-
nebula 版本:nebula-graph-2.0.0-1.x86_64
-
部署方式:单机
-
硬件信息
- 磁盘:SSD
- CPU、内存信息: 4核32G
-
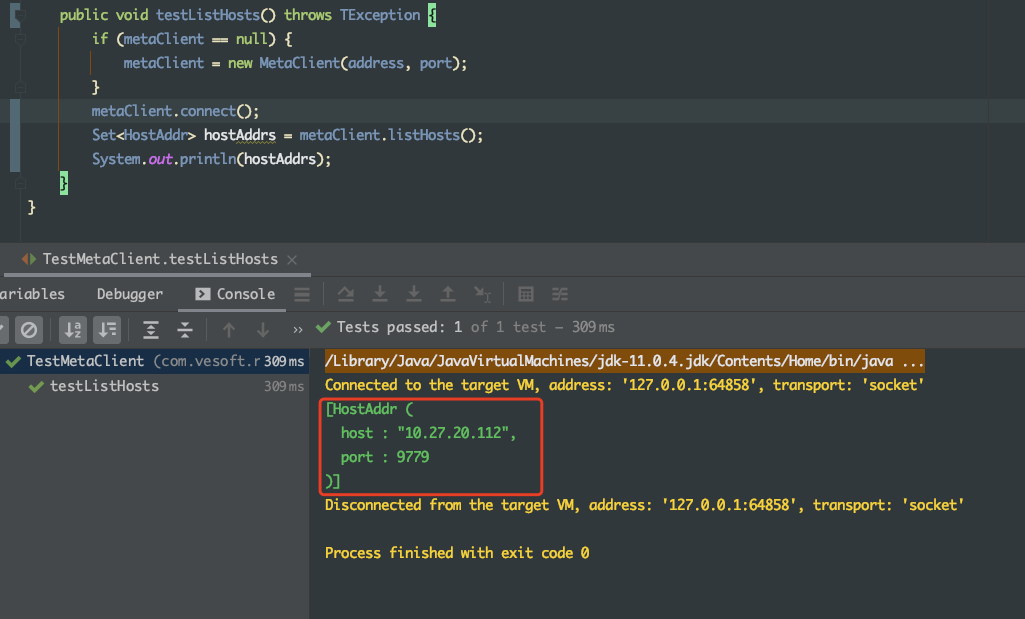
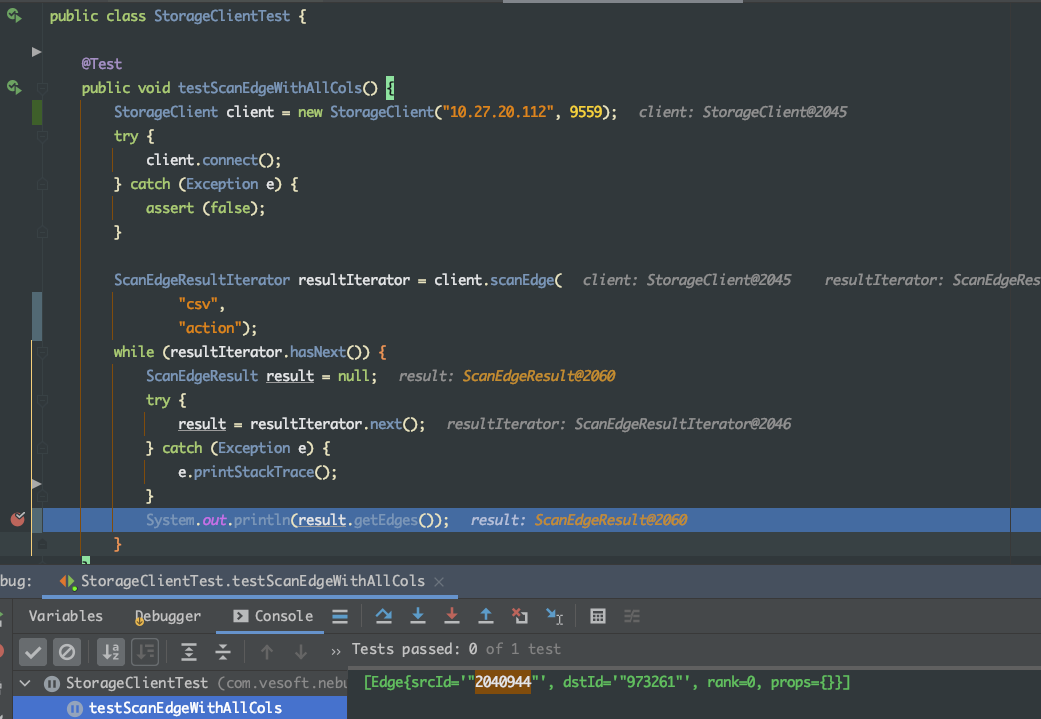
问题描述:单机安装Nebula Graph后,参考 nebula-spark-utils/nebula-spark-connector at master · vesoft-inc/nebula-spark-utils · GitHub 中的代码连接nebula并运行PageRank任务后报错
-
相关的 meta / storage / graph info 日志信息
nebula端口信息:
# ./scripts/nebula.service status all
[INFO] nebula-metad: Running as 4977, Listening on 9559
[INFO] nebula-graphd: Running as 5067, Listening on 9669
[INFO] nebula-storaged: Running as 5085, Listening on 9779
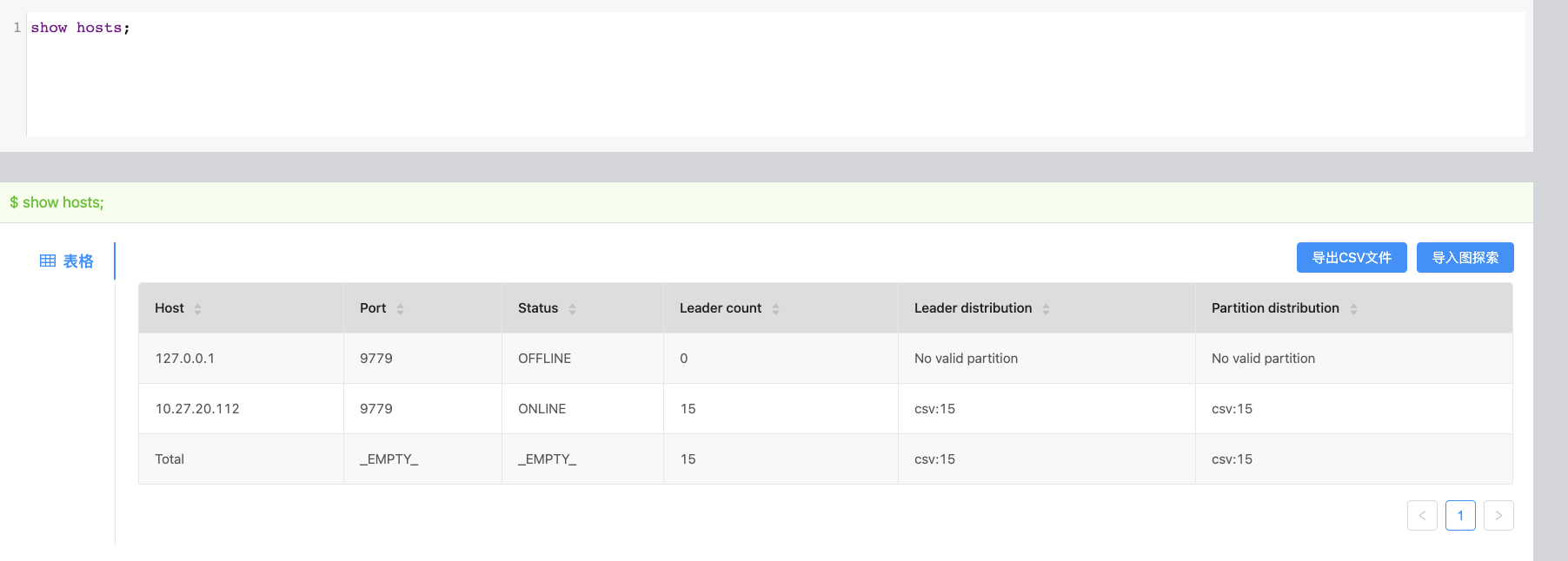
show hosts命令结果
graphd配置文件:
# cat nebula-graphd.conf
########## basics ##########
# Whether to run as a daemon process
--daemonize=true
# The file to host the process id
--pid_file=pids/nebula-graphd.pid
# Whether to enable optimizer
--enable_optimizer=true
########## logging ##########
# The directory to host logging files, which must already exists
--log_dir=logs
# Log level, 0, 1, 2, 3 for INFO, WARNING, ERROR, FATAL respectively
--minloglevel=0
# Verbose log level, 1, 2, 3, 4, the higher of the level, the more verbose of the logging
--v=0
# Maximum seconds to buffer the log messages
--logbufsecs=0
# Whether to redirect stdout and stderr to separate output files
--redirect_stdout=true
# Destination filename of stdout and stderr, which will also reside in log_dir.
--stdout_log_file=graphd-stdout.log
--stderr_log_file=graphd-stderr.log
# Copy log messages at or above this level to stderr in addition to logfiles. The numbers of severity levels INFO, WARNING, ERROR, and FATAL are 0, 1, 2, and 3, respectively.
--stderrthreshold=2
########## query ##########
# Whether to treat partial success as an error.
# This flag is only used for Read-only access, and Modify access always treats partial success as an error.
--accept_partial_success=false
########## networking ##########
# Comma separated Meta Server Addresses
--meta_server_addrs=10.27.20.112:9559
# Local IP used to identify the nebula-graphd process.
# Change it to an address other than loopback if the service is distributed or
# will be accessed remotely.
--local_ip=10.27.20.112
# Network device to listen on
--listen_netdev=any
# Port to listen on
--port=9669
# To turn on SO_REUSEPORT or not
--reuse_port=false
# Backlog of the listen socket, adjust this together with net.core.somaxconn
--listen_backlog=1024
# Seconds before the idle connections are closed, 0 for never closed
--client_idle_timeout_secs=0
# Seconds before the idle sessions are expired, 0 for no expiration
--session_idle_timeout_secs=0
# The number of threads to accept incoming connections
--num_accept_threads=1
# The number of networking IO threads, 0 for # of CPU cores
--num_netio_threads=0
# The number of threads to execute user queries, 0 for # of CPU cores
--num_worker_threads=0
# HTTP service ip
--ws_ip=0.0.0.0
# HTTP service port
--ws_http_port=19669
# HTTP2 service port
--ws_h2_port=19670
# The default charset when a space is created
--default_charset=utf8
# The defaule collate when a space is created
--default_collate=utf8_bin
########## authorization ##########
# Enable authorization
--enable_authorize=false
########## Authentication ##########
# User login authentication type, password for nebula authentication, ldap for ldap authentication, cloud for cloud authentication
--auth_type=password
metad配置文件:
# cat nebula-metad.conf
########## basics ##########
# Whether to run as a daemon process
--daemonize=true
# The file to host the process id
--pid_file=pids/nebula-metad.pid
########## logging ##########
# The directory to host logging files, which must already exists
--log_dir=logs
# Log level, 0, 1, 2, 3 for INFO, WARNING, ERROR, FATAL respectively
--minloglevel=0
# Verbose log level, 1, 2, 3, 4, the higher of the level, the more verbose of the logging
--v=0
# Maximum seconds to buffer the log messages
--logbufsecs=0
# Whether to redirect stdout and stderr to separate output files
--redirect_stdout=true
# Destination filename of stdout and stderr, which will also reside in log_dir.
--stdout_log_file=metad-stdout.log
--stderr_log_file=metad-stderr.log
# Copy log messages at or above this level to stderr in addition to logfiles. The numbers of severity levels INFO, WARNING, ERROR, and FATAL are 0, 1, 2, and 3, respectively.
--stderrthreshold=2
########## networking ##########
# Comma separated Meta Server addresses
--meta_server_addrs=10.27.20.112:9559
# Local IP used to identify the nebula-metad process.
# Change it to an address other than loopback if the service is distributed or
# will be accessed remotely.
--local_ip=10.27.20.112
# Meta daemon listening port
--port=9559
# HTTP service ip
--ws_ip=0.0.0.0
# HTTP service port
--ws_http_port=19559
# HTTP2 service port
--ws_h2_port=19560
########## storage ##########
# Root data path, here should be only single path for metad
--data_path=data/meta
########## Misc #########
# The default number of parts when a space is created
--default_parts_num=100
# The default replica factor when a space is created
--default_replica_factor=1
--heartbeat_interval_secs=10
storaged配置文件:
# cat nebula-storaged.conf
########## basics ##########
# Whether to run as a daemon process
--daemonize=true# The file to host the process id
--pid_file=pids/nebula-storaged.pid
########## logging ##########
# The directory to host logging files, which must already exists
--log_dir=logs
# Log level, 0, 1, 2, 3 for INFO, WARNING, ERROR, FATAL respectively
--minloglevel=0
# Verbose log level, 1, 2, 3, 4, the higher of the level, the more verbose of the logging
--v=0
# Maximum seconds to buffer the log messages
--logbufsecs=0
# Whether to redirect stdout and stderr to separate output files
--redirect_stdout=true
# Destination filename of stdout and stderr, which will also reside in log_dir.
--stdout_log_file=storaged-stdout.log
--stderr_log_file=storaged-stderr.log
# Copy log messages at or above this level to stderr in addition to logfiles. The numbers of severity levels INFO, WARNING, ERROR, and FATAL are 0, 1, 2, and 3, respectively.
--stderrthreshold=2
########## networking ##########
# Comma separated Meta server addresses
--meta_server_addrs=10.27.20.112:9559
# Local IP used to identify the nebula-storaged process.
# Change it to an address other than loopback if the service is distributed or
# will be accessed remotely.
--local_ip=10.27.20.112
# Storage daemon listening port
--port=9779
# HTTP service ip
--ws_ip=0.0.0.0
# HTTP service port
--ws_http_port=19779
# HTTP2 service port
--ws_h2_port=19780
# heartbeat with meta service
--heartbeat_interval_secs=10
######### Raft #########
# Raft election timeout
--raft_heartbeat_interval_secs=30
# RPC timeout for raft client (ms)
--raft_rpc_timeout_ms=500
## recycle Raft WAL
--wal_ttl=14400
########## Disk ##########
# Root data path. Split by comma. e.g. --data_path=/disk1/path1/,/disk2/path2/
# One path per Rocksdb instance.
--data_path=data/storage
# The default reserved bytes for one batch operation
--rocksdb_batch_size=4096
# The default block cache size used in BlockBasedTable.
# The unit is MB.
--rocksdb_block_cache=4
# The type of storage engine, `rocksdb', `memory', etc.
--engine_type=rocksdb
# Compression algorithm, options: no,snappy,lz4,lz4hc,zlib,bzip2,zstd
# For the sake of binary compatibility, the default value is snappy.
# Recommend to use:
# * lz4 to gain more CPU performance, with the same compression ratio with snappy
# * zstd to occupy less disk space
# * lz4hc for the read-heavy write-light scenario
--rocksdb_compression=lz4
# Set different compressions for different levels
# For example, if --rocksdb_compression is snappy,
# "no:no:lz4:lz4::zstd" is identical to "no:no:lz4:lz4:snappy:zstd:snappy"
# In order to disable compression for level 0/1, set it to "no:no"
--rocksdb_compression_per_level=
# Whether or not to enable rocksdb's statistics, disabled by default
--enable_rocksdb_statistics=false
# Statslevel used by rocksdb to collection statistics, optional values are
# * kExceptHistogramOrTimers, disable timer stats, and skip histogram stats
# * kExceptTimers, Skip timer stats
# * kExceptDetailedTimers, Collect all stats except time inside mutex lock AND time spent on compression.
# * kExceptTimeForMutex, Collect all stats except the counters requiring to get time inside the mutex lock.
# * kAll, Collect all stats
--rocksdb_stats_level=kExceptHistogramOrTimers
# Whether or not to enable rocksdb's prefix bloom filter, disabled by default.
--enable_rocksdb_prefix_filtering=false
# Whether or not to enable the whole key filtering.
--enable_rocksdb_whole_key_filtering=true
# The prefix length for each key to use as the filter value.
# can be 12 bytes(PartitionId + VertexID), or 16 bytes(PartitionId + VertexID + TagID/EdgeType).
--rocksdb_filtering_prefix_length=12
############## rocksdb Options ##############
# rocksdb DBOptions in json, each name and value of option is a string, given as "option_name":"option_value" separated by comma
--rocksdb_db_options={}
# rocksdb ColumnFamilyOptions in json, each name and value of option is string, given as "option_name":"option_value" separated by comma
--rocksdb_column_family_options={"write_buffer_size":"67108864","max_write_buffer_number":"4","max_bytes_for_level_base":"268435456"}
# rocksdb BlockBasedTableOptions in json, each name and value of option is string, given as "option_name":"option_value" separated by comma
--rocksdb_block_based_table_options={"block_size":"8192"}
建表Schema:
CREATE SPACE csv(partition_num = 15, replica_factor = 1);
CREATE TAG user(id string);
CREATE EDGE action (startId string, endId string);
CREATE TAG INDEX id_idx ON user(id(20));
REBUILD TAG INDEX id_idx;
执行代码:
import java.text.SimpleDateFormat
import com.facebook.thrift.protocol.TCompactProtocol
import org.apache.spark.graphx.Graph
import com.vesoft.nebula.connector.connector.NebulaDataFrameReader
import com.vesoft.nebula.connector.{NebulaConnectionConfig, ReadNebulaConfig}
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
val df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val sparkConf = new SparkConf
sparkConf
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(Array[Class[_]](classOf[TCompactProtocol]))
val spark = SparkSession
.builder()
.master("local")
.config(sparkConf)
.getOrCreate()
val config = NebulaConnectionConfig
.builder()
.withMetaAddress("10.27.20.112:9559")
.build()
val nebulaReadVertexConfig = ReadNebulaConfig
.builder()
.withSpace("csv")
.withLabel("user")
.withNoColumn(false)
.build()
val nebulaReadEdgeConfig = ReadNebulaConfig
.builder()
.withSpace("csv")
.withLabel("action")
.withNoColumn(false)
.build()
val vertexRDD = spark.read.nebula(config, nebulaReadVertexConfig).loadVerticesToGraphx()
val edgeRDD = spark.read.nebula(config, nebulaReadEdgeConfig).loadEdgesToGraphx()
val graph = Graph(vertexRDD, edgeRDD)
println("===============edges count================ is " + graph.edges.count())
println("===============Start run pageRank================time is " + df.format(System.currentTimeMillis()))
val ranks = graph.pageRank(0.0001).vertices
println("==============pageRank compute end================time is " + df.format(System.currentTimeMillis()))
println(ranks.top(10).mkString("\n"))
执行后报错:
# spark-shell -i NebulaSparkReaderExample.scala
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/data1/spark/spark-2.4.7-bin-hadoop2.7/jars/nebula-spark-connector-2.0.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/data1/spark/spark-2.4.7-bin-hadoop2.7/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
21/04/02 07:39:06 WARN Utils: Your hostname, tigergraph9001 resolves to a loopback address: 127.0.0.1; using 10.27.20.112 instead (on interface eth0)
21/04/02 07:39:06 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
21/04/02 07:39:07 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
21/04/02 07:39:15 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
21/04/02 07:39:15 WARN Utils: Service 'SparkUI' could not bind on port 4041. Attempting port 4042.
Spark context Web UI available at http://tigergraph9001:4042
Spark context available as 'sc' (master = local[*], app id = local-1617349155305).
Spark session available as 'spark'.
。。。
21/04/02 07:38:21 ERROR ScanEdgeResultIterator: get storage client error,
java.util.NoSuchElementException: Unable to activate object
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:400)
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:277)
at com.vesoft.nebula.client.storage.StorageConnPool.getStorageConnection(StorageConnPool.java:42)
at com.vesoft.nebula.client.storage.scan.ScanEdgeResultIterator.lambda$next$0(ScanEdgeResultIterator.java:79)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Caused by: com.facebook.thrift.transport.TTransportException: java.net.ConnectException: Cannot assign requested address
at com.facebook.thrift.transport.TSocket.open(TSocket.java:204)
at com.vesoft.nebula.client.storage.GraphStorageConnection.open(GraphStorageConnection.java:40)
at com.vesoft.nebula.client.storage.StorageConnPoolFactory.activateObject(StorageConnPoolFactory.java:59)
at com.vesoft.nebula.client.storage.StorageConnPoolFactory.activateObject(StorageConnPoolFactory.java:16)
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:391)
... 8 more
Caused by: java.net.ConnectException: Cannot assign requested address
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:589)
at com.facebook.thrift.transport.TSocket.open(TSocket.java:199)
... 12 more
org.apache.spark.SparkException: Job 0 cancelled as part of cancellation of all jobs
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1925)
at org.apache.spark.scheduler.DAGScheduler.handleJobCancellation(DAGScheduler.scala:1860)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$doCancelAllJobs$1.apply$mcVI$sp(DAGScheduler.scala:852)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$doCancelAllJobs$1.apply(DAGScheduler.scala:852)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$doCancelAllJobs$1.apply(DAGScheduler.scala:852)
at scala.collection.mutable.HashSet.foreach(HashSet.scala:78)
at org.apache.spark.scheduler.DAGScheduler.doCancelAllJobs(DAGScheduler.scala:852)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2118)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2095)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2084)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:759)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2061)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2158)
at org.apache.spark.rdd.RDD$$anonfun$fold$1.apply(RDD.scala:1143)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.RDD.fold(RDD.scala:1137)
at org.apache.spark.graphx.impl.EdgeRDDImpl.count(EdgeRDDImpl.scala:90)
... 65 elided
21/04/02 07:38:21 ERROR ScanEdgeResultIterator: get storage client error,
java.util.NoSuchElementException: Unable to activate object
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:400)
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:277)
at com.vesoft.nebula.client.storage.StorageConnPool.getStorageConnection(StorageConnPool.java:42)
at com.vesoft.nebula.client.storage.scan.ScanEdgeResultIterator.lambda$next$0(ScanEdgeResultIterator.java:79)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)