- nebula 版本:2.0 GA
- 部署方式(分布式 / 单机 / Docker / DBaaS):单机
- 硬件信息
- 磁盘( 推荐使用 SSD)500G
- CPU、内存信息 40G、128G
- 问题的具体描述
你好,我今天开始测试nebula 2.0GA的数据导入,同一条insert语句,使用console可以导入成功,但是改用go-client导入报错。
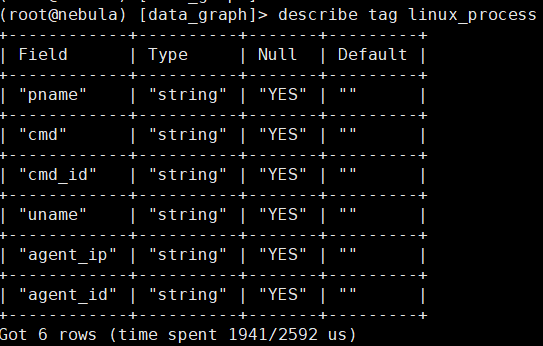
tag schema:
insert语句:
INSERT VERTEX linux_process(pname,cmd,cmd_id,uname,agent_ip,agent_id) VALUES “f3f1efc6-54d0-49c8-85b9-e4e9c87c36f7”: (“hydra”,“hydra -l root -P passwords_1.txt -t 5 -vV 192.168.191.224 ssh “,””,“root”,“192.168.191.228”,“5f719ad353c4955e”);
storage错误信息:
E0329 16:42:18.763407 239693 AddVerticesProcessor.cpp:272] vertex conflict 2:1:15:92a9e881-5abc-4040-9e54-4dc91126e05b
go-client版本:
GitHub - vesoft-inc/nebula-go: Nebula client in Golang v1.1.1-0.20210324022038-7e94e0910165
Aiee
3
你好,console的query执行是通过调用go client实现的,理论上两者不会有差异。
版本看上去是对的,能贴一下你怎么调用客户端的吗?
1 个赞
Aiee
5
我在本地执行你的query没有问题
query := "INSERT VERTEX linux_process(pname,cmd,cmd_id,uname,agent_ip,agent_id) VALUES “f3f1efc6-54d0-49c8-85b9-e4e9c87c36f7”: (“hydra”,“hydra -l root -P passwords_1.txt -t 5 -vV 192.168.191.224 ssh “,””,“root”,“192.168.191.228”,“5f719ad353c4955e”);"
resultSet, err = session.Execute(query)
if err != nil {
fmt.Print(err.Error())
return
}
你可以成功执行其他的query吗?
Aiee
6
另外你提问中的
insert语句:
INSERT VERTEX linux_process(pname,cmd,cmd_id,uname,agent_ip,agent_id) VALUES “f3f1efc6-54d0-49c8-85b9-e4e9c87c36f7”: (“hydra”,“hydra -l root -P passwords_1.txt -t 5 -vV 192.168.191.224 ssh “,””,“root”,“192.168.191.228”,“5f719ad353c4955e”);
和
storage错误信息:
E0329 16:42:18.763407 239693 AddVerticesProcessor.cpp:272] vertex conflict 2:1:15:92a9e881-5abc-4040-9e54-4dc91126e05b
中的点ID不一样,说明错误不是由那条query引起的。
可以贴一下完整调用客户端的代码和graphd的日志吗?
你好,我写了个简单的demo测试入库,确实是可以的,包括并发情况下入库。我再仔细review下我之前的代码,应该是哪里写的有漏洞。
非常感谢你帮忙定位问题,后续有疑问再麻烦你,多谢了 
Aiee
8
不客气,问题可能出在并发的情况,为了防止同一batch中一个点还没完成插入时用对同个点有修改我们做了限制,所有会有vertex conflict这个报错
1 个赞
确实是,我之前的代码只要开启并发入库就报那个错误,我再仔细排查下。
请问下报vertex conflict这个错误时,这个点最终还是会成功insert的吧。
我调试了下demo程序,发现Execute方法返回的resp参数中的errcode是E_EXECUTION_ERROR,但是返回的error参数是nil,这两个返回的错误部分,以哪个为准来判断是否是会导致插入失败的错误呢?
Aiee
11
在 Execute(sessionId int64, stmt []byte) (r *ExecutionResponse, err error) 接口定义中, r *ExecutionResponse 是执行query后服务端返回的结果,err error 表示的是thrift的通信是否成功,假如网络出现异常导致query发不到服务端那么err error就不会是nil了。
所以这个场景应该用 r *ExecutionResponse中的errorcode来判断
奥奥,明白了。
但是ExecutionResponse结构的GetErrorCode方法返回的错误码是E_EXECUTION_ERROR,GetErrorMsg方法返回的是详细错误信息,其中有storage的错误码E_DATA_CONFLICT_ERROR,但是是字符串信息,有办法在错误发生时能判断是不是点冲突导致的错误吗,这样我们的业务就可以直接忽略这种错误了。
还有个疑问,如果两个batch中有一个相同的点,其他都是不同的点,将这两个batch并发insert时因为那两个相同的点报了vertex conflict错误,是只有冲突的那个点不会重复入库,还是这整个batch都不会入库了呢?
