- nebula 版本:2.0-GA
- 部署方式:分布式 4台机器,3台storage 1台meta 单独1台 graph
- 硬件信息
- 磁盘( 推荐使用 SSD)1.2T
- CPU、内存信息 96C 512G内存
- 问题的具体描述
使用2.0版本的nebula-import导入数据,速度太慢。模板使用了官方提供的example.yaml
图结构为9点15边,同一个example.yaml里边写了所有的数据文件,每个文件大概130w左右。
部分配置如下
version: v2
description: example
removeTempFiles: false
clientSettings:
retry: 3
concurrency: 100 # number of graph clients
channelBufferSize: 2560
space: test1
connection:
user: root
password: nebula
address: xxxx:9669
--------------------
- path: /opt/soft/data/id.csv
failDataPath: /opt/soft/data/err/id.csv
batchSize: 2560
type: csv
csv:
创建space的语句
CREATE SPACE IF NOT EXISTS cmis(partition_num=100, replica_factor=3, vid_type=FIXED_STRING(200));
- 相关的 meta / storage / graph配置基本使用默认配置
仅storage 修改了
rocksdb_block_cache=1024
"write_buffer_size":"268435456"
最终运行结果:共计34030000条数据 耗时1145s 速度29712/s
没有使用索引,也关闭了自动compact。
随后尝试修改example.yaml的channelBufferSize和batchSize,均没有明显提升,甚至速度下降。
之前使用nebula1.2版本时,1.0的import导入Twitter数据集,速度均在50w左右。
yee
2
我在这个帖子中有回复影响导入速度的几点原因。
现在需要先确定是 nebula-importer 的问题还是 nebula graph 的问题,首先看看 importer 的 IO 是否合理,importer 的运行机制是每个文件一个线程负责读,有 concurrency 个线程负责向 nebula 发压,是个多生产者多消费者的实现。
如果是 importer 的压力上不来,再针对性的看 importer 的问题,如果是 nebula 的 storage 的写入速率慢,需要 @critical27 协助看下调优的问题。
又测试了一遍,这次concurrency:100 ,channelBufferSize:2560,batchsize:128
这次导入速度提高到5w/S左右
查看了storage的io写入速度,在30M到180M之间,cpu占用在500%左右,并不是很稳定,写入瓶颈应该不是问题。
graph的cpu占用也不大,在100-300%左右
import的cpu占用只有30%左右,查看io没发现有较大的数值。

是不是应该提高import的压力?
import batchsize改大 storage写路径和1.0几乎没啥区别 storage线程数可以改大点 我自己环境可以到几十万
yee
7
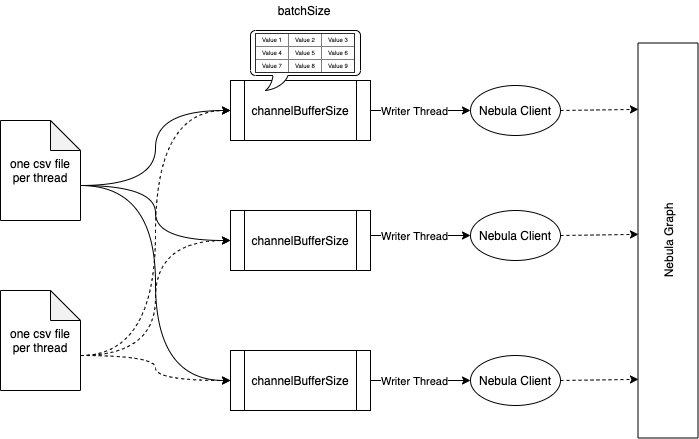
concurrency 设置成机器的 cores 数就差不多了, importer 的实现原理如下图所示:
每个文件一个读线程,同时启动 concurrency 个 client 用来给 nebula graph 发压,每个 client 都有个 channelBufferSize 大小的 queue 用来缓存数据,queue 中存放的是按 batch 组装好的 nGQL INSERT 语句,读线程会将读到的数据分发给每个 client 的 queue。所以如果 importer 的 rps 不高,看看是不是 insert 语句的 latency 较高,如果是的话,检查一下网络状况和网卡。
4 个赞
查看磁盘发现用的是机械盘,然后切换到固态盘进行测试,也调整了import的参数,要比之前快的多。
Time(261.35s), Finished(34030000), Failed(0), Latency AVG(821606us), Batches Req AVG(860819us), Rows AVG(130206.19/s)
查看网络带宽占用很高,达到了80%以上,但是磁盘的读写速度并不高,只有200M/S左右,storage的线程数设置了32,估计再调高一点还会更快吧。
想问一下写入跟数据有没有关系,主键用到了100个长度以上的中文字段。
yee
9
使用的千兆网卡?
建议设置合适的 VID 长度,因为是 fixed string,如果设置了很大,即使实际中没有用到那么长,也会占用那么大的空间,网络传输和磁盘 io 的数据肯定也会更多。
是的,千兆网卡。vid限制200,同一个space不能同时使用int和string吧
yee
11
千兆卡的话,瓶颈在网络了。importer 这边压力肯定上不去,也发挥不了 ssd 的性能。
vid_type 是在创建 space 的时候指定的,中间不能更改,亦不能混合不同的类型