:13708"]
meta:["9.135.95.249:22343"]
}
user: root
pswd: nebula
space: loadCsv
connection {
timeout: 3000
retry: 3
}
execution {
retry: 3
}
error: {
max: 32
output: /tmp/errors
}
rate: {
limit: 1024
timeout: 1000
}
}
# Processing tags
tags: [
# Loading tag from HDFS and data type is json
{
name: user
type: {
source: json
sink: client
}
path: "hdfs://9.135.146.42/plato/userInfo.json"
fields: ["userId"]
nebula.fields: ["userId"]
vertex: {
field:userId,
policy:"hash"
}
separator: ","
header: true
batch: 256
partition: 32
isImplicit: true
}
]
}
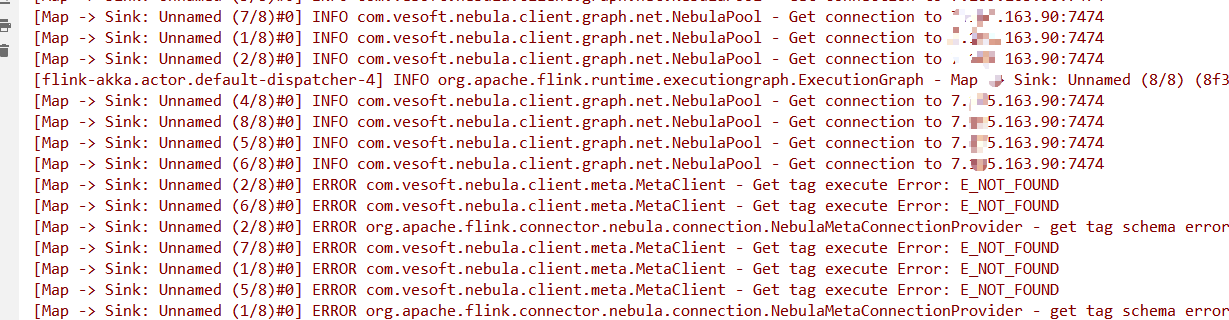
导入csv也一样不知道发生什么事了
真的可以说是非常之绝望了
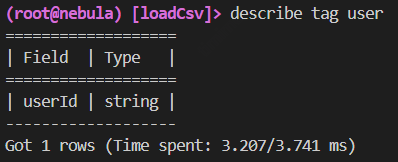
 , 我还以为是自己自动创建,
, 我还以为是自己自动创建,