concurrency 设置成机器的 cores 数就差不多了, importer 的实现原理如下图所示:
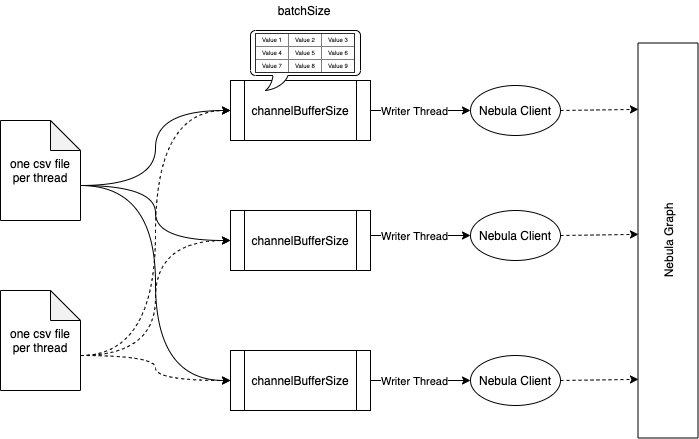
每个文件一个读线程,同时启动 concurrency 个 client 用来给 nebula graph 发压,每个 client 都有个 channelBufferSize 大小的 queue 用来缓存数据,queue 中存放的是按 batch 组装好的 nGQL INSERT 语句,读线程会将读到的数据分发给每个 client 的 queue。所以如果 importer 的 rps 不高,看看是不是 insert 语句的 latency 较高,如果是的话,检查一下网络状况和网卡。