提问参考模版:
- nebula 版本:1.1.0
- Spark Writer 版本:v1.0
- 部署方式:分布式
- 问题的具体描述:
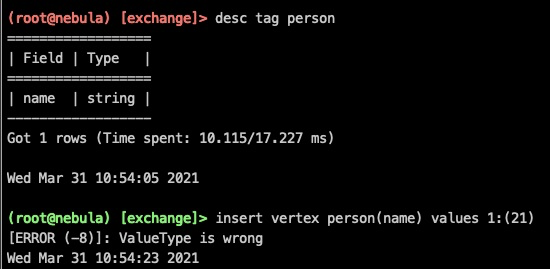
按照官网的步骤编译了nebula-spark项目,导入maven。
然后按照官网给的writer示例写了一下,报valueType worry的错
代码:
val sparkSession = SparkSession
.builder()
.master("local[*]")
.getOrCreate()
val someData = Seq(
Row("310115199309122211", "310115199309122211"),
Row("310115199309122222", "310115199309122222"),
Row("310115199309122233", "310115199309122233")
)
val someSchema = List(
StructField("vid", StringType, true),
StructField("certi_no", StringType, true)
)
val vertexDF = sparkSession.createDataFrame(
sparkSession.sparkContext.parallelize(someData),
StructType(someSchema)
)
// 写入点
vertexDF.write
.nebula("172.20.216.159:3699", "my_space_test", "30")
.writeVertices("za_spark_person", "vid", "hash")
日志:
ERROR [pool-18-thread-1] - execute error: ValueType is wrong
ERROR [pool-19-thread-1] - execute error: ValueType is wrong
ERROR [pool-17-thread-1] - execute error: ValueType is wrong

 。
。