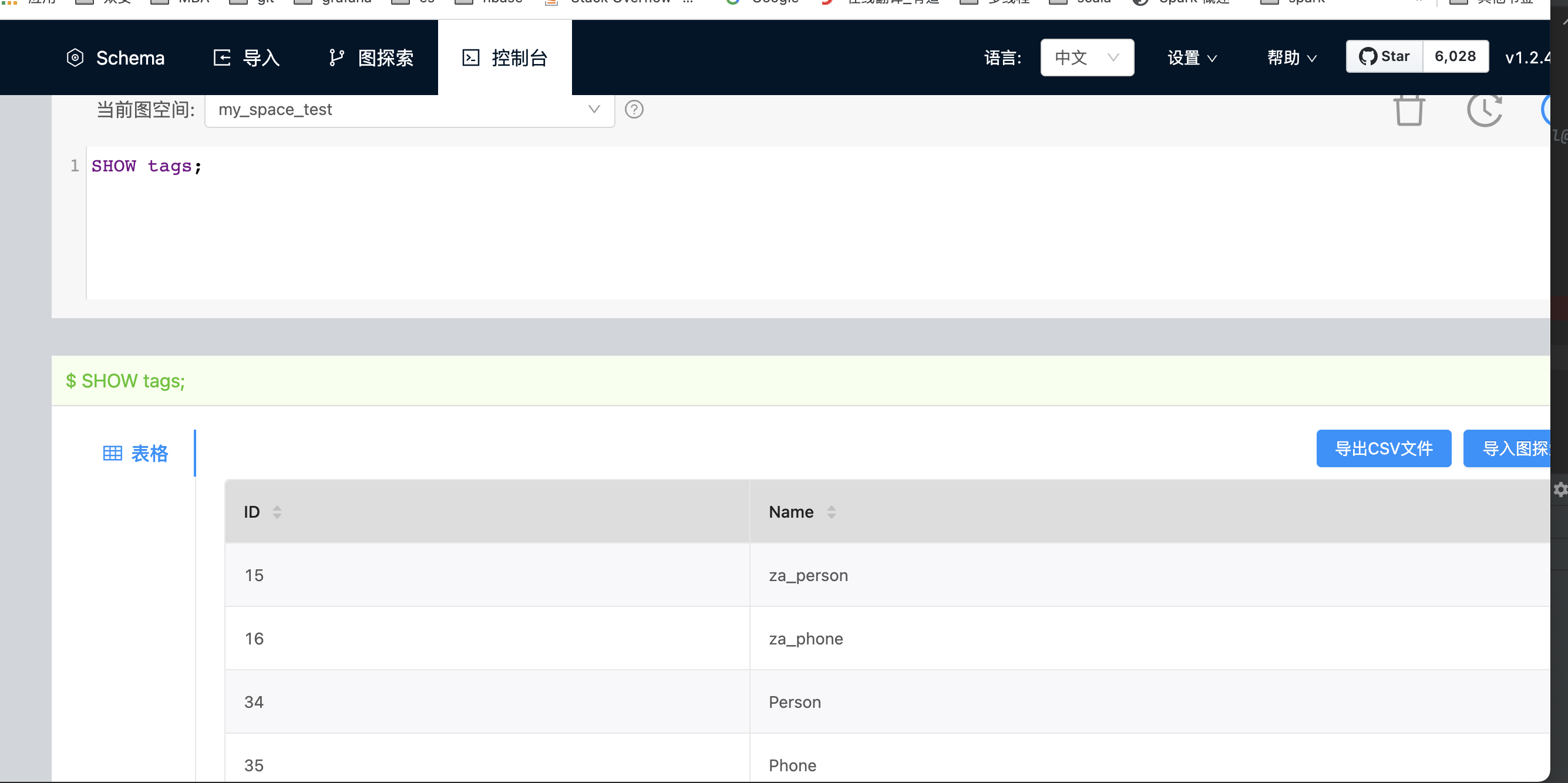
我看了一下,nebula服务没有装的docker上,只有web服务装在了docker上,我刚去nebula/etc/nebula-metad.conf里看了一下,metad的地址是172.20.216.157:45500,172.20.216.158:45500,172.20.216.159:45500。与我在nebula-spark里配置的地址是一致的,并且我在studio上show tags也是有返回数据的。从输出的info日志上看,貌似是连上了metad,但是返回的结果都是null。下面我贴上日志,还请麻烦帮我看下是哪里有问题导致的读不到meta数据。
···
WARN [main] - Your hostname, AppledeMacBook-Pro.local resolves to a loopback address: 127.0.0.1; using 192.168.2.7 instead (on interface en0)
WARN [main] - Set SPARK_LOCAL_IP if you need to bind to another address
INFO [main] - Running Spark version 2.4.4
WARN [main] - Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
INFO [main] - Submitted application: a9b84ab1-d2f4-40d5-b173-9ffd91b22bb9
INFO [main] - Changing view acls to: LeoChan
INFO [main] - Changing modify acls to: LeoChan
INFO [main] - Changing view acls groups to:
INFO [main] - Changing modify acls groups to:
INFO [main] - SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(LeoChan); groups with view permissions: Set(); users with modify permissions: Set(LeoChan); groups with modify permissions: Set()
INFO [main] - Successfully started service ‘sparkDriver’ on port 63737.
INFO [main] - Registering MapOutputTracker
INFO [main] - Registering BlockManagerMaster
INFO [main] - Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
INFO [main] - BlockManagerMasterEndpoint up
INFO [main] - Created local directory at /private/var/folders/my/ynmt0wvx0xz8gw22cjy030p80000gp/T/blockmgr-9d90ee83-0d3c-43d6-9a42-cb3a038ba2ad
INFO [main] - MemoryStore started with capacity 2004.6 MB
INFO [main] - Registering OutputCommitCoordinator
INFO [main] - Logging initialized @1340ms
INFO [main] - jetty-9.3.z-SNAPSHOT, build timestamp: unknown, git hash: unknown
INFO [main] - Started @1392ms
INFO [main] - Started ServerConnector@5b58ed3c{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
INFO [main] - Successfully started service ‘SparkUI’ on port 4040.
INFO [main] - Started o.s.j.s.ServletContextHandler@4c168660{/jobs,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@5b970f7{/jobs/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@7fd4acee{/jobs/job,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@6175619b{/jobs/job/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@2f058b8a{/stages,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@756cf158{/stages/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@3f2ef586{/stages/stage,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@64337702{/stages/stage/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@2cf92cc7{/stages/pool,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@30ea8c23{/stages/pool/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@7b139eab{/storage,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@4e76dac{/storage/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@611df6e3{/storage/rdd,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@5f2f577{/storage/rdd/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@6273c5a4{/environment,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@5d465e4b{/environment/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@53e211ee{/executors,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@41a90fa8{/executors/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@3d8bbcdc{/executors/threadDump,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@52500920{/executors/threadDump/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@117e0fe5{/static,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@5ac86ba5{/,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@6c67e137{/api,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@53ab0286{/jobs/job/kill,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@63c5efee{/stages/stage/kill,null,AVAILABLE,@Spark}
INFO [main] - Bound SparkUI to 0.0.0.0, and started at http://192.168.2.7:4040
INFO [main] - Starting executor ID driver on host localhost
INFO [main] - Successfully started service ‘org.apache.spark.network.netty.NettyBlockTransferService’ on port 63751.
INFO [main] - Server created on 192.168.2.7:63751
INFO [main] - Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
INFO [main] - Registering BlockManager BlockManagerId(driver, 192.168.2.7, 63751, None)
INFO [dispatcher-event-loop-2] - Registering block manager 192.168.2.7:63751 with 2004.6 MB RAM, BlockManagerId(driver, 192.168.2.7, 63751, None)
INFO [main] - Registered BlockManager BlockManagerId(driver, 192.168.2.7, 63751, None)
INFO [main] - Initialized BlockManager: BlockManagerId(driver, 192.168.2.7, 63751, None)
INFO [main] - Started o.s.j.s.ServletContextHandler@109f5dd8{/metrics/json,null,AVAILABLE,@Spark}
INFO [main] - Setting hive.metastore.warehouse.dir (‘null’) to the value of spark.sql.warehouse.dir (‘file:/Users/LeoChan/za-workspace/za-finance-plotify/spark-warehouse’).
INFO [main] - Warehouse path is ‘file:/Users/LeoChan/za-workspace/za-finance-plotify/spark-warehouse’.
INFO [main] - Started o.s.j.s.ServletContextHandler@7180e701{/SQL,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@4e2c95ee{/SQL/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@5942ee04{/SQL/execution,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@5e76a2bb{/SQL/execution/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@6dc1484{/static/sql,null,AVAILABLE,@Spark}
INFO [main] - Registered StateStoreCoordinator endpoint
ERROR [main] - response of listTags is null.
ERROR [main] - response of getEdges is null.
ERROR [main] - response of getTag is null.
INFO [Thread-1] - Invoking stop() from shutdown hook
INFO [Thread-1] - Stopped Spark@5b58ed3c{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
INFO [Thread-1] - Stopped Spark web UI at http://192.168.2.7:4040
INFO [dispatcher-event-loop-7] - MapOutputTrackerMasterEndpoint stopped!
Exception in thread “main” java.lang.NullPointerException
at com.vesoft.nebula.tools.connector.reader.NebulaRelation$$anonfun$getSchema$1.apply(NebulaRelation.scala:61)
at com.vesoft.nebula.tools.connector.reader.NebulaRelation$$anonfun$getSchema$1.apply(NebulaRelation.scala:52)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at scala.collection.MapLike$DefaultKeySet.foreach(MapLike.scala:174)
at com.vesoft.nebula.tools.connector.reader.NebulaRelation.getSchema(NebulaRelation.scala:52)
at com.vesoft.nebula.tools.connector.reader.NebulaRelation.schema(NebulaRelation.scala:32)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:403)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:223)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:208)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:167)
at com.vesoft.nebula.tools.connector.package$NebulaDataFrameReader.loadVerticesToDF(package.scala:95)
at com.test.Test$.main(Test.scala:29)
at com.test.Test.main(Test.scala)
INFO [Thread-1] - MemoryStore cleared
INFO [Thread-1] - BlockManager stopped
INFO [Thread-1] - BlockManagerMaster stopped
INFO [dispatcher-event-loop-4] - OutputCommitCoordinator stopped!
INFO [Thread-1] - Successfully stopped SparkContext
INFO [Thread-1] - Shutdown hook called
INFO [Thread-1] - Deleting directory /private/var/folders/my/ynmt0wvx0xz8gw22cjy030p80000gp/T/spark-dacbecf6-93aa-4bfb-bc2a-d6c33d8ad285
Process finished with exit code 1